
In Purity 4.6 a new CLI and REST API function has been released called protection group recovery. This feature allows you to take a protection group that has replicated snapshots and quickly provision its data to a host or cluster for DR or test/dev purposes or whatever.
A continuation of my 4.6 overview post.
This feature is not yet in the GUI, if this is something you’d like to see in it, let us know! I would say that it is likely that we will though.
So whether or not you use the CLI or the REST API to perform this, it works the same. So let’s review the details of how it operates.
In this post I will:
- Review what a protection group is and how our snapshots work
- Explain the feature and the use cases
- Demonstrate how to execute this with the CLI and REST API
- List some frequently asked questions
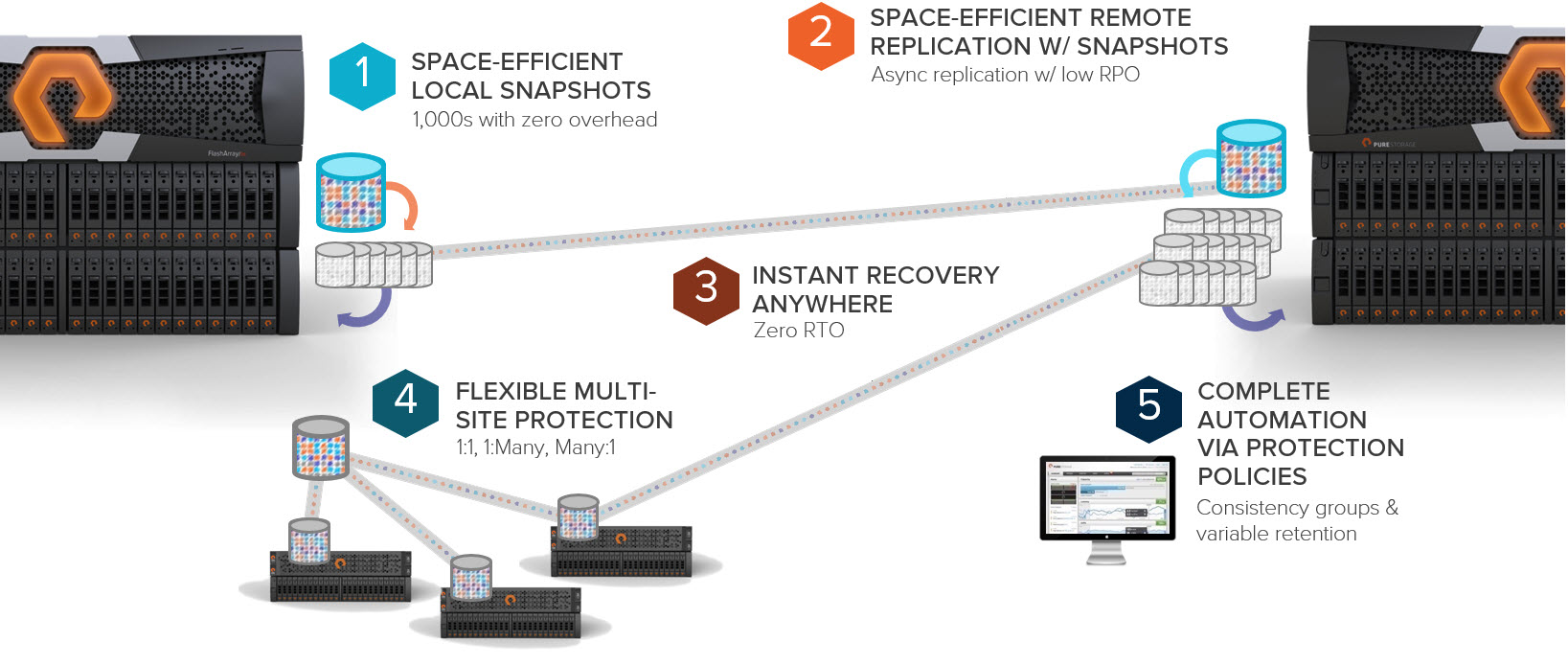
Protection Group Overview
First, let’s quickly review what a protection group is on a FlashArray and how it works.
A protection group is a collection of volumes that have a local snapshot policy, a remote replication policy or both. The snapshots for all of the volumes in the protection group (whether they be local or remote) are created in a write consistent fashion. So a protection group is really a consistency group. A protection group that has a remote replication policy enabled has one or more target FlashArrays that they transmit their snapshots to at a selected interval.
A protection group named “X” on FlashArray “A” that is a source protection group, has volumes in it that exist on FlashArray “A”. On FlashArray “B” which is a target of that protection group “X” has what is referred to as a target protection group which is labeled with the source FlashArray name (in this case would be “A”) then a colon then the name of the source protection group (in this case name “X”). So the target protection group on FlashArray “B” would be called A:X.
A source protection group contains the volumes on the source array and contains the snapshots that are created locally. A source protection group is editable (you can change the schedule, the targets etc). A target protection group lists all of the information (schedule, source array, remotely replicated snapshots) but cannot be edited–you only edit the source of the protection group. You can however, delete and or use the snapshots in the target protection group (the snapshots that have been remotely replicated from the source FlashArray).
So, summary, a source protection group contains the volumes and local snapshots and a target protection group contains the respective remotely replicated snapshots.
In order to use a snapshot (present the data preserved by it to a host in other words) you cannot directly present it to a host. FlashArray snapshots are immutable, part of that means that it cannot be changed, and it cannot be read or written from by a host. It must be “copied” to an actual volume. A snapshot copy process includes Purity taking the metadata associated with that snapshot can copying that metadata to a new or existing volume. This allows you to use the point-in-time data preserved by the snapshot without changing the snapshot originally created. It allows it to be used multiple times until you actually delete the snapshot.
Okay. Enough history. What is protection group recovery?
Protection Group Recovery
Protection group recovery is an automated workflow to copy all of the snapshots in a protection group to a set of volumes. A protection group recovery takes a given snapshot of the protection group and copies them to respective volumes in one command. If the volumes exist, they can be overwritten, if they do not, they are created.
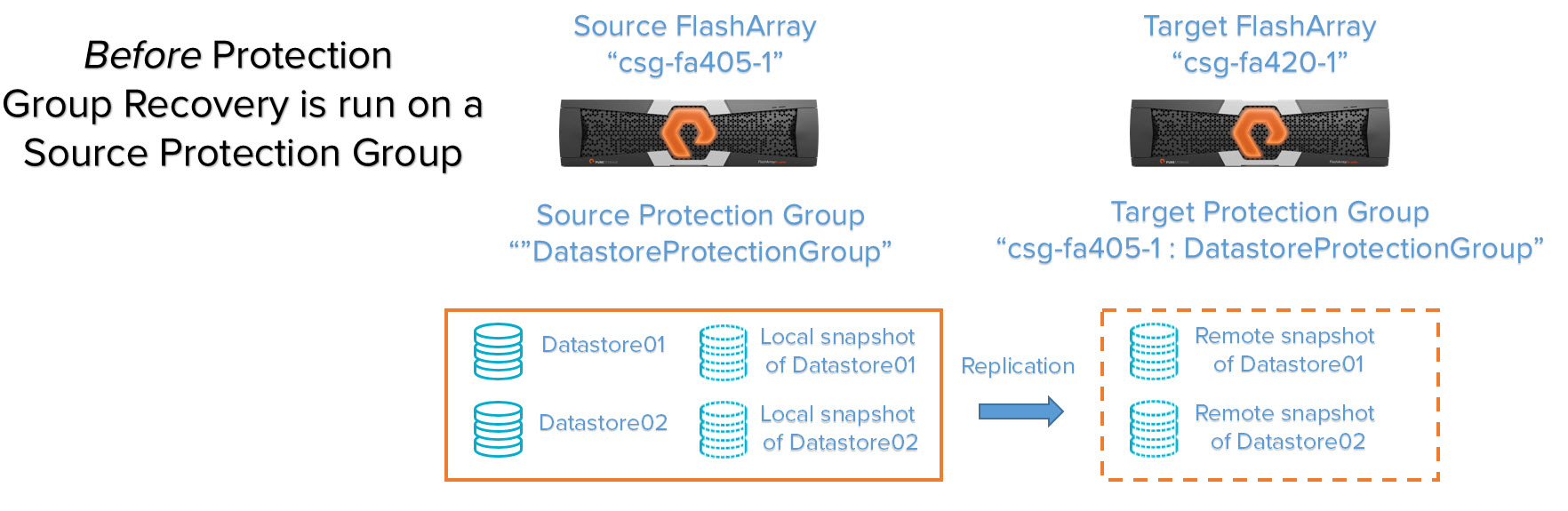
If you are restoring from a target protection group (meaning restoring volumes on FlashArray B that have been remotely replicated from FlashArray A to FlashArray B) it will create a new source protection group on FlashArray B with the restored volumes. If it already exists, it will just refresh the volumes with the latest snapshots. Let’s look at some scenarios:
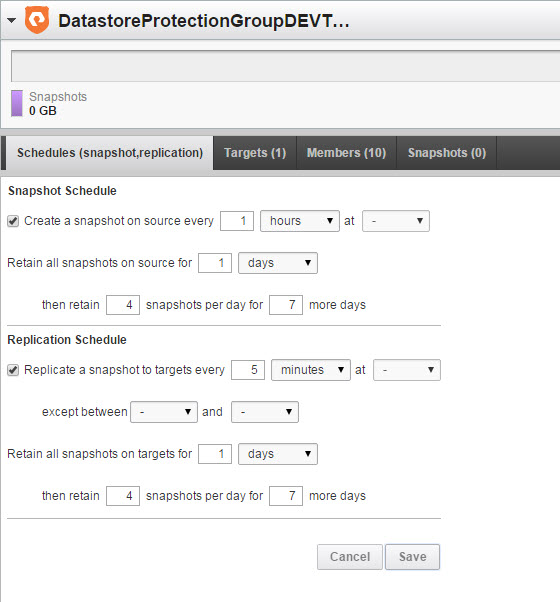
Case 1: Refresh local volumes in a source protection group
You have a source protection group with one or more volumes and you want to restore all of the volumes with the latest local snapshot in that protection group. Running this operation will take a specified respective snapshot for each volume in the protection group and overwrite it with the point-in-time metadata of that snapshot.
Now we run protection group recovery on the source protection group named “DatastoreProtectionGroup”.
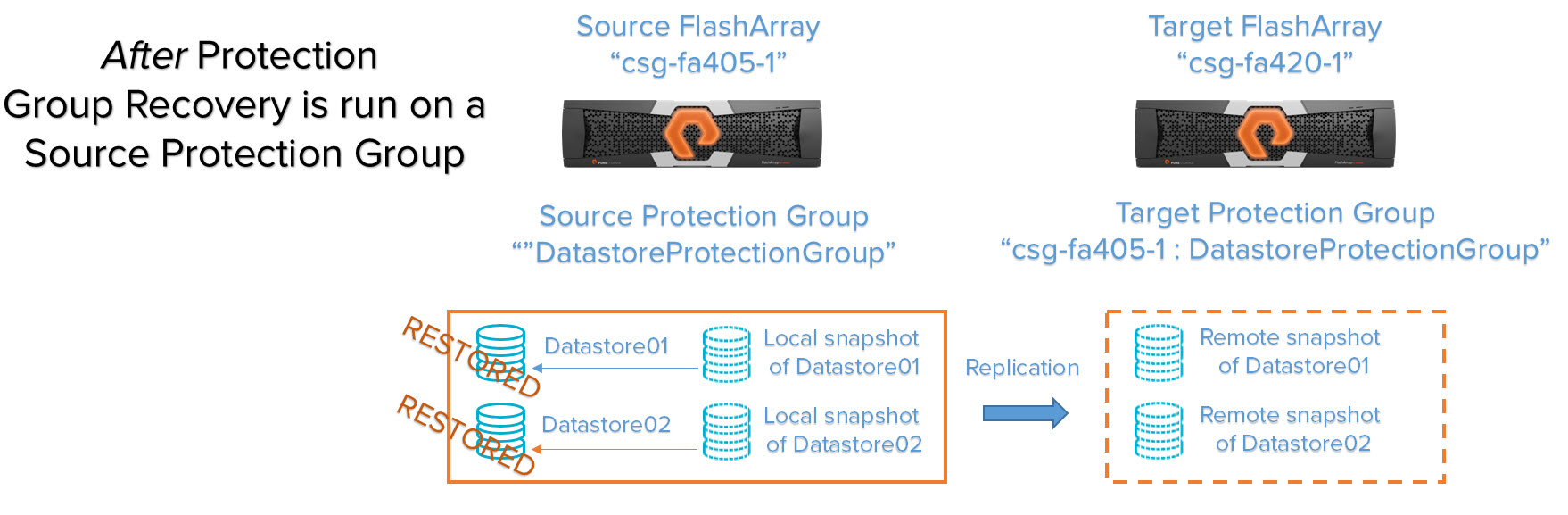
The volumes in the protection group are restored back to the last snapshot.
Case 2: Create new recovery volumes from snapshots in a target protection group
You have a target protection group on a target FlashArray and you want to recover the data on those snapshots for either DR or test/dev purposes. Running a protection group recovery will create new volumes on the target array as well as a protection group with identical configuration. The protection group will be created with the same local and/or remote protection policy that replicates back to the original source array. Those volumes will be added to the new protection policy. Those new volumes will also be populated with the point-in-time metadata (therefore the actual data) of the respective remotely replicated snapshots.
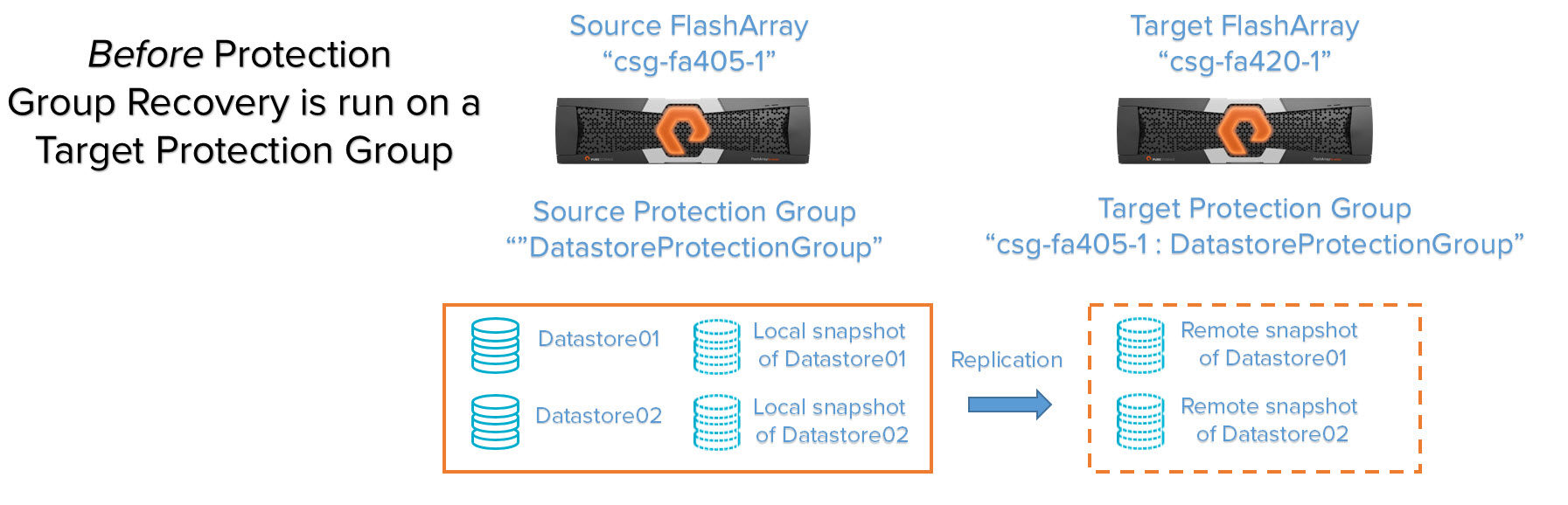
We run a protection group recovery on the target protection group “csg-fa405-1:DatastoreProtectionGroup”.
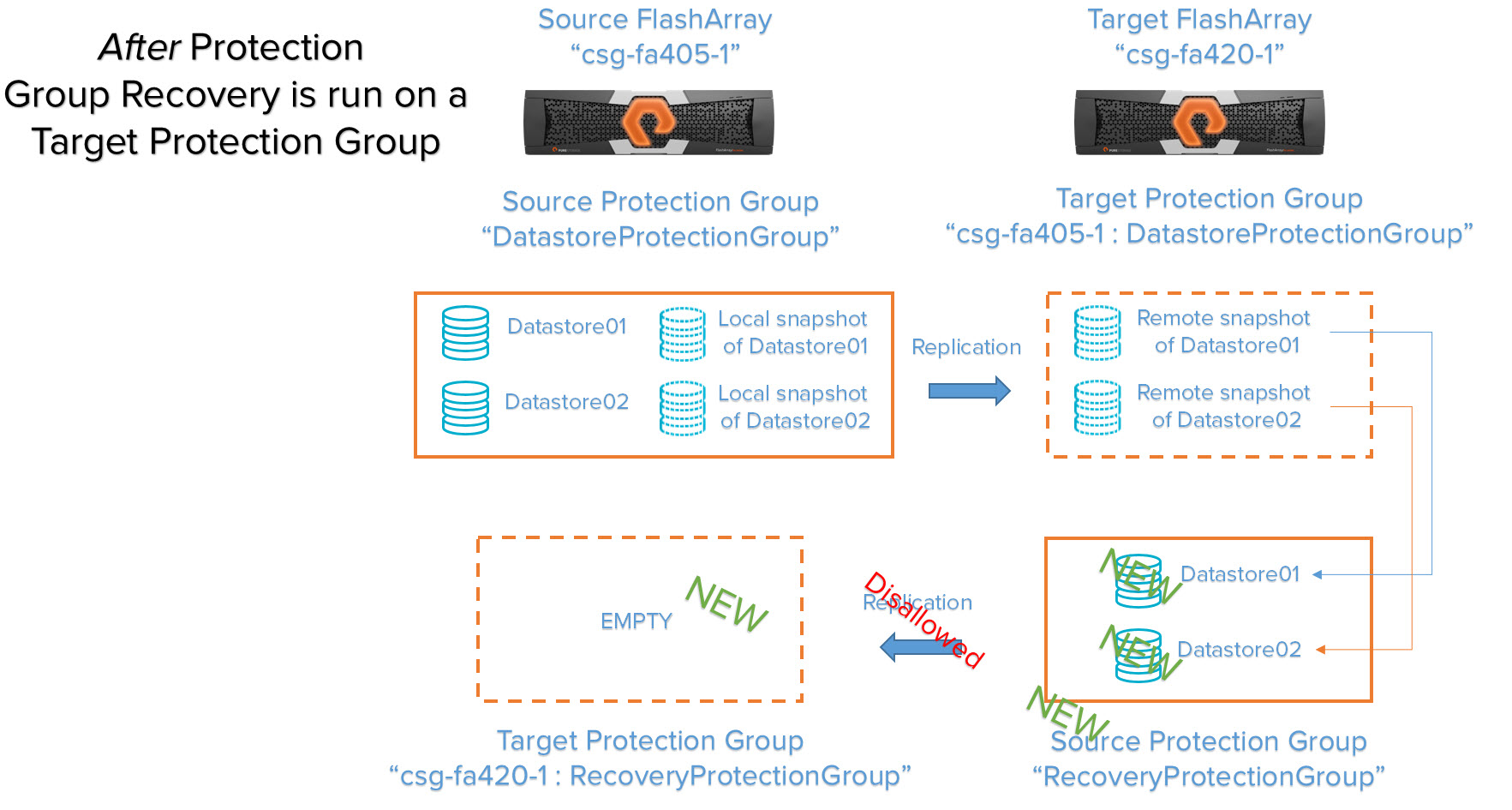
The volumes are created from each of the specified snapshots, a new source and target protection group is created and those volumes are put in the new source protection group. The new protection group has the same local and remote snapshot schedule and retention policy, but they are not enabled by default so no remote or local snapshot will be created.
Case 3: Refresh recovery volumes from snapshots in a target protection group
A target protection group “X” exists on FlashArray “B” and so does a respective source protection group “Y” that replicates back to the original source FlashArray “A”. Running a protection group recovery will refresh the volumes in the protection group “Y” with the metadata (and therefore the data) of the latest snapshots in the protection group “X”.
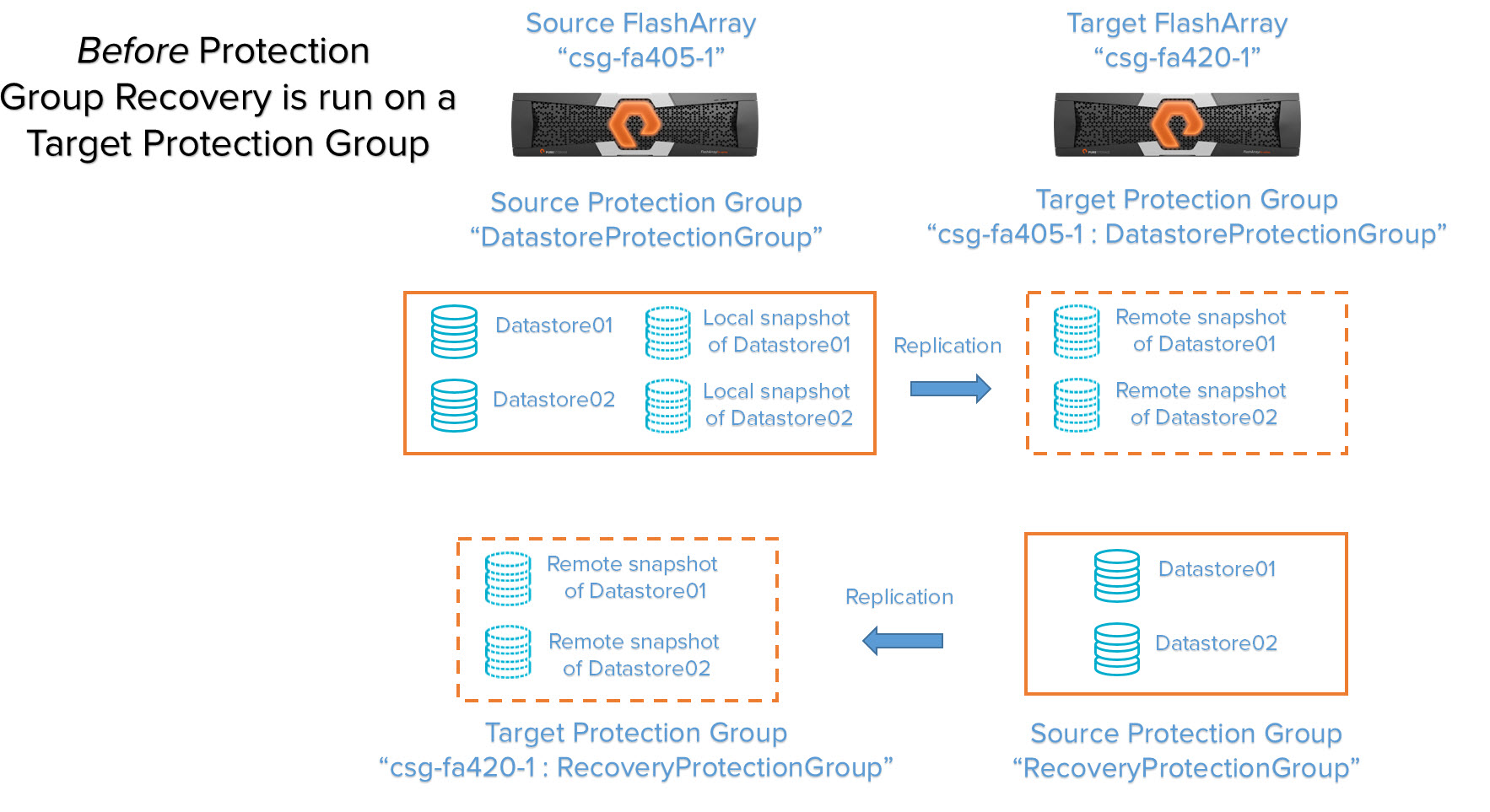
We run a protection group recovery on the target protection group “csg-fa405-1:DatastoreProtectionGroup”.
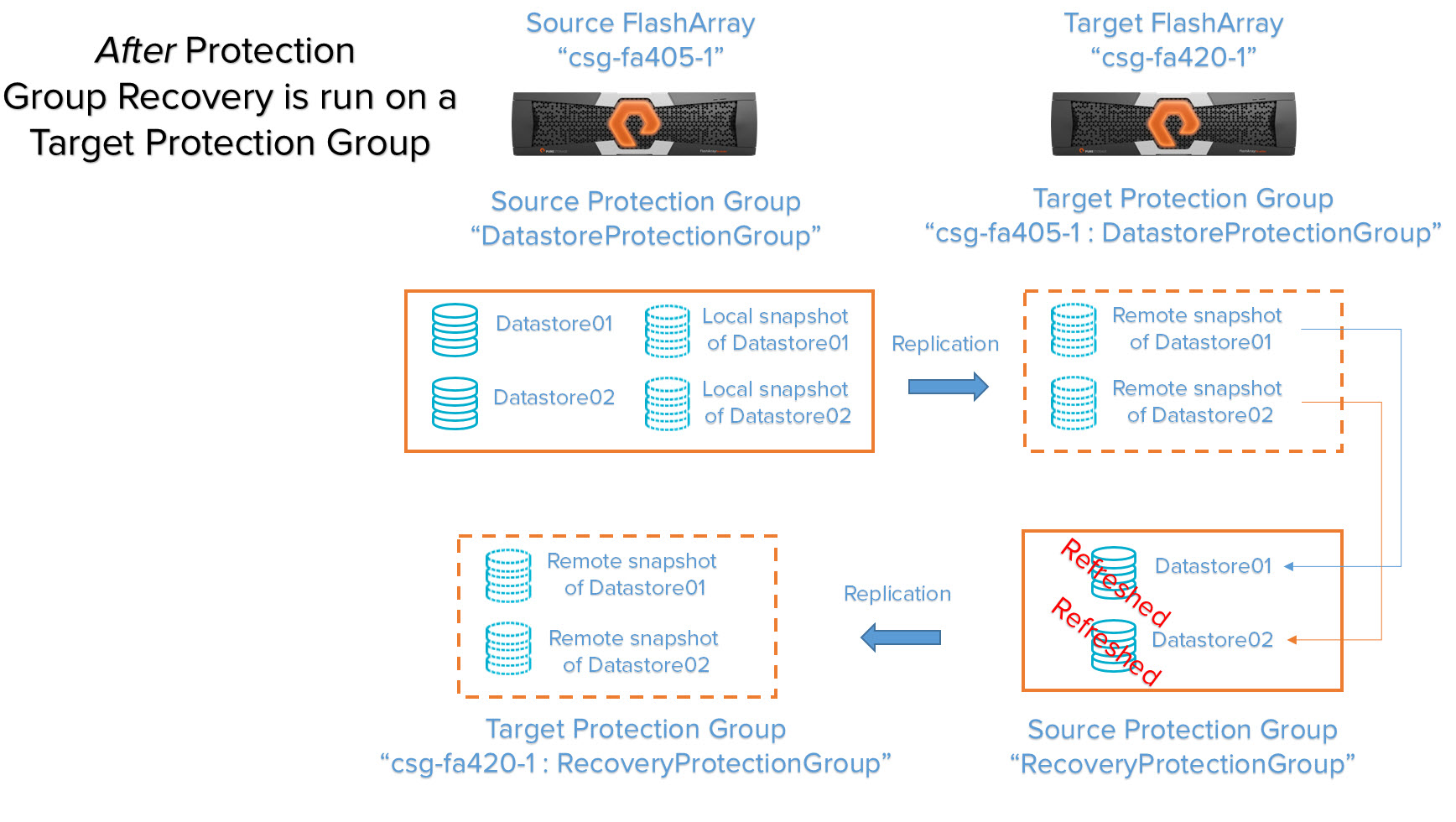
Nothing new is created, but the volumes in the protection group “RecoveryProtectionGroup” are refreshed with the data of the specified respective snapshots in the original target protection group named “csg-fa405-1:DatastoreProtectionGroup”.
Let’s run through actually doing this. As I mentioned, this is not in the GUI, only in the REST API and CLI. This is something that will likely be in the GUI at some point I imagine. Let’s start with the CLI.
Using the FlashArray CLI to run Protection Group Recovery
First, SSH into the FlashArray:
Now identify the name of protection group you want. If you are restoring volumes from a source protection group the name will just be the standard name. If it is a target protection group (replicated from a source FlashArray) it will be named with the prefix of the source array.
purepgroup list
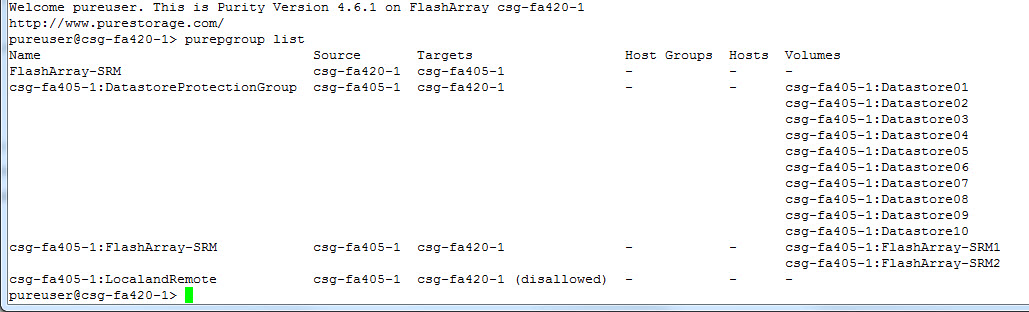
I am going to use a target protection group called csg-fa405-1:DatastoreProtectionGroup. Running the command will create a new volume for each snapshot (the latest point-in-time) and put them in a new protection group.
The syntax is:
purepgroup copy <existing Protection group name/pgroup snapshot> <new protection group>
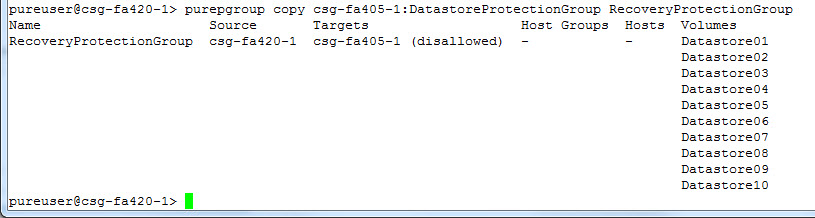
So you can either enter a protection group name which will use the latest snapshot or you can enter a specific snapshot if you want an older point-in-time.
You need to indicate the name of the new protection group to hold the new volumes (I used the name “RecoveryProtectionGroup”. When run, there will be a new source protection group with the same local and/or remote snapshot policy as the original one. The difference is that the local and/or remote polices of the new protection group will not be enabled. You can then go enable them if you so choose.
When recovering from a protection group and the protection group that you want to recover to already exists, you need to add the –overwrite parameter. This allows you to overwrite volumes in the destination protection group that have the same name as the volumes in the protection group you are recovering from. Without the overwrite parameter, the recovery operation command fails if any volume name collisions are found. When the overwrite parameter is present, both the “recover from” protection group and the “recover to” protection group must contain exactly the same volumes (in number and in volume names), otherwise the entire copy command fails.
Using the FlashArray REST API to run Protection Group Recovery
Just like the CLI which you can run with anything that can create SSH sessions, the REST API can be leveraged by anything that can make REST calls. I am going to use the Chrome REST Client, the interface is a bit different, but the general idea is the same. See this blog post for more information on the Chrome REST Client.
So first authenticate your REST session. The below screenshot shows that I have a new session.
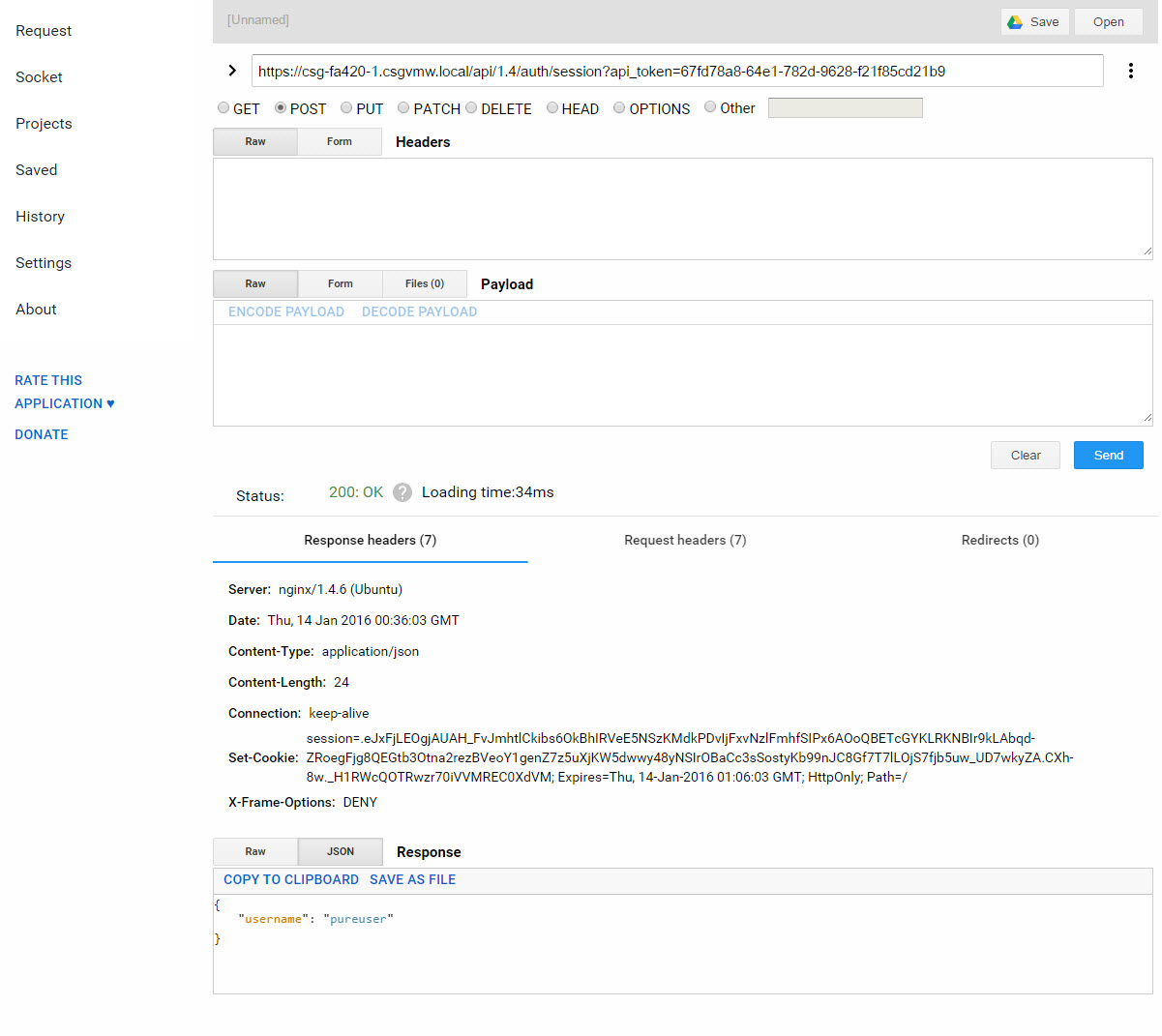
The REST API call to run a protection group recovery is a POST command in the 1.5 release of the REST API. The URL request will be in the syntax of:
https://<array name or IP>/api/1.5/<new protection group name>
So mine looks like:
https://csg-fa420-1.csgvmw.local/api/1.5/pgroup/RecoveryProtectionGroup
I will create a new protection group named “RecoveryProtectionGroup”. If you are overwriting a protection group, it would just be the name of the the protection group you want to overwrite.
Also, you need to provide the content. There are two options. One is the name of the protection group (or specific protection group snapshot) you want to recover from. This should be in a JSON format (the FlashArray REST API takes information in as JSON and returns it in JSON formatting). This parameter name is simply “source”. The other parameter, overwrite, is optional (refer to the bottom of the CLI section just earlier in this post for the overwrite explanation).
The content-type is in the JSON format so my content would look like:
{"source":"csg-fa405-1:DatastoreProtectionGroup"}
My URL and content request:
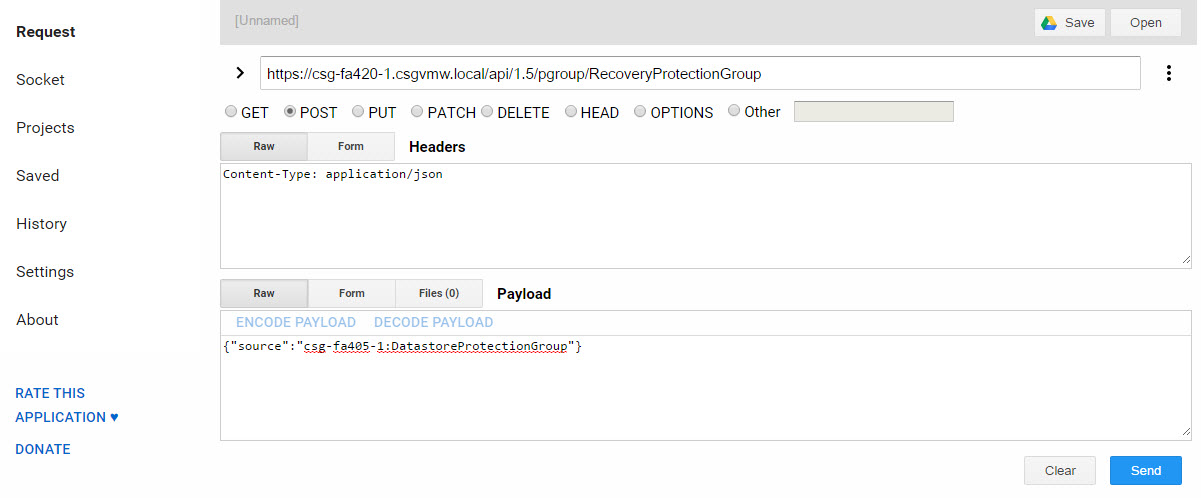
The REST response, showing the new protection group and volumes.

If I wanted to overwrite, I would make the JSON content like below instead:
{"source":"csg-fa405-1:DatastoreProtectionGroup", "overwrite":true}
Frequently Asked Questions:
Q: If I want to restore pre-existing volumes but I have renamed them from the original names will the restore work?
A: No. All of the restore target volumes need to be the same name as their respective restore source volumes.
Q: If I restore to new volumes then resize the new volumes will a subsequent overwrite-restore fail?
A: No, the volumes will be resized back to the original size when the snapshot was created.
Q: When a new protection group is created during the restore process, will the local and or snapshot policy be copied from the original?
A: Somewhat. The snapshot interval for local or remote snapshots (and a blackout period if chosen) will be copied. The retention policies will not–these will be at the default for the new protection group.
Q: If the “restore-to” protection group already exists and has a different protection policy then the source will the operation fail?
A: No. If the protection group already exists its protection policies will remain at whatever they are configured and will not be overridden.
Q: If a “restore-to” protection group has more volumes than the “restore-from” group will the operation succeed?
A: No. It must have the same number of volumes with the same names.
Q: If the “restore-to” protection group already exists and has a different target array or more than one, will the operation fail?
A: No, the “restore-to” protection group will remain as configured. As long as the other parameters are fine (correct number of volumes and names), the operation will succeed.
Q: When a new protection group is created will it automatically start creating local snapshots and/or remotely replicated snapshots?
A: No. The local protection policy and remote replication policy are disabled by default.
Q: If a remote snapshot has not been completely replicated and I want to restore from it, will the operation wait or will it fail?
A: There must be a completed remote snapshot to recover on a target FlashArray. Otherwise the operation will fail.
Q: If my protection group uses hosts or host groups will restores from it work?
A: Depends. You cannot do a local restore (restore volumes in a source protection group with the local snapshots in that protection group). But you can restore from a target protection group (remotely replicated snapshots to new volumes in a different protection group).
Summary
This is a new CLI and REST and we are looking at adding more functionality to it. Technically what it does is not really new, it can all be done with CLI and REST earlier, but this just automates a lot of the steps it would have previously required. We are looking at doing a lot like this with our REST to ease in scripting and automation, so if you have comments, requests etc please let me know!
nice post Cody !
I would be very interested in having this feature set in your GUI. As well as enriching it with a “HA mode” that could offer an option to also replicate host/host group mapping, so to be able to quickly recover (for HA purpose only) volume on all exact same hosts as on source array.
Nice Post with great explanations..
Does this support creating local copies.
Create new recovery volumes from snapshots in a local protection group
Thank you! No unfortunately today it will only refresh the volumes in a protection group, not copy them to new volumes. For that you need to use individual commands/API calls.
Hi Cody,
Using the api to copy snapshots to an existing protection group using the POST pgroup option (the Python create_pgroup) fails if the volumes in the protection group are presented to hosts, with error [{“pure_err_key”: “err.friendly”, “code”: 0, “ctx”: “mypgroup”, “pure_err_code”: 1, “msg”: “Destination pgroup cannot be overwritten. It contains connected volumes.”}].
I can confirm the same process works if the LUNs are not presented to hosts.
We’re trying to achieve basic DR–we want to copy remotely replicated snapshots to volumes currently presented to DR hosts.
I opened a case with support and they suggested i contact you here. I’m using api v1.8.
Support provided a note from the Best Practices doc suggesting removing the volumes from the host first. Is that the only way forward?
Yeah this is a limitation of the pgroup copy mechanism. We are looking at improving this moving forward. So if you want to use this, yeah you need to remove the volumes from the hosts. Otherwise, I would just use a loop and build it yourself via the API and use the individual calls–this is generally what I do because there is a lot more flexibility in that.
fair enough Cody, thanks for the confirmation. also very helpful article too btw.
best,
Sure thing! You’re welcome! Sorry there isn’t a better answer for now. I will keep an eye on this if we end up enhancing this call and will update as needed.
Hello. We are just beginning to replicate data from a local array to a remote array. Obviously everything can be done in the GUI, but unfortunately you cannot take a GUI to a Change Control meeting.
We have already established communication between the arrays. Is there a guide or doc that shows the CLI version of the GUI commands to set up new Protection Groups and replicate them to a target array? This set of commands would be something we would incorporate in our own documentation showing our Storage Admins the commands to implement a new Protection Group upon request as well as create a usable copy on the target array for Disaster Recovery testing. Any direction would be appreciated!