
We just released our latest version of our Storage Replication Adapter, version 4.0 for VMware Site Recovery Manager. There are a lot of enhancements in this release and improvements–if you are on 3.1 (or certainly earlier) I recommend an upgrade when you get a chance.
For all the need-to-know information (release notes, user guide, videos, download link, etc.) see here:
The 4.0 release mainly is focused on support for ActiveDR which I went into detail on here:
ActiveDR is fairly well designed with what SRM has in mind when it comes to disaster recovery–the concepts of non-disruptive test recovery and full recovery are built into both. ActiveDR is designed to use pods on the FlashArray–a pod is a portable namespace that can be (and all of its objects) be moved to other arrays. A pod can also be linked to a remote pod on a different array via an asynchronous connection. This configuration of two linked pods is called ActiveDR. I won’t go into much more detail on ActiveDR itself (I do it in the link above) but lets focus on the ActiveDR SRM specifics.
See details on installing the SRA and configuring the array manager here:
Discovery
In SRM, devices are found via inquiring through the SRA for storage that is actually replicated. The SRA looks for storage that is replicated between enabled array pairs:
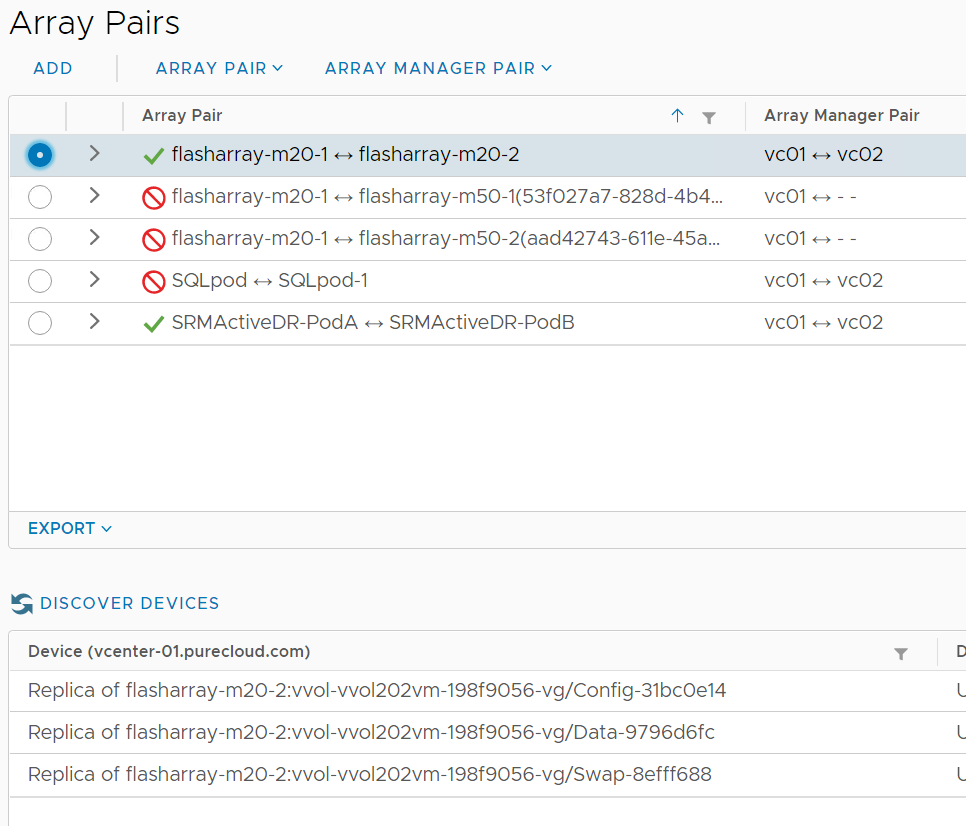
The SRA returns all valid volumes and SRM then sorts through them to find out if they are in use as VMFS datastores or RDMs (vVols work much differently).
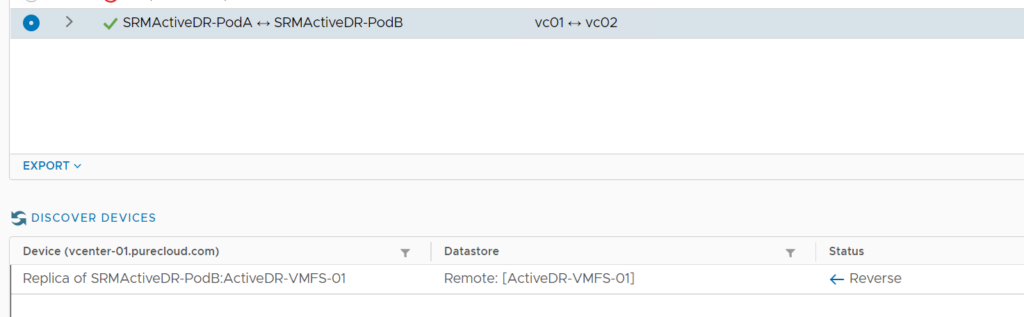
In an ActiveDR world, the “array pair” is actually a pod pair, the you enable the ActiveDR pod pair directly as you would a physical array pair.
You will also note (that unlike our periodic/snapshot type replication) we also advertise the pod as the consistency group for all volumes:
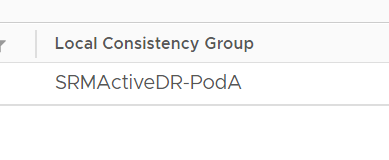
This enforces SRM to group all volumes in the pod together and fail them over in unison. Since a failover is executed at the pod level–everything in it is failed over. This ensures that you don’t accidentally leave out a volume when creating SRM protection groups.
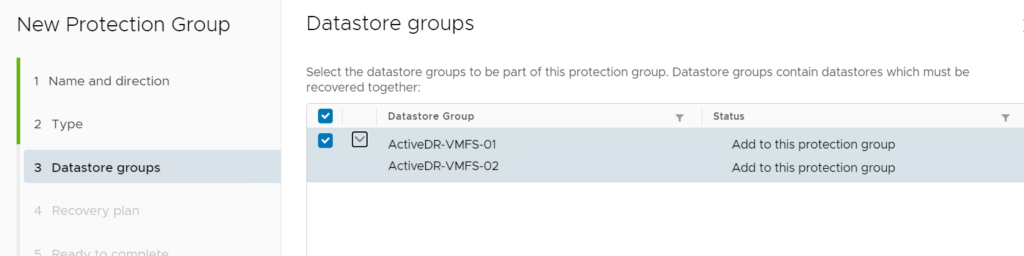
As of the SRA 4.0 we do not support non-VMware volumes in an ActiveDR pod–so all volumes in the pod must either be VMFS datastores or RDMs. Supporting non-VMware volumes in the pod is a future feature.
See setup of Active DR from scratch for SRM here:
Synchronization
In ActiveDR, there is no such thing as a synchronization–the source pod is always sending data as fast as it can.
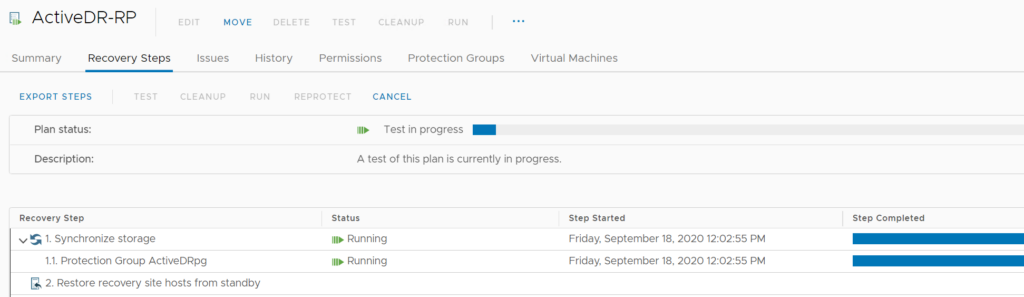
So is this step in the test recovery or recovery a non-operation. Not quite. Instead we record the timestamp of the request, and check to see if the target side recovery point is equal to or later than that time stamp.
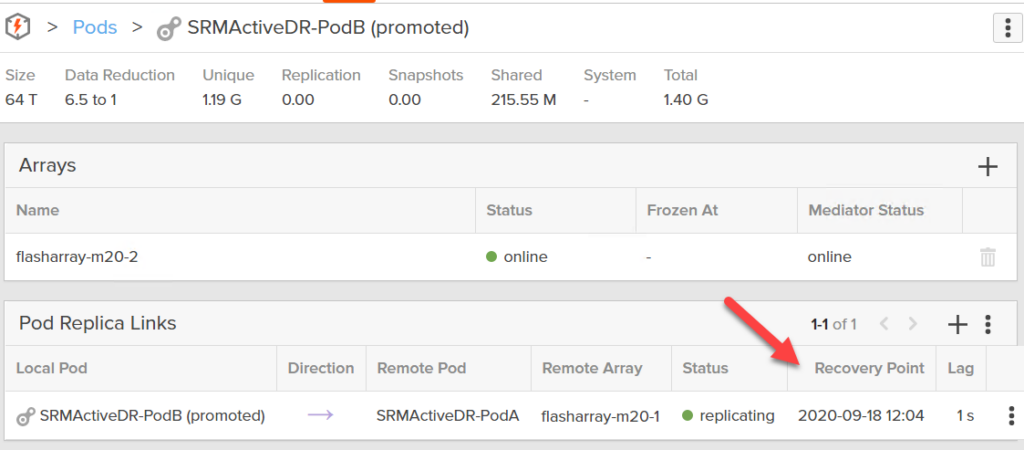
If it is, we return success. If it is behind, we wait until it is synchronized.
Test Recovery
For a demo of a test recovery see this video:
In a test recovery, the target ActiveDR pod is promoted, the volumes are connected to the right hosts and the VMs are recovered. During a cleanup, the pod is demoted, the volumes are disconnected, and the undo pod (created from demotion) is eradicated (unless safe mode is enabled, then the eradication is dealt with by the eradication timer).
During the test the volumes will be tagged with temporary tags saying the test recovery (in other words the promotion) was caused by the SRA. This allows the SRA to know it made this operation occur and allows it to pick up at the right spot in the case of failure.

These tags get removed during cleanup. One of the great things about this procedure with ActiveDR, is that you cannot only test your DR, but also configuration changes. When the test comes up, assign QoS limits for instance, or make storage changes (add storage to VMs, resize etc) and see if it works in your environment. The test side will be cleaned up removing the changes made by the tests. If the test works, then add that configuration to the source volumes and configuration changes (QoS values etc) will be propagated to the target via the replication.
Recovery
Recovery is very similar to test recovery. The difference is the source side is brought down. The steps are:
- Disconnect the source volumes
- Demote the pod with the quiesce option. This ensures that any lingering data is sent to site B.
- Once quiesced, promote the target pod. This reverses the replication too–if the source is demoted and you promote the source, this is considered a failover and replication automatically reverses.
- Tag the volumes as in a failover state. This allows the SRA to know it made this promotion.
- Connect the target volumes.
If there is a DR event, and the demotion of the source cannot happen, the target will be promoted without any changes to the source. If the source comes back online, and you rerun recovery, the SRA will see the volumes have been tagged, so it knows that it failed over (promoted the target already) and it will demote the source pod without quiesce (meaning any changes since recovery on the source side will be discarded). Once the source is demoted, the replication will automatically reverse.
See a video for the process here:
Reprotect
A reprotect doesn’t do too much. The replication is already reversed at this point. So it just ensures that the data is replication and caught up and also removes the recovery tags. Makes it ready to recover again!
See the above video at the end for that process.
If we’re using SRM with vVols on Pure now, would ActiveDR allow us to continue with this approach and stick with vVols? Can there be more than one pod for grouping different sets of VMs?
Glen, ActiveDR + vVols is not yet supported. To enable AC or ADR with vVols we need to add support for vVols in pod which we are making progress on. Though for today, pgroups is still the replication answer when it comes to vVols