
From my armchair in the past few weeks, I have been watching the myriad of announcements at re:Invent by AWS and a few things caught my eye (well a lot of things did, but a few in particular to storage).
The first thing to note was the change in the consistency model in S3. Up until now, consistency was “eventual” within S3 for certain operations like changes to a file, and there are a ton of posts that do a great job of explaining this. One is below:
Google “S3 eventual consistency” and you will find tons of examples.
At a high level, when modifying or deleting objects the change may not be immediately reflected. So on an immediate subsequent read, you may not get what you wrote. For busy environments with high change rates/modifications this could lead to corruption. So you needed to understand the behavior and build to or around it.
At re:Invent, AWS announced that strong consistency is now supported for S3 operations:
https://aws.amazon.com/blogs/aws/amazon-s3-update-strong-read-after-write-consistency/
https://aws.amazon.com/s3/consistency/
What you write is what you get. Fantastic!
So what does this have to do with Cloud Block Store? Read on.
The Promise of Cloud Block Store
I wrote a post on Cloud Block Store about what I thought the potential was:
The TLDR; of that post concerns is as follows: Why does a customer buy Pure on-premises? Well fundamentally they don’t want to understand/deal with/ handle on-premises storage mediums directly. Should I know how to handle flash, make it performant, resilient, efficient, etc. How do I copy/protect my data?
Customers pay our engineers to figure that stuff out so they don’t have to. To make it simple. Fast. Efficient. Reliable. And the features on top of it.
We follow the latest and greatest storage technologies, figure out if we should use it (does it make our product better?) and then how to best use it.
The customer just continues on using our product as they always have. They benefit from our focus. No re-architecting of applications or infrastructure just because some better medium (or whatever) is introduced. We update our backend, with no change in how a customer directly consumes (manages it, or reads/writes) our storage platform.
So taking this back to public cloud. Similar to on-premises the public cloud has a myriad of storage options. The cloud providers have a significant number of storage options: block, object, file. Within those options are tons of flavors, varying in resiliency, performance, and cost, to name a few. And they all come with their own best practices in implementation and variations in provisioning.
And it certainly isn’t stopping.
So like on-premises, our engineering team is consistently evaluating new cloud storage features, and examining them to see if we should change the backend of Cloud Block Store to take advantage of said features. Does this new feature make our offering faster, more efficient, cheaper, more resilient. And if so, we work to implement it into Cloud Block Store. The frontend though doesn’t change. Same APIs, same provisioning, just better.
Back to S3
Looking back at the S3 change, what does this have to do with Cloud Block Store. Well a few things. First, we understood the problem of eventual consistency, so we designed for it. Cloud Block Store uses a combination of S3 (for persistence) and IO1 for NVRAM, and instance store for the data we pull from S3 in active CBS instances. To solve for the S3 consistency behavior, we leverage DynamoDB to put essentially a version number on each object so we know what is the latest.
With the introduction of S3 strong consistency, we likely, do not need this any more. We of course need to test and understand the consequences of this switch but our engineering team is digging in. This change in S3 might make our product better (less parts running). With no change to customers actually using our product.
The point here is that AWS improving their product can improve our product. Our customers don’t need to care about it–we do. We can incorporate that change without affecting the customer at all. They keep consuming our product as always.
What about an example more to the point? Well think about I01 versus I02. GP2 vs GP3.
Table from AWS documentation
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ebs-volume-types.html
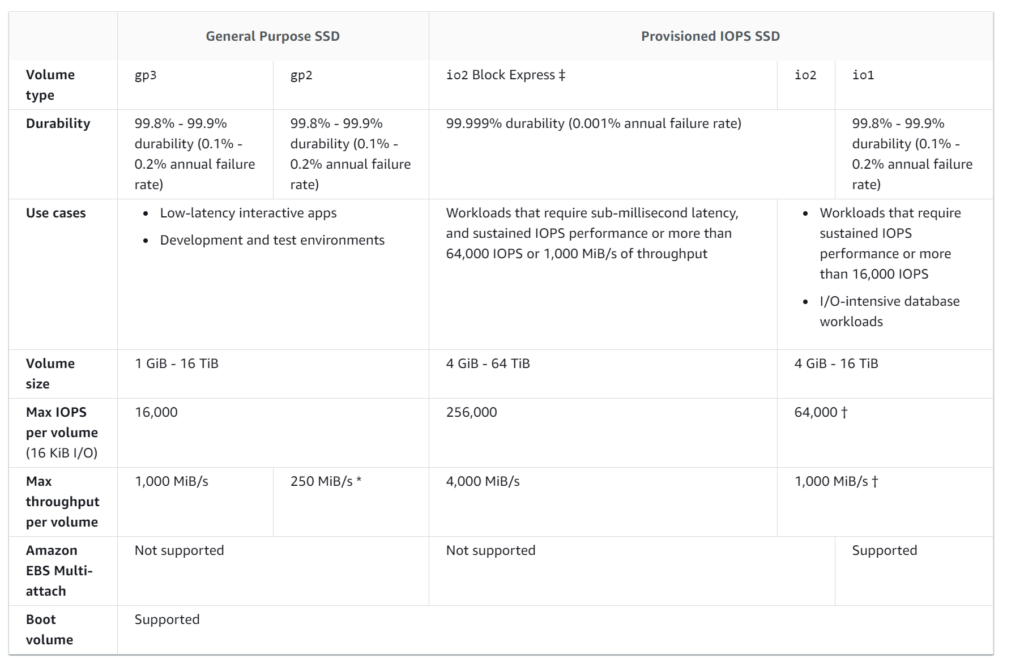
GP3 was announced this year too.
Different profiles of performance, cost and features. Multi-host attach etc.
A lot of these are no-brainers to upgrade to. I01 and I02 are the same price but I02 has better resiliency. Do you just use it for new apps? Or migrate the old ones too? What if you need more performance? Do you look at the io2 express? But do you need multi-attach? Do the volumes need to be very large? Greater than 64 TB? How do snapshots work on them? If we used more volumes to stripe for performance, how do snapshots work then? Are the write consistent? Do you need replication? etc.
On Cloud Block Store, we can grow volumes to PBs in size if needed, and every volume has the same performance and resiliency–it comes down to the performance and resiliency of CBS. Which we will continually improve. All volumes can be snapshotted instantly and restored instantly from those snapshots. They can be connected to many, many hosts.
We’ve looked at I01 and I02 and even the new GP3 volumes. Do they have a place in CBS? I02 looks like it does, GP3 currently doesn’t. No advantage there yet. But we look at these new offerings and re-look at them and then look back at our original design. Did we design this behavior because this new object didn’t exist? If it did exist, would we change our design? If so, should we now?
And I’ve only spoken about a few things in AWS. AWS is not the only cloud. Azure. Baremetal. On-Premises. VMware. Those have their own options. We can run in those worlds too.
And I am not just talking about moving applications between clouds (though CBS can help with that), which I think is less common, but instead common delivery models to different clouds. Each cloud has different native storage, with different design principles, with different best practices. Do you force applications owners to understand them all? Do you force only certain options? Do you have design reviews on the various choices to make the best decision in the right cloud? Does that hold back innovation?
Maybe! Maybe not. Decide where you want to focus your efforts, what is a valuable thing for your company to focus its IT prowess on. Are storage decisions minutia part of that? Scale matters too. If you have a few EC2 instances and a 9 node k8s cluster, probably are okay with what you have. But as these things get larger, sometimes you need to bring in the experts. This is what we do. Storage. We work in those clouds. We work to remove tradeoffs through engineering in our product.
These cloud providers are only going to introduce more stuff, more features, more improvements, and well, more decisions. My argument here is that we can be the storage experts for you. Let us worry about, what we have built a business worrying about.
Let’s partner in the cloud!
Gartner agrees that we know what we are doing 🙂
https://www.gartner.com/doc/reprints?id=1-24PF3N7Q&ct=201201&st=sb