Hello- Nelson Elam here. I wanted to go over the reasons why I think you should enable automatic directory management (autodir) if you are planning to use NFS datastores on FA File. A quick note before we get started- autodir is not restricted to ESXi hosts but ESXi hosts will be the focus of this blog.
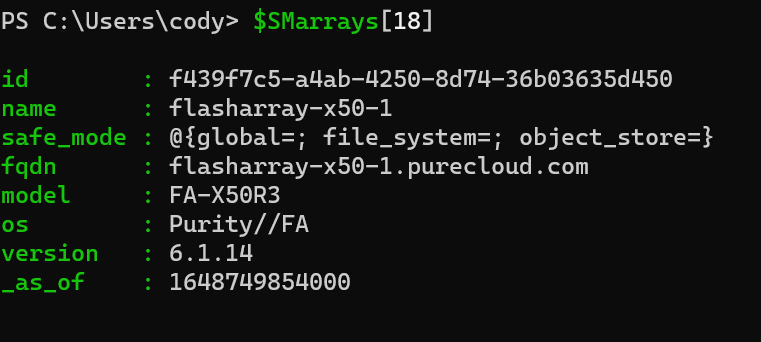
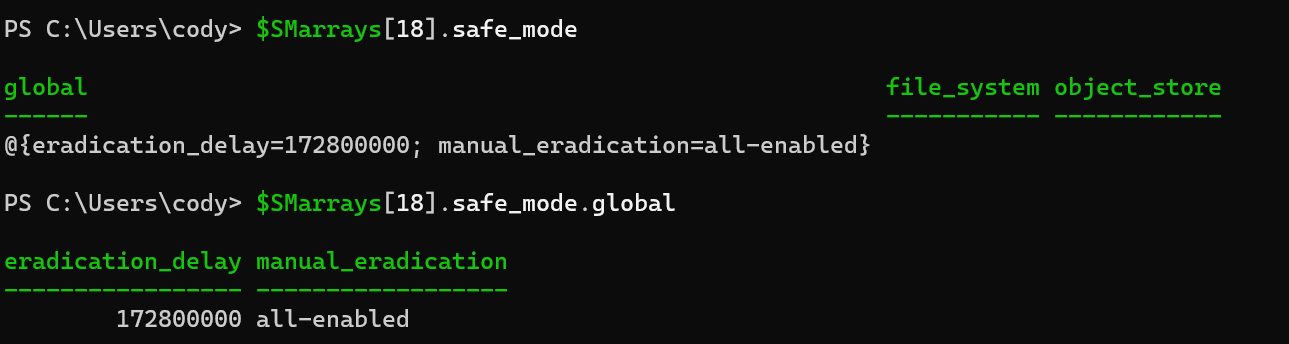
What is autodir? Autodir is a way for FlashArray to reflect the current directory structure on an NFS datastore that’s managed by a connected host- a managed directory. What does this mean for ESXi? Whenever a VM gets created on an NFS datastore, a new directory (folder) gets created for the VM on the datastore. When a VM gets deleted from disk, the directory gets destroyed. Note that directories you create or destroy manually on an NFS datastore in vCenter get reflected in FlashArray as well. Simple enough!
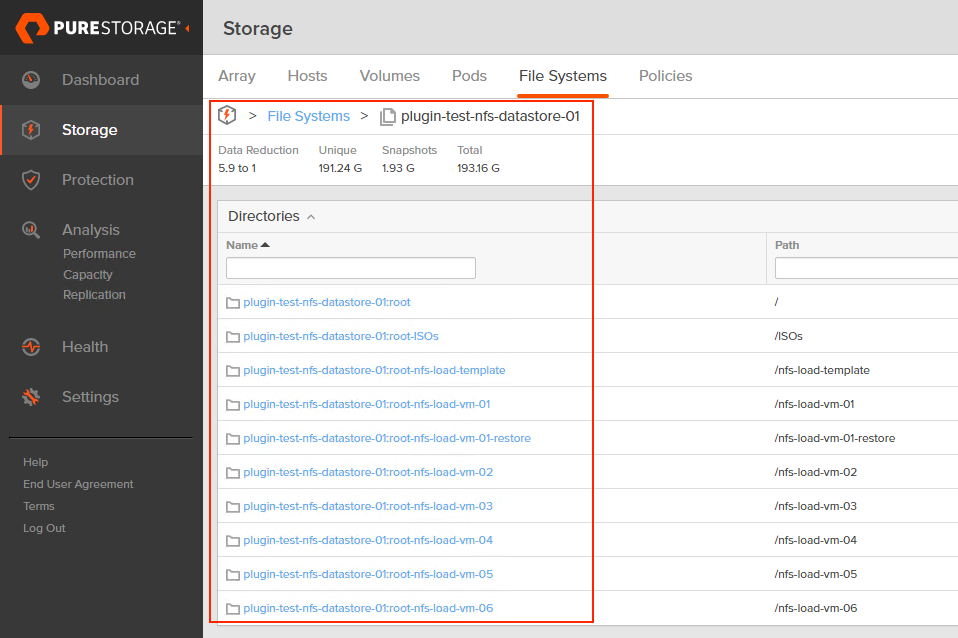
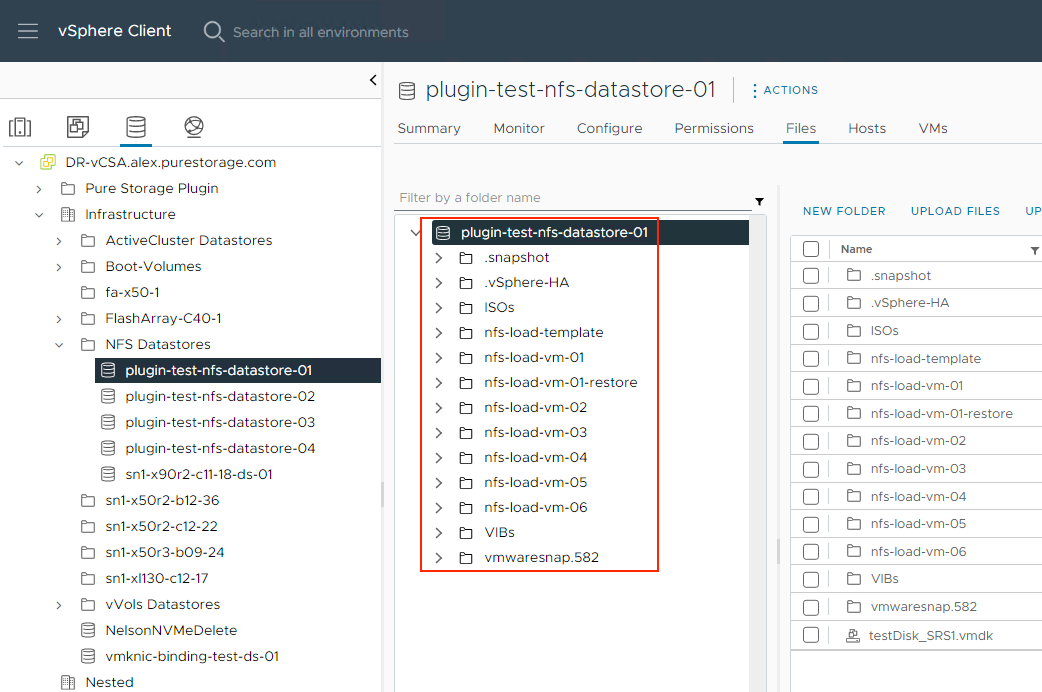
If you’ve read the FA File launch blogs or have seen some of the webinars we’ve done about FA File or NFS datastores, you’ve likely seen or heard us talk about VM granular management being part of FA File. Autodir enables VM granular management. Let’s dive into VM granular management in the context of NFS datastores.
With autodir enabled, these changes are reflected on FlashArray and enable FlashArray administrators to be able to see the current state of the NFS file system from a directory perspective.
Want to figure out why the data reduction ratio of a file system dropped so significantly? Now you can see that at a per-VM basis on FlashArray.
Want to see which VMs are spiking in load at inopportune times? You can use the FlashArray GUI to help figure that out. Worth mentioning this info is more easily consumed in Pure1 when using the VM analytics collector.
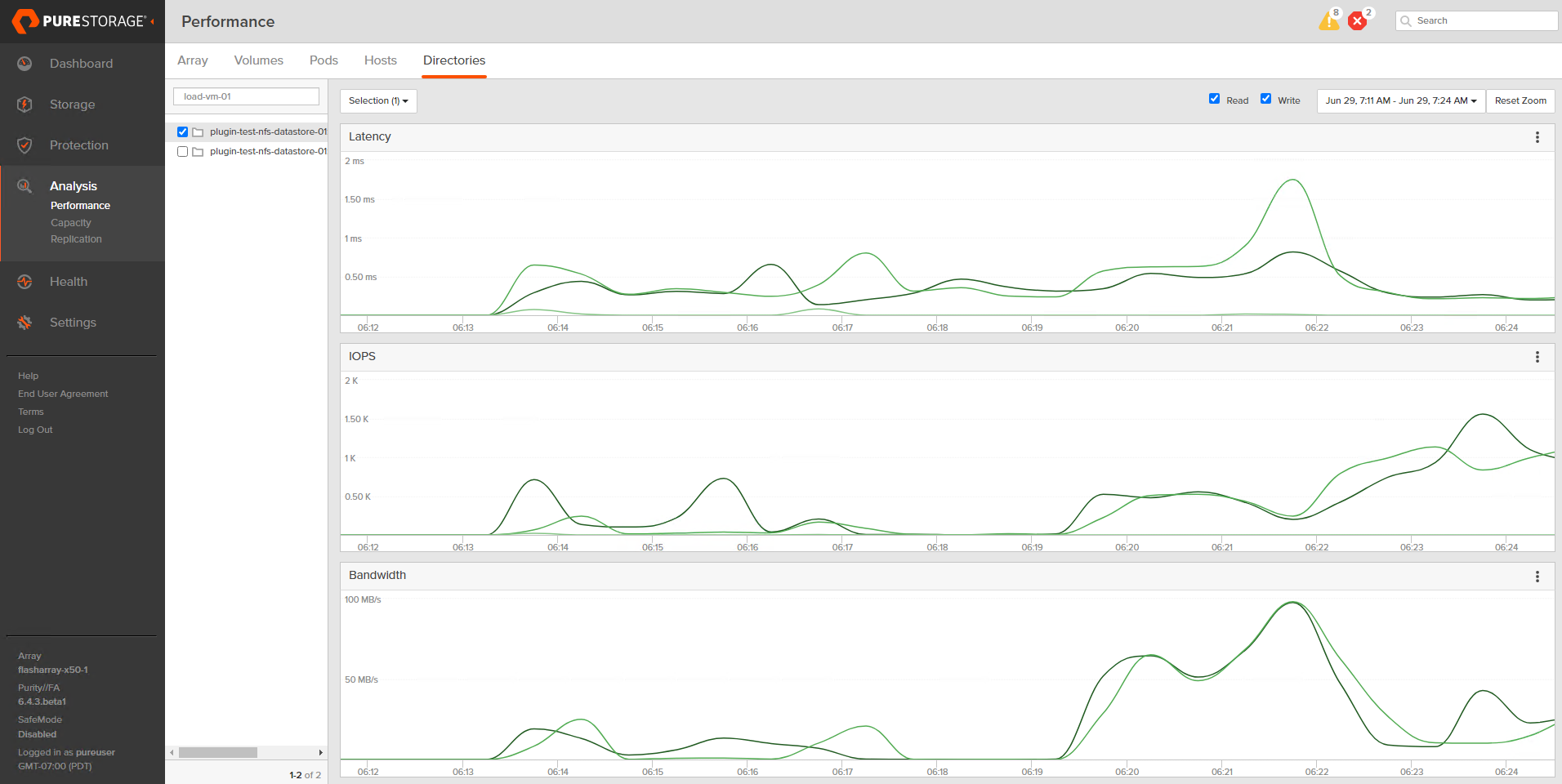
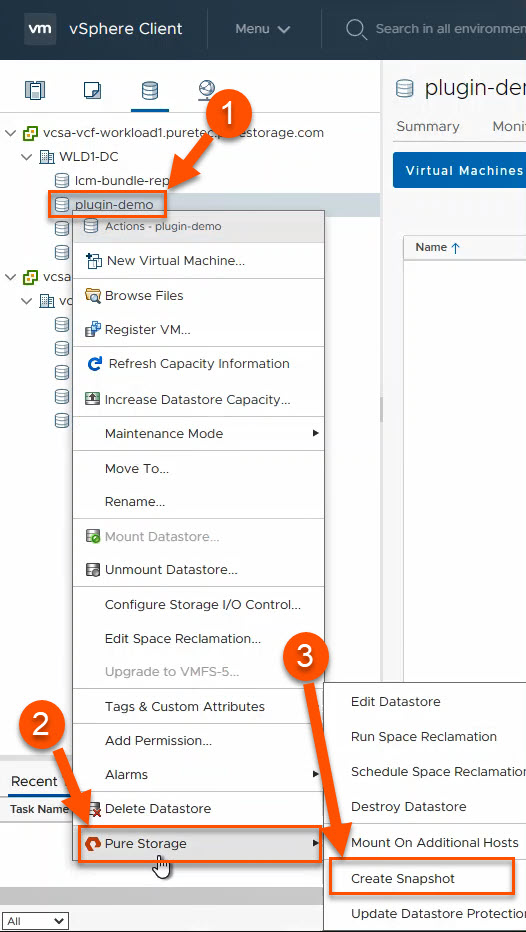
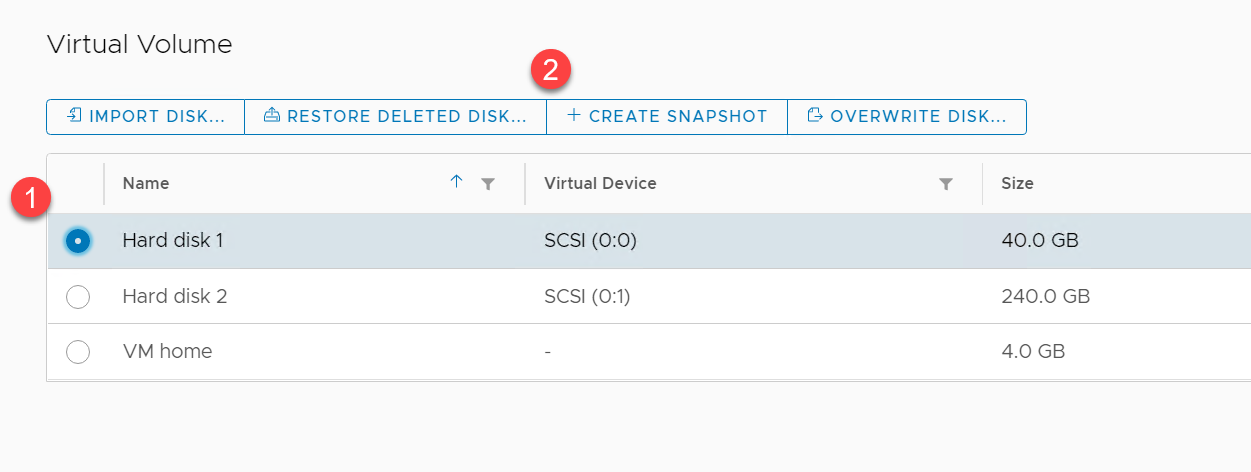
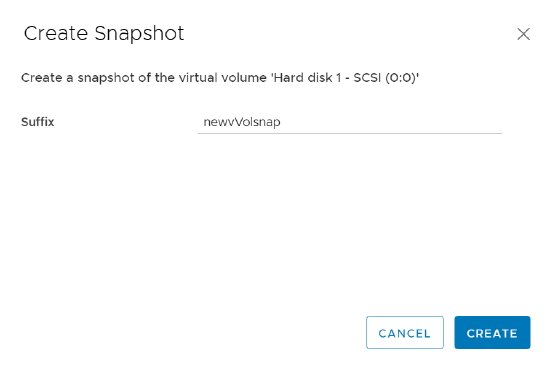
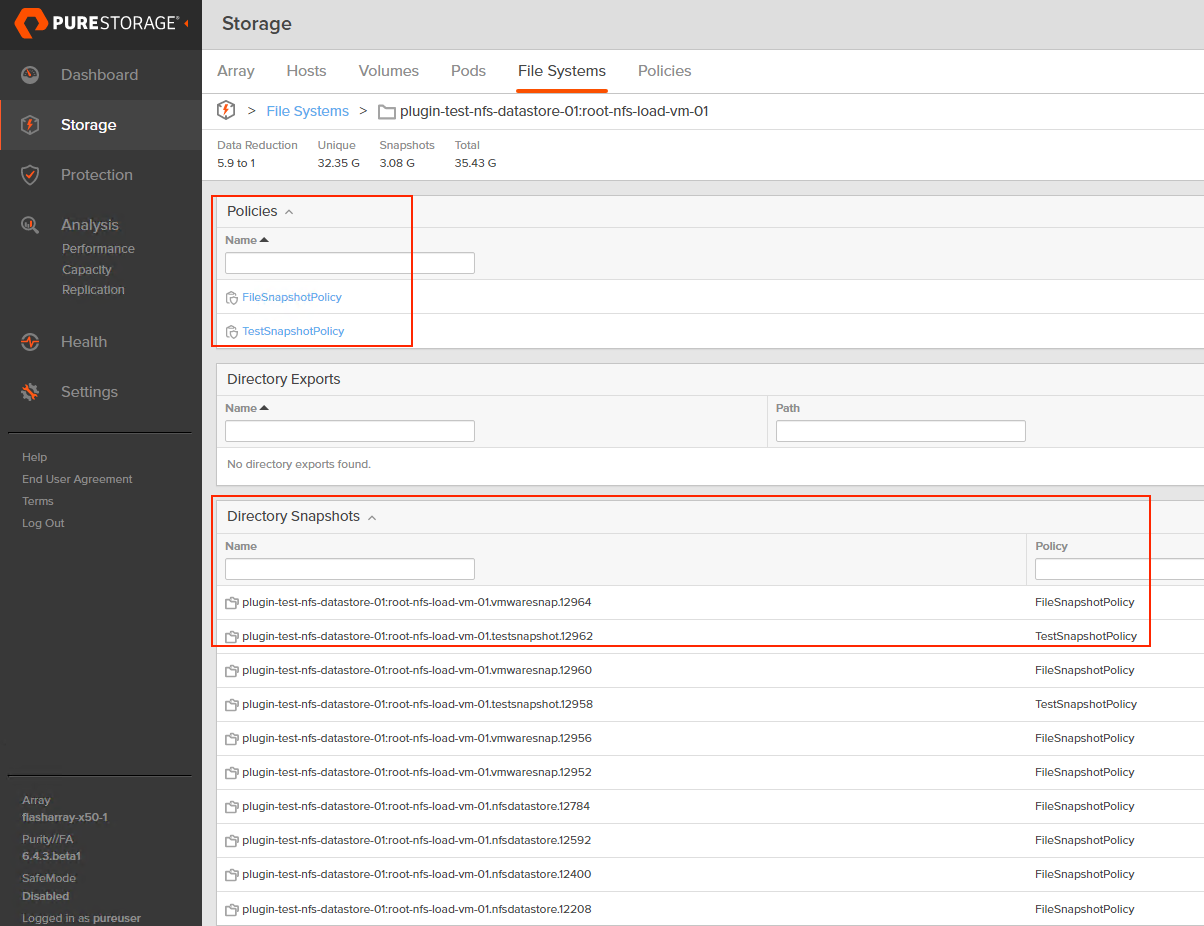
Want to have a special snapshot schedule for a certain group of VMs on a FlashArray-backed NFS datastore? With autodir, you can create snapshot policies and apply them to specific directories, allowing you to get around having to snapshot an entire NFS datastore like it’s a VMFS datastore. You can still snapshot the entire NFS file system if you want! Autodir enables you to have other options.
Your mission critical VMs likely have more complex snapshot retention and frequency requirements than your test VMs. With autodir, you can also apply multiple snapshot policies to the same directory (VM).
That’s sounds great Nelson, but surely autodir isn’t a good option for every NFS datastore on FlashArray. What are the reasons you wouldn’t want to enable autodir?
The main circumstance where autodir doesn’t make sense is if the scale limits of autodir are less than the directory count in your NFS datastore. Those can be found in this KB under “Managed Directories per array“.
If you want to see a demo of how autodir is configured on FlashArray, this video goes over it.
If you want to get detailed written instructions for how to configure autodir on FlashArray, this KB article is a good resource.