
One of the new features in vSphere 7 is support for NVMe-oF (Non-Volatile Memory Express over Fabric)–this replaces SCSI as a protocol and extends the NVMe command set over an external (to the host) fabric.
So what is it and why? I think this is worth a quick walk down memory lane to really answer both of these questions.
Before I get into it, below is a recent video/podcast/roundtable I did with the Gestalt IT with a few wonderful people:
- Christopher Kusek
- Greg Stuart
- Jason Massae
- Stephen Foskett
The premise is “Is NVMe-oF ready for the primetime?” Check it out and find out where we all land! For more on my thoughts, read on.
The Dark Days before VAAI
Let’s first take a look at ESX(i) external storage at the beginning of time: ESX 4.0 and earlier (yes I know there was a LOT before 4, but this is where our story begins).

You might remember VMFS-3 being limited to ~2TB, not the 64 TB that is supported today with VMFS-5 and VMFS-6. So the first question is why?
Well in the days of yore, from a storage perspective, ESXi could have been considered a performance bottleneck, but that isn’t (wasn’t) really accurate. It wasn’t the hypervisor layer. Instead it was file system semantics combined with the dynamic and flexible nature of VMs and their storage. Thin virtual disks, boot storms, snapshots, resizes, deletes, etc. Etc. A large portion of the problem was that VMFS used SCSI reservations for host coordination of file system locking. When A VM needed to be created/changed/etc. the owner ESXi host took a lock. Unfortunately, SCSI reservations are a fairly blunt tool–it is like shutting down an entire shopping mall while you clean just one of the bathrooms. A SCSI reservation locks the whole volume for the duration of the change–in the meantime all I/O of from all VMs on other hosts are locked out. So things like boot storms were painful–booting a lot of VMs took a significant number of competing and colliding locks and performance suffered. It didn’t make a lot of sense to put a ton of VMs on one file system–they could get in the way of each other. In many ways this was a major part of the reason for the continuously unconsummated proclamation of it being the Year of VDI.
There were of course other issues (VMFS pointer blocks limiting capacity and so on) but fixing those issues and then subsequently increasing capacity without also solving the lock contention would only serve to exacerbate issues of performance at scale. So VMware did the smart thing and set out to resolve that too.
One thing they realized is that storage arrays could do some things really well (cloning, zeroing) but also that VMFS was a shared file system–but those hosts rarely needed the same blocks at the same time. Why lock the whole volume? Can this coordination be improved? Can the load on VMFS also be reduced by leveraging the array technology better?
To solve for these things, VMware introduced VAAI (vSphere API for Array Integration) in ESX(i) 4.1. XCOPY, WRITE SAME, ATS (later also my favorite: UNMAP). The most important one for this conversation was ATS–Atomic Test and Set, AKA: Compare and Swap, AKA: Hardware Assisted Locking. This is a SCSI command that ESXi now can use to coordinate with the underlying storage device to lock only the specific parts of the file system that the host needs, and leave open the parts that it does not. This made VMFS a truly shared and and scalable file system. The locking mechanism no longer stood in the way of performance.
Your Move, Storage Arrays
In any system (IT systems or well anything–highways, plumbing, etc) the goal around “performance” is to rid the system of bottlenecks. Though you never really remove bottlenecks, you just move them elsewhere and hopefully make them less impactful.
Let’s use my favorite example for this. Highways.
We all hate highway traffic. So I think we can all relate to this metaphor. Let’s say we have an on ramp that goes onto a two-lane highway (one lane going south, one lane going north–we will focus on northbound). That northbound highway lane then has one exit lane. So this system supports one car changing states at a time, one can enter, one can leave. If the exit is slowed, the highway slows, the on-ramp backs up. We could add a 2nd exit, but we are still bottlenecked by the highway having one lane. And there only being one on-ramp.
What VMware did with VAAI is akin to adding lanes to the highway. A lot more potential concurrency. Probably the most accurate description would be VMFS without VAAI was like a highway system with four on-ramps, but only one lane. VAAI added three more lanes.
This moved the bottleneck down to the storage. Can the storage arrays add enough “exit ramps” to support the new level of traffic? Can they support the throughput/IOPS that now can come through since the lock-level contention was removed? They did–or at least they certainly tried. Various options like short-stroking drives, caching layers (host or array side), parallelizing spindles, etc. Through–sometimes complex–storage architectures, the storage vendors added the needed number of exits. 2 TB VMFS datastores could perform as intended.
Right back at ya VMware
So the ball was back in VMware’s court.
Lots of lanes. Lots of exits. Things were running smoothly.
But then VMware environments were growing, VMs were getting larger though. The on-ramps are full. The cars have to go down other highways (other datastores) because they can’t get onto this one (not high enough capacity). If an underlying device under a datastore could offer up more performance (way more exits than on-ramps), it was wasted. Those resources were often reserved for that LUN. Plus, having a multitude of 2 TB datastores started becoming cumbersome (why manage multiple highways in parallel that went to the same place?). So VMware added way more on-ramps!
VMFS was like “You want more on ramps? Okay how about 32x more?” VMFS now supported 64 TB. You could put a lot more VMs on the same datastore. You might remember my metaphor for VAAI (it is like a highway system with 4 on-ramps but only one lane–VAAI added three lanes). Well VAAI actually added thousands of lanes. Just with the top level bottleneck (capacity) they were not really useable. So the bottleneck didn’t fall down to locking, it fell back to storage.
Back to you storage!
Woah okay so could storage vendors support, on a single volume, the potentially heavy needs of 64 TBs of VMs at once? At this point, rarely. Best practices around smaller datastores endured. 2 TBs. 4 TBs. 8 TBs if you were a maverick.
“How big should I make my datastores?”
–Anonymous VMware Admin
…is a question we all remember. While it was capacity question, it was really a performance question in disguise.
Enter Flash
Spinning disk arrays endeavored to solve this with varying degrees of success. But then comes in the era of the all-flash arrays. Arrays built for flash, and only flash.

Armed with the knowledge of how flash works–how it is different than disk, a lot of the designs and architectures of the past were jettisoned. Flash is fast. Flash is not dependent on how fast a spindle could spin.
If we were using our highway metaphor, the change to flash could be like changing what was after those exits. After you left the exit you parked. Spinning disk was like a parking lot with one or two entrances. Flash was like a parking garage with a lot more entrances.
Arrays like the Pure Storage FlashArray (I work for Pure Storage, disclaimer) not only untethered you from disk, but also the “LUN” from configuration-based performance limits. On the FlashArray there is no per-volume performance limit (unless you set one) besides what the array itself can offer up. Which is a whole lot. The volume was tied to the array, not a set of disks, or SSDs, or cache, or CPU slices, or whatever. If the array can do it, so can the volume. So 64 TB VMFS datastores now made sense. You could get the same performance from 32, 2 TB datastores as one 64 TB datastore. So from a performance perspective, why manage more objects than necessary?
All-Flash-Arrays threw the bottleneck back. But not to ESXi. Not to VMFS.
It’s NVMe, not NVMyou
There was a more fundamental problem now. Flash was still in the SAS SSD form factor. Serially Attached SCSI SSD. SCSI was built and designed for spinning disk in the 1980s. Neither Serial or SCSI seems like something built for Flash. Indeed it was not. Having a parking garage with a few dozen entrances didn’t allow a lot of throughput. If you added floors to that garage, sure you could park more cars, but not at once. More cars, same number of entrances, made it slower. More GBs? Same bottleneck? Brought potential for less IOPS per GB.
Why the limit? Well here comes NVMe. NVMe was built for Flash. It was built to leverage the parallel nature of the underlying NAND. Why should enterprise storage not go that route?
The FlashArray was built for Flash. So the next logical step was to move to NVMe. NVMe allows that mythical parking garage to have an entrance for each parking space. Each added space, got an entrance. If you added floors, you added entrances. Performance scaled with capacity. The FlashArray first replaced the NVRAM with NVMe-based flash modules, then the same thing with the backend storage in the chassis. SAS-based SSDs with NVMe PCIe connected flash modules.
This all allowed the internals of the array chassis to scale, but what about expansion shelves? What about the front end?
So the FlashArray added expansions shelves with something called NVMe-oF (NVMe over fabrics). So no more SCSI for the flash modules, or the connection over the backend fabric.
But the front end had the same issue.
This VMFS superhighway transport layer, much like SAS-based backends was entirely traversed by cars. Cars could only carry a few people at once. SCSI over the fabric reduced how much could be sent at once. The concurrency was still limited.
Enter the bus.

But not just a bus. A bus with many floors. A bus that had an entrance for each seat. A bus no longer constrained by the limited capacity of a car, nor the limited number of entrances.
This is what NVMe does for the transport layer.
The highway material is the same (ethernet, Fibre Channel, TCP) but what is sent and how much can be sent at once changes. The bottlenecks are gone.
Are there newer bottlenecks? Always. Of course. But we have a lot more seats to fill in those available buses and parking garages before that becomes an issue. And those buses and garages are just getting bigger–with an equivalent number of entrances. This is why NVMe is critical.
Back to the Point
So what was this blog post about again? Oh right. vSphere 7.
So what VMware added in ESXi 7, was an NVMe-oF driver. So a VMFS can be added and used when the underlying protocol is NVMe-oF. VMware currently supports two modes of NVMe-oF:
- RoCEv2 (RDMA (Remote Direct Memory Access) over Converged Ethernet) . The version two mainly differs from v1/v1.5 by the fact that v2 allows the packets to be routable.
- Fibre Channel. NVMe over your FC fabric.
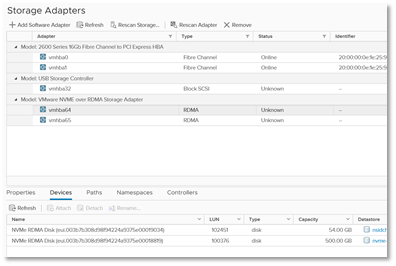
Pure has led with RoCE v2. We did this for a couple of reasons (in my opinion). First reason is that our connection to our expansion shelves is via RoCEv2 We already did the work. Therefore it was developed and in use for a long time before we added frontend RoCEv2 (e.g. it was mature). Additionally, Ethernet networks (400 Gbps) are looking to eclipse FC networks on throughput. So it seemed a logical place to start for a tech that was throughput-focused. Of course FC isn’t going away, so we are working on that.
The question is: Is it ready for prime-time? Well that depends on what you need.
Prior to ESXi support of NVMe-oF, the only OS that supported it was baremetal Linux. The folks that really needed the performance of NVMe-oF went that route.
Why not just go the internal NVMe route? It works great on my home PC! Good point! My PC (the one I am writing this on) boots off of NVMe flash and it boots faster than my TV. But a problem we saw with many workloads that needed NVMe-type performance was that they were not static workloads. They were datasets. Large datasets. Datasets that changed. A lot.
These servers were POWERFUL. Read: Expensive.
Removing and ingesting new large datasets to internal storage over the network took a very long time. Making these expensive servers idle. SAN-based storage allowed for datasets to be swapped almost instantly. Also protected, replicated, snapped, etc. With latencies that rivaled internal storage. I won’t spend any more time on that, as I think we all understand the value of storage arrays, or you likely wouldn’t be reading this. Or I doubt I will change your mind with a few more sentences.
Anywho, for the folks that were doing that, but want the benefits of virtualization–it is ready. The raw performance is there.
Our RoCEv2 code is many years old now and is mature. What about VMware? Well one thing is that they have been working on this for a long time. You might remember VMworlds of the past few years where we had tech previews at the Pure booth of NVMe-oF with vSphere. VMware has been working on it for awhile and we have been working with them.
Furthermore, it is just the transport layer. There is still a lot of SCSI above the datastore to the VM itself. That hasn’t changed yet. VAAI is mostly there. ATS, the important one here of course is:
| Feature | SCSI Command | NVMe Command |
|---|---|---|
| Atomic Test and Set (ATS) / Hardware Accelerated Locking | COMPARE AND WRITE (0x89) | Compare and Write (0x05 / 0x01 – fused command) |
| Block Zero / Hardware Accelerated Init | WRITE SAME (0x93) | Write Zeroes (0x08) |
| Extended Copy (XCOPY) / Hardware Accelerated Copy | XCOPY (0x83) | No equivalent NVMe command |
| Dead Space Reclamation (Block Delete) | UNMAP (0x42) | Deallocate |
It is missing XCOPY though. So customer who leverage a lot of the “fancier” features of VMFS are going to miss a few things (accelerated VM copies etc).
VMware is working on that part of the stack. You can see in Bryan Young’s VMworld session (VMware PM for External Storage) https://videos.vmworld.com/global/2019?q=HCI3451BU the process underway:
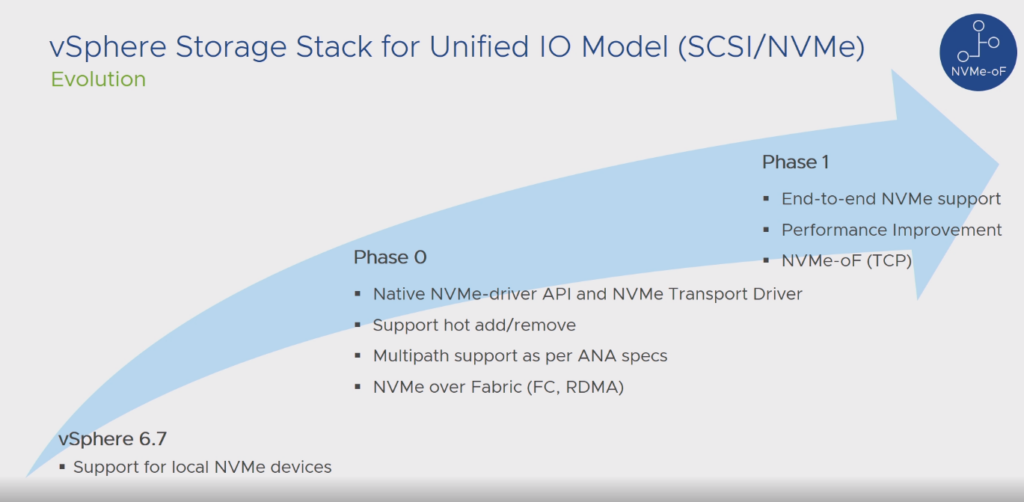
VMware did the right thing here. Let’s focus on the main use case right now for NVMe-oF, the performance and the plumbing to connect NVMe namespaces. Let’s not do everything at once. Do a couple things at once, and do them well.
So for the customers who need that stuff, it might not be “ready” for them. This is one of the reasons we support NVMe-oF and SCSI on the same FlashArray, if they have both needs, they can use both.
The Missing Link
But let’s go back to the features that are “missing”. Two notable examples: XCOPY. Raw Device Mappings. XCOPY is for offloading VM copies/Storage vMotion and RDMs are for well direct volumes to a VM. Both of which have always been half-measures.
Virtual Volumes (vVols) resolve both of these issue. vVols don’t just offload a few MB at a time for VM cloning, but instead vVol atomically issues one operation for the entire volume (or set of volumes) at once. It is VERY fast because it directly leverages array-based volume cloning. vVols also offer up the granularity provided by RDMs and the overall benefits of the richness of the VMware storage stack.
So introducing more technical debt and tradeoffs is not part of the design here. Let’s move away from XCOPY, let’s move away from RDMs. By not re-building and presenting it as an option it in the first place.
vVols though is a SCSI thing. Well the data path–the management is outside of that (VASA). So the data path needs to be updated. VMware is working on that. From the same presentation linked above:
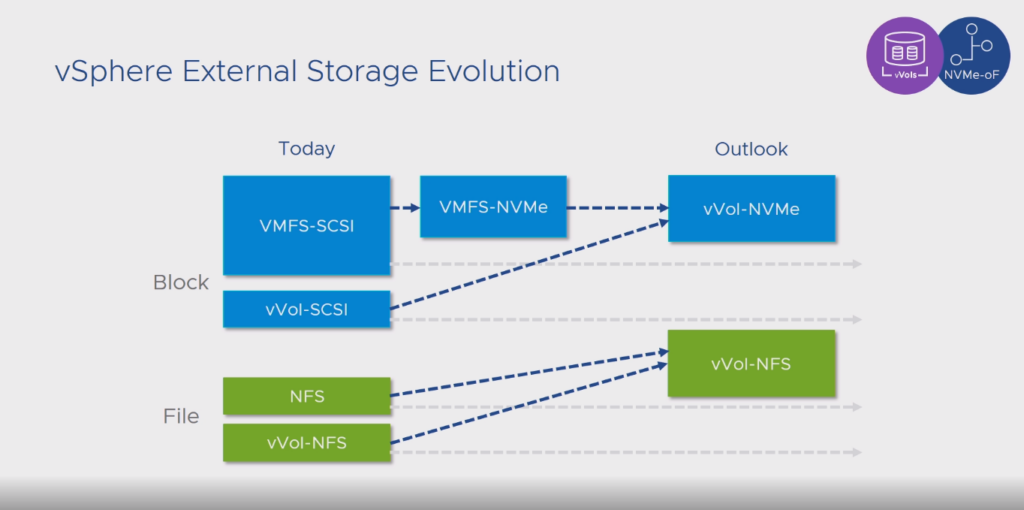
So NVMe is where storage is going. See how it is even being ported to disk:
https://blocksandfiles.com/2020/05/27/nvme-universal-block-storage-access-protocol/
vVols is where VMware is going with external storage. So the quicker you can plan for this, the sooner you start learning about it, or testing it the better. There is still work to be done of course, but the short and longer term future is clear.
If you want more information on Pure and VMware NVMe-oF check out our support site:
Thanks for the detailed explanation.
You’re welcome!
Great article Cody. So vvols will depend on a VASA upgrade, what upgrade is required for PSO storage claims to get end to end NVMe-of?
That is a bit down the road at this point, but at this time storage provisioned by PSO does not support NVMe-oF AFAIK
That was an excellent history lesson and a great explanation of current events. Thanks!
Great article! Thanks
Great article Cody! Does NVMe over RoCEv2 require special host io cards or can it run over any ethernet host io card?
Thank you! You need RDMA-capable Ethernet NICs (RNICs), this search on their capability guide will show you what is supported https://www.vmware.com/resources/compatibility/search.php?deviceCategory=io&details=1&deviceTypes=6&pFeatures=299&page=1&display_interval=10&sortColumn=Partner&sortOrder=Asc