
While the title of this post does sound like a halfway decent Harry Potter novel, this is far more nefarious. Pure Storage, like many other vendors have a best practice around lowering the Disk.DiskMaxIOSize setting on ESXi hosts when using UEFI boot for your Windows VMs. Why? Well:
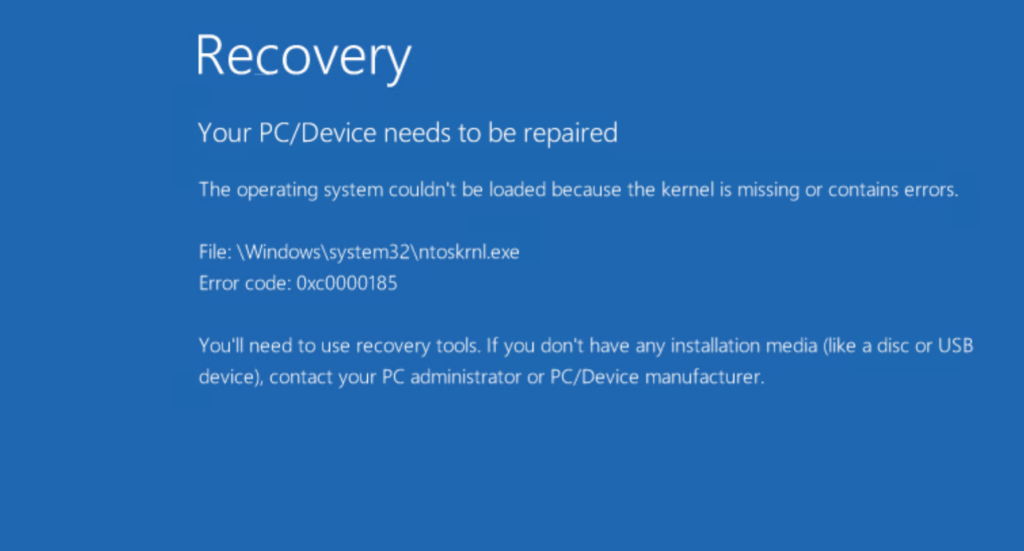
Yes not having it set in a few situations would cause BSOD. First off, why?
Well big SCSI operations were executed and the storage array could not handle them. When booting a UEFI-based VM (not BIOS) a 7 MB read was issue which is larger than most array support. The read would fail and well so would the boot process. Leading to BSOD and a message like below in the ESXi vmkernel log:
Cmd(0x45a280b2f8c0) 0x88, CmdSN 0x8c32824c from world 2103471 to dev "naa.624a93705ee86996f8334fa0000d2ad7" failed H:0x0 D:0x2 P:0x0 Valid sense data: 0x5 0x24 0x0
That’s pretty much the story. We could end the blog post there, but let’s not.
How Large of a SCSI Operation does my array support?
Well you can certainly ask your vendor. But there is a way you can find it directly by running a SCSI inquiry to a volume from your storage. For Windows, a simple option is install Visual SCSI Explorer. For Linux, use sq_inq.
In a SCSI device, there is a header of information on the device that describes certain limits, feature support, and other pieces of information. This is called the VPD (Vital Product Data). VPD has a few “pages” one being the Block Limits page, also known as the B0h page.
If you run an inquiry against this, you will see a few pieces of information:
8/6/2020 12:57:49.457 Block Limits (B0h) page 8/6/2020 12:57:49.457 Write same no zero (WSNZ) 1 8/6/2020 12:57:49.463 Maximum compare and write length 0x01 (1) 8/6/2020 12:57:49.463 Optimal transfer length granularity 0x0001 (1) 8/6/2020 12:57:49.463 Maximum transfer length 0x00002000 (8192) 8/6/2020 12:57:49.463 Optimal transfer length 0x00002000 (8192) 8/6/2020 12:57:49.469 Maximum PREFETCH XDREAD XDWRITE transfer length 0x00000000 (0) 8/6/2020 12:57:49.469 Maximum UNMAP LBA count 0xFFFFFFFF (4294967295) 8/6/2020 12:57:49.474 Maximum UNMAP block descriptor count 0x00000001 (1) 8/6/2020 12:57:49.474 Optimal UNMAP granularity 0x00000001 (1) 8/6/2020 12:57:49.474 UNMAP granularity alignment valid (UGAVALID) 0 8/6/2020 12:57:49.474 UNMAP granularity alignment 0x00000000 (0) 8/6/2020 12:57:49.474 Maximum WRITE SAME length 0x000000000000FFFF (65535)
For this discussion I will focus on Maximum transfer length. This says how many blocks the volume supports in a given SCSI operation (a read or a write for instance). On Pure, this says 8,192. What is a block? Well a block is equal to the sector size as sometimes referred, which I have written about here:
On the FlashArray, our sector size is 512 bytes. So 8,192 blocks times 512 bytes is 4 MB. This our largest support SCSI operation and why we tell customers to limit hosts to sending I/Os no larger than 4 MB. If an application issues a larger one, it must be split up before sending.
Disk.DiskMaxIOSize
So how to resolve this dilemma? Well, ESXi has a setting called Disk.DiskMaxIOSize:
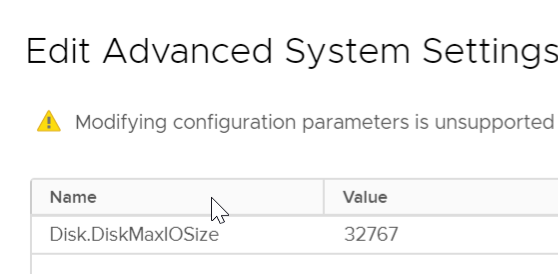
This defaults to 32 MB. What is says is that any I/O smaller than 32 MB will remain intact through the hypervisor. Anything larger will be split into 32 MB chunks. VERY few things are that larger, so it rarely came into play. Is there a performance impact to splitting it up when that did occur? Not really. I mean probably but I/Os in the MB of size take a while to process, so the overhead of the split is not noticeable relatively (if you have to wash your hands every time you pour a glass of water it will add noticeable duration to the act of filling a glass, if you have to wash your hands every time you fill a swimming pool with a garden hose, it is basically zero in added duration).
So the recommendation (from Pure) was to make this 4 MB, so that 7 MB read would be split before it got to the storage. Others require 1 MB etc.
So there are a few downsides here. One, it is a host wide setting, so you can’t change it on just one device or vendor. There is no claim rule for this. So if you have multiple vendors you have to go with the lowest common denominator. Furthermore, you actually have to set it. Anything you have to configure to make a default behavior work (booting up a VM) is, in my opinion, a bug.
So that begs the question: whose bug? VMware or your storage vendor?
The Resolution
Arguably, both. First off any time you need to change something on ESXi to get it to work with Pure I see that as a “solutions” bug. My team needs to do something to fix it. Either make the Pure platform better, or work with VMware to improve/change their product. One route we chased was improving the FlashArray–we do have the ability to support larger I/O sizes, but currently that is in directed availability (you need to ask us to enable it).
Though VMware was chasing this too as it was not just a single vendor issue. And arguably the real bug is on their side. They should be listening to what the array tells them they support! Via the maximum transfer length.
Thanks to Markus Grau–one of our PSEs who alerted me to this btw!
If you look in the KB article from VMware on this issue, it now says it is fixed:
This issue is resolved in VMware ESXi 6.0, Patch Release ESXi600-201909001, VMware ESXi 6.5, Patch Release ESXi650-201811002 and VMware ESXi 6.7 Update 1 Release.
The minimum version of ESXi 5.5 that includes this fix is VMware ESXi 6.0. Upgrade, people!
What was fixed?
Well there are actually two changes that matter:
PR 2078782: I/O commands might fail with INVALID FIELD IN CDB error ESXi hosts might not reflect the MAXIMUM TRANSFER LENGTH parameter reported by the SCSI device in the Block Limits VPD page. As a result, I/O commands issued with a transfer size greater than the limit might fail with a similar log:
2017-01-24T12:09:40.065Z cpu6:1002438588)ScsiDeviceIO: SCSICompleteDeviceCommand:3033: Cmd(0x45a6816299c0) 0x2a, CmdSN 0x19d13f from world 1001390153 to dev "naa.514f0c5d38200035" failed H:0x0 D:0x2 P:0x0 Valid sense data: 0x5 0x24 0x0.
and
PR 2156841: Virtual machines using EFI and running Windows Server 2016 on AMD processors might stop responding during reboot Virtual machines with hardware version 10 or earlier, using EFI, and running Windows Server 2016 on AMD processors, might stop responding during reboot. The issue does not occur if a virtual machine uses BIOS, or if the hardware version is 11 or later, or the guest OS is not Windows, or if the processors are Intel.
The first one now forces ESXi to listen to what the array says. So it will look at the sector size and max transfer length and use that as the larger I/O size for that given device. It will only adhere to Disk.DiskMaxIOSize if it is set smaller than what is calculated for the SCSI device in question.
The second one changes how a VM with UEFI behaves in the first place–it doesn’t issue that large of an I/O during boot so that this issue does not occur. This was introduced with VM Hardware version 14–which requires ESXi 6.7 or later.
It is important to note that it is possible for OTHER things to create too big of an I/O–vSphere Replication had a tendency to do this as well. So fixing it in places besides just VMware hardware was necessary.
Final Thoughts
So if you are on one of the above releases, you no longer need to set Disk.DiskMaxIOSize to a smaller value (note I am speaking for Pure, not other vendors, please refer to their documentation).
What about vVols? There is no VMFS, so no single LUN. Well this adheres to what is advertised by the protocol endpoint. So for Pure, this is 8192/512B like above.
You also might say, hey I am running 6.7 GA that doesn’t have this fix and I have UEFI booting VMs running older VM HW on block and I don’t see this problem. Well likely you are using iSCSI. Specifically Software iSCSI.
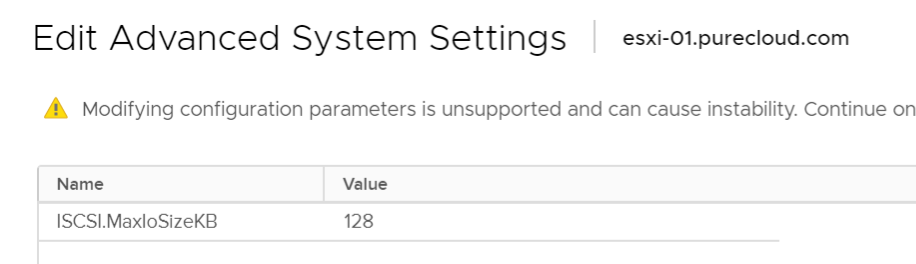
There is a not-well-documented setting globally for iSCSI on an ESXi host called iSCSI.MaxIoSizeKB. This actually splits any iSCSI I/O to (by default) 128 KB. So this problem does not exist on iSCSI.
[root@esxi-03:~] esxcli system settings advanced list -o /ISCSI/MaxIoSizeKB Path: /ISCSI/MaxIoSizeKB Type: integer Int Value: 128 Default Int Value: 128 Min Value: 128 Max Value: 512 String Value: Default String Value: Valid Characters: Description: Maximum Software iSCSI I/O size (in KB) (REQUIRES REBOOT!)
My guess on why this exists is that jumbo frames are not enabled by default and therefore letting larger I/Os go through and getting split at the TCP/IP layer could cause more overhead for the split then if the SCSI stack did it.
How about NVMe? Stay tuned on that–pay attention to Jhop (Jacob Hopkinson on my team who goes by Jhop)’s blog for that.
So in an 100% Pure environment, if you are on one of these ESXi releases, you may safely change that setting back to the default.
Our best practices reflect this https://support.purestorage.com/Solutions/VMware_Platform_Guide/User_Guides_for_VMware_Solutions/FlashArray_VMware_Best_Practices_User_Guide/dddVMware_ESXi_Host_Configuration#Disk.DiskMaxIOSize
2 Replies to “Disk.DiskMaxIOSize and the Blue Screen of Death”