Hello- this is part 3 in the series of blogs on ActiveDR + NFS datastores. In part 2, I covered how to connect ActiveDR to an NFS file system that’s backing an NFS datastore. In this blog, I’ll be covering how to connect the target NFS export in vSphere and how to run a test failover. The reason for covering test failovers before production failovers and failbacks is that I strongly recommend performing or scheduling a test failover immediately after configuring any disaster recovery solution. It is possible to not have the necessary requirements for a failover when it is critical that the failover happens quickly; testing failing over your environment before needing it in a production down scenario will reduce or eliminate this possible pain.
For the purposes of this blog, I am using Pure Storage’s remote vSphere plugin. In general, I strongly recommend installing and using this plugin to manage your FlashArray(s) more easily from the vSphere GUI. Additionally, I’ve made a demo video that covers the steps covered here. Here’s a table of articles in this series:
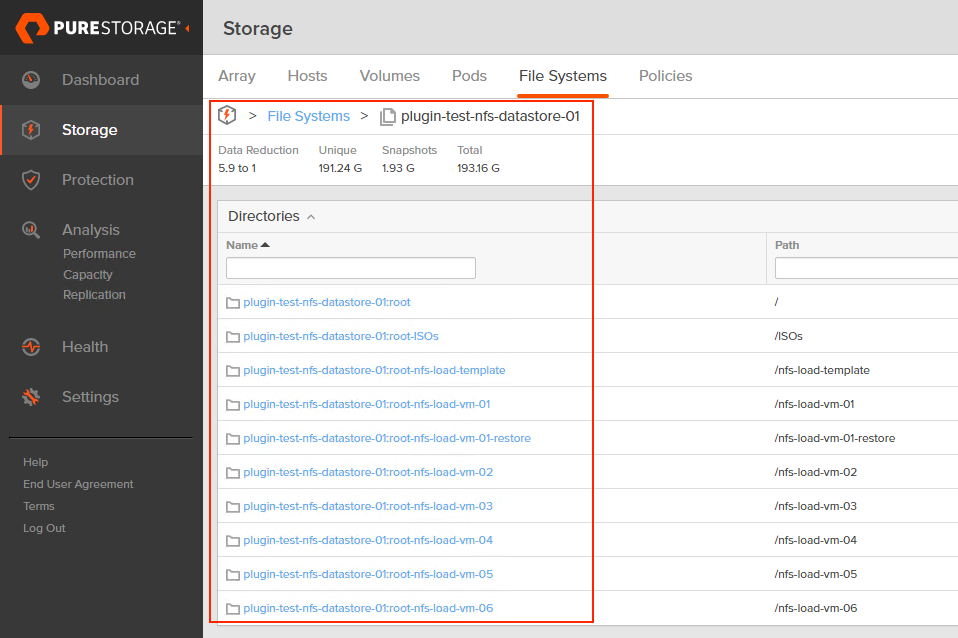
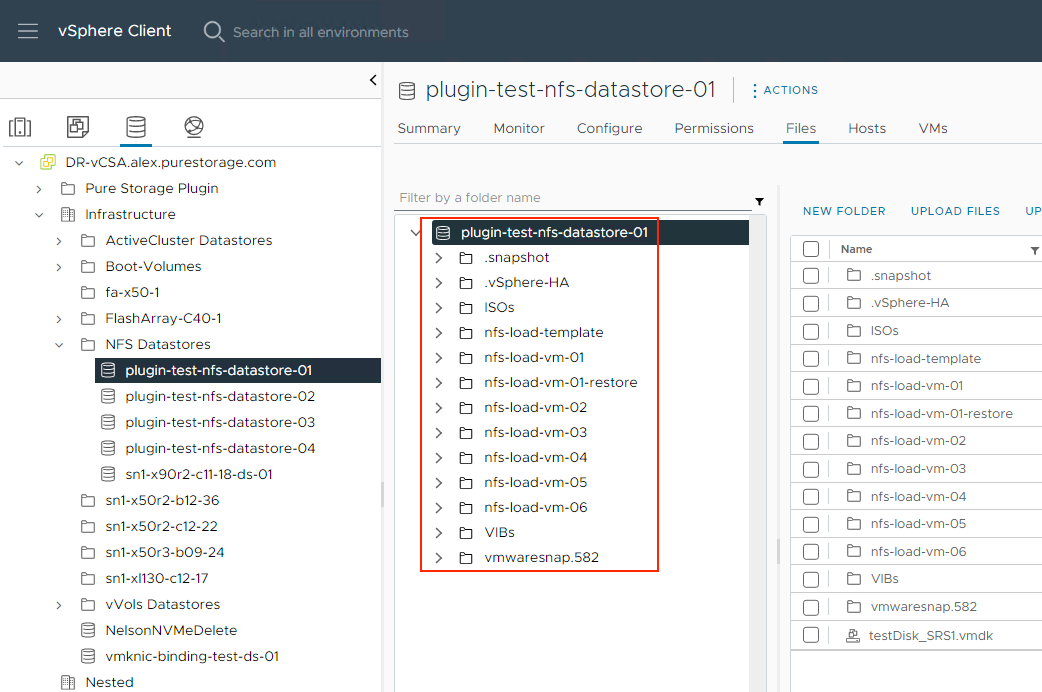
This environment already has a mounted NFS file system from the source FlashArray. The steps to mount the NFS file system from the source array are the same as the steps for the target array except you won’t have to promote the pod on the source array.
When you perform failovers, do test failovers or are cleaning up your objects from these operations you’ll want to ensure that you follow the steps outlined here.
I’m going to be writing a series of blogs on ActiveDR (Active Disaster Recovery) with NFS datastores over the next couple of posts. Some of the other posts I have planned in the near future are:
Failover scenarios where the ESXi hosts are connected to both arrays
Failover scenarios where the ESXi hosts are only connected to one array
In this blog I will do an introduction to the technologies and I will give some high level information on how you might want to use them together.
Replication Options on FlashArray
This post will be covering FlashArray specific replication techniques that you may or may not be familiar with. If it is the latter, my colleague Cody Hosterman has a great primer on our technologies that might be worth a read for you. Here’s a table of articles in this series:
Hello- Nelson Elam here. I wanted to go over the reasons why I think you should enable automatic directory management (autodir) if you are planning to use NFS datastores on FA File. A quick note before we get started- autodir is not restricted to ESXi hosts but ESXi hosts will be the focus of this blog.
What is autodir? Autodir is a way for FlashArray to reflect the current directory structure on an NFS datastore that’s managed by a connected host- a managed directory. What does this mean for ESXi? Whenever a VM gets created on an NFS datastore, a new directory (folder) gets created for the VM on the datastore. When a VM gets deleted from disk, the directory gets destroyed. Note that directories you create or destroy manually on an NFS datastore in vCenter get reflected in FlashArray as well. Simple enough!
If you’ve read the FA File launch blogs or have seen some of the webinars we’ve done about FA File or NFS datastores, you’ve likely seen or heard us talk about VM granular management being part of FA File. Autodir enables VM granular management. Let’s dive into VM granular management in the context of NFS datastores.
With autodir enabled, these changes are reflected on FlashArray and enable FlashArray administrators to be able to see the current state of the NFS file system from a directory perspective.
Want to figure out why the data reduction ratio of a file system dropped so significantly? Now you can see that at a per-VM basis on FlashArray.
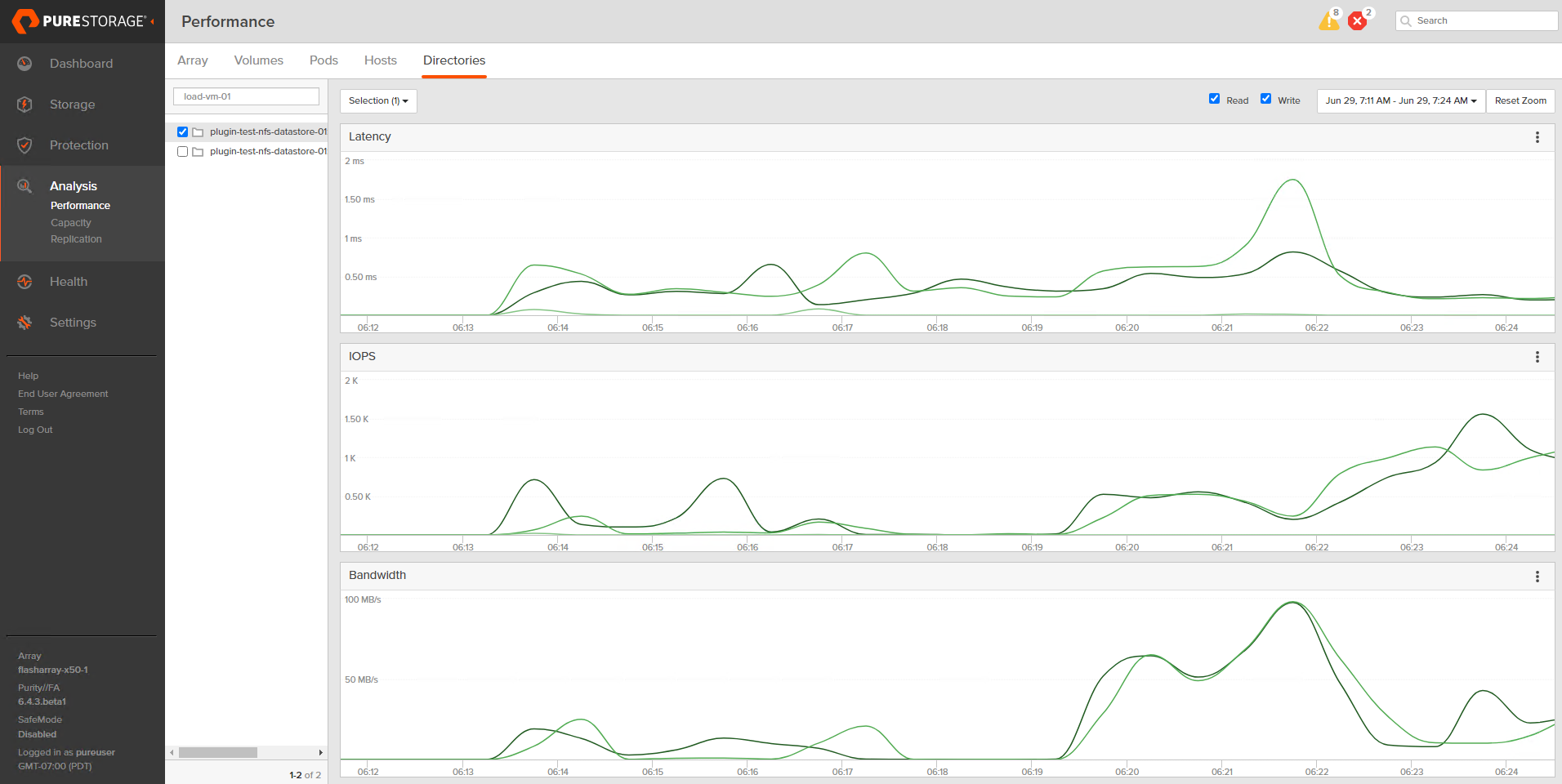
Want to see which VMs are spiking in load at inopportune times? You can use the FlashArray GUI to help figure that out. Worth mentioning this info is more easily consumed in Pure1 when using the VM analytics collector.
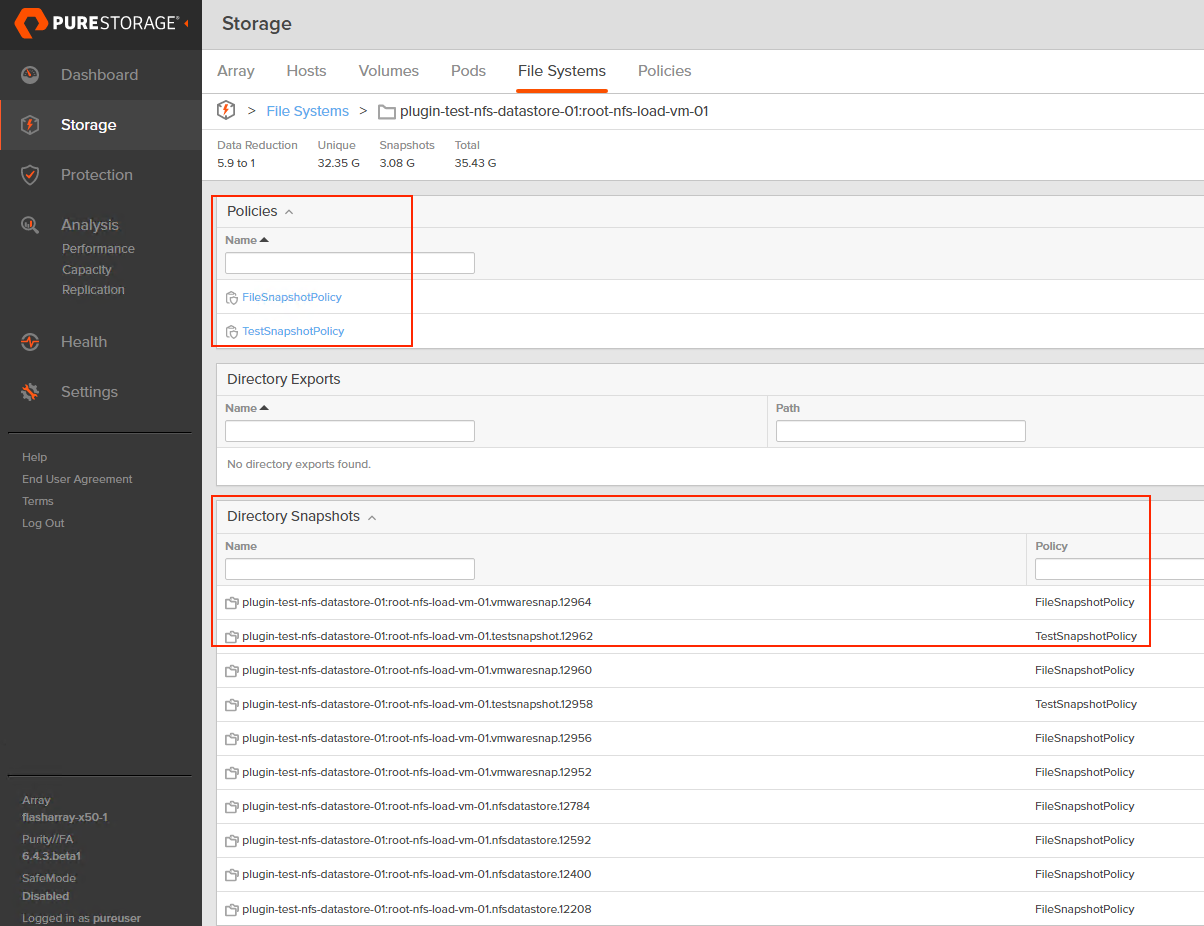
Want to have a special snapshot schedule for a certain group of VMs on a FlashArray-backed NFS datastore? With autodir, you can create snapshot policies and apply them to specific directories, allowing you to get around having to snapshot an entire NFS datastore like it’s a VMFS datastore. You can still snapshot the entire NFS file system if you want! Autodir enables you to have other options.
Your mission critical VMs likely have more complex snapshot retention and frequency requirements than your test VMs. With autodir, you can also apply multiple snapshot policies to the same directory (VM).
That’s sounds great Nelson, but surely autodir isn’t a good option for every NFS datastore on FlashArray. What are the reasons you wouldn’t want to enable autodir?
The main circumstance where autodir doesn’t make sense is if the scale limits of autodir are less than the directory count in your NFS datastore. Those can be found in this KB under “Managed Directories per array“.
If you want to see a demo of how autodir is configured on FlashArray, this video goes over it.
If you want to get detailed written instructions for how to configure autodir on FlashArray, this KB article is a good resource.
Today I want to tell to you about what I use the vSphere plugin for regularly in my lab to hopefully help you get more value out of your existing Pure array and tools. The assumption of this guide is that you already have the vSphere plugin installed (follow this guide if you don’t currently have it installed or would like to upgrade to a more feature-rich remote plugin version). Our vSphere plugin release notes KB covers the differences between versions. If you aren’t sure what version you want, use the latest version.
Why should you care about the vSphere plugin and why would I highlight these workflows for you? Pure’s vSphere plugin can save you a significant amount of time in the configuration/management of your vSphere+FlashArray environment. It can also greatly reduce the barriers to success in your projects by reducing the steps required of the administrator for successful completion of a workflow. Additionally, you might currently be using the vSphere plugin for a couple of workflows but didn’t realize all of the great work our engineers have put into making your life easier.
I am planning to write more blogs on the vSphere plugin and the next one I plan to write is on the highest value features that exist in current vSphere plugin versions.
Create and Manage FlashArray Hosts and Host Group Objects
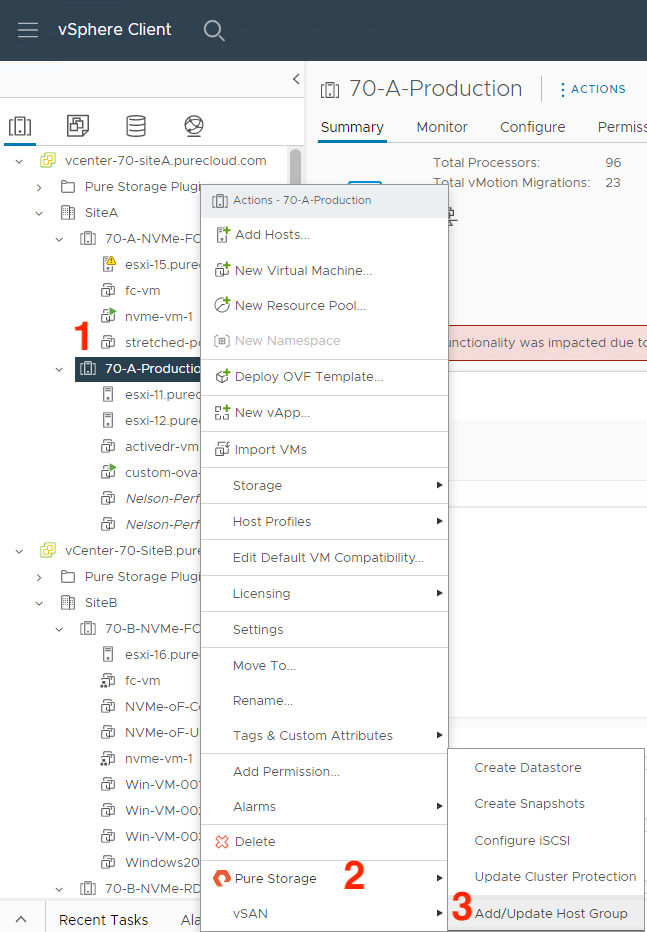
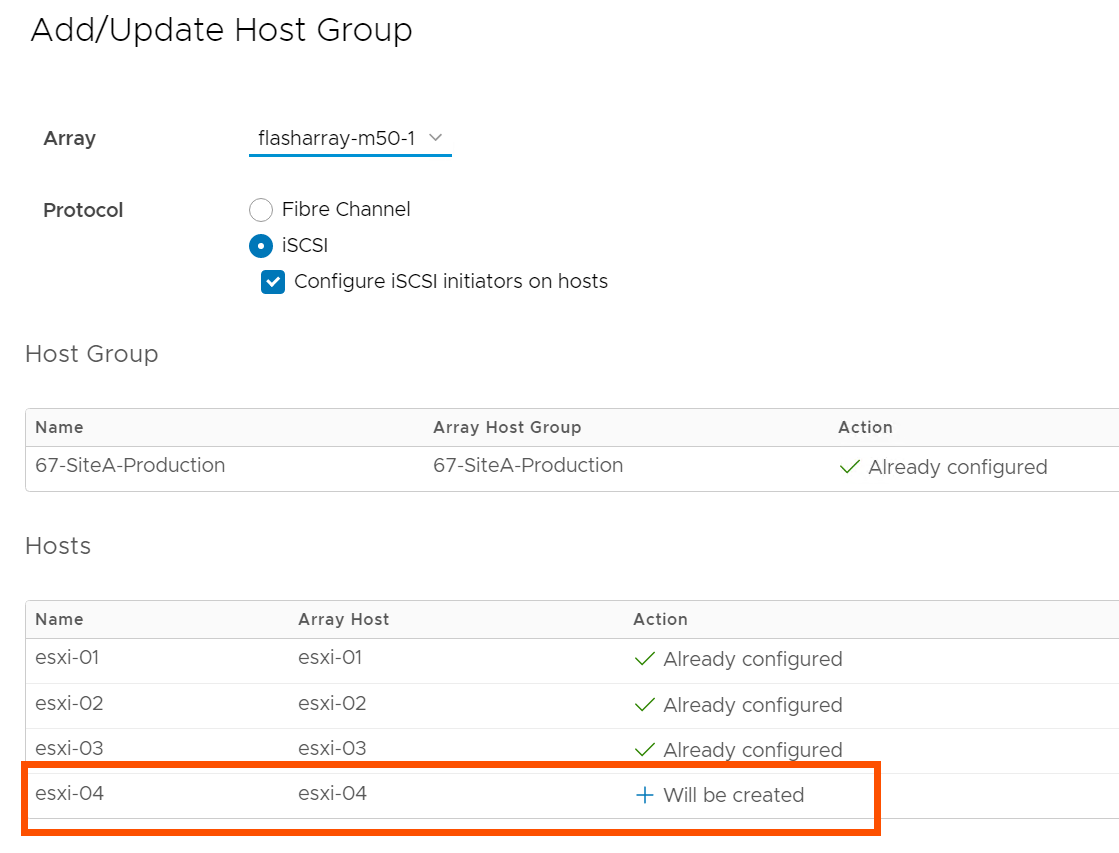
If you’re currently a Pure customer, you have likely managed your host and host group objects directly from the array. Did you know you can also do this from the vSphere plugin without having to copy over WWNs/IPs manually? (1) Right-click on the ESXi cluster you want to create/manage a host or host group object on, (2) hover over Pure Storage, then (3) left-click on Add/Update Host Group.
In this menu, there are currently Fibre Channel and iSCSI protocol configuration options. We are currently exploring options here for NVMe-oF configuration; stay tuned by following this KB. You can also check a box to configure your ESXi hosts for Pure’s best practices with iSCSI, making it so you don’t have to manually configure new iSCSI ESXi hosts.
FlashArray VMFS Datastore and Volume Management(Creation and Deletion)
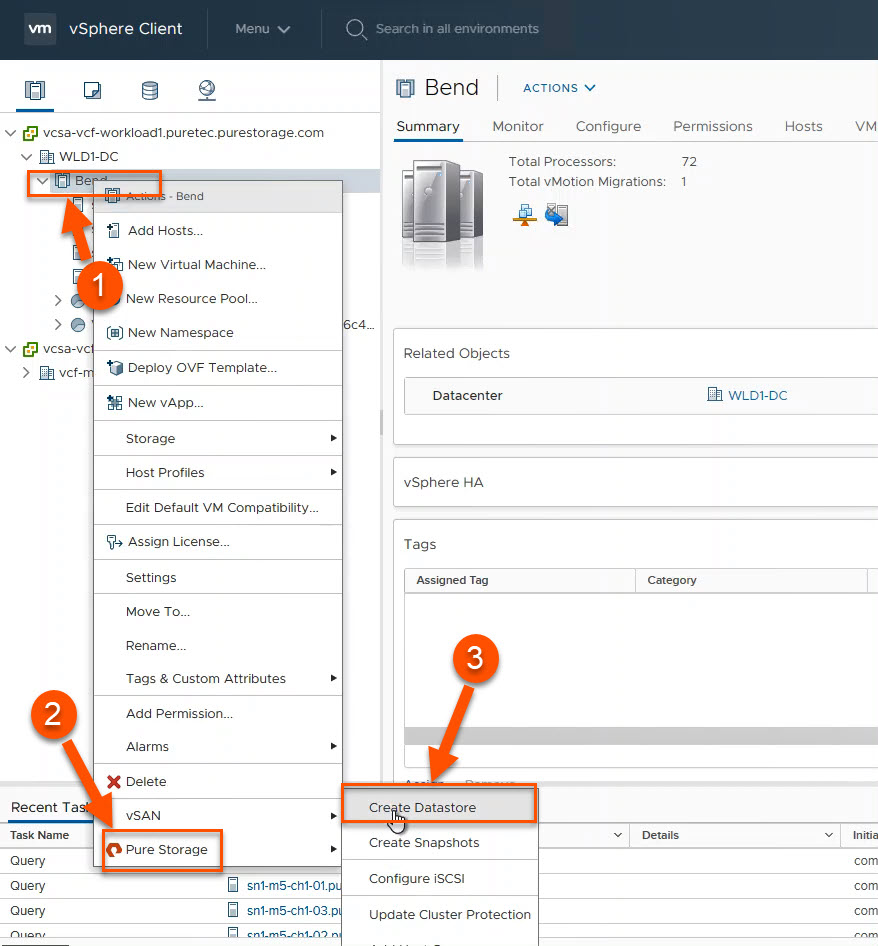
When you use the plugin for datastore creation, the plugin will create the appropriate datastore in vSphere, the volume on the FlashArray, and it will connect the volume to the appropriate host(s) and host group objects on the FlashArray. (1) Right-click on the pertinent cluster or host object in vSphere, (2) hover over Pure Storage and finally (3) left-click on Create Datastore. This will bring up a wizard with a lot of options that I won’t cover here, but the end result will be a datastore that has a FlashArray volume backing it.
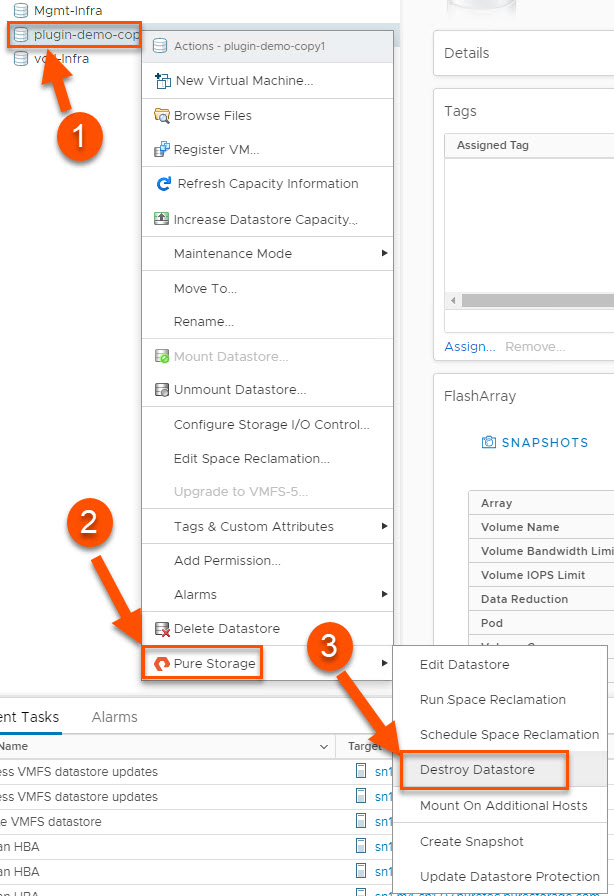
The great thing about deleting a datastore from the plugin is that there are no additional steps required on the array to clean up the objects. This is the most satisfying workflow for me personally because cleanup in a lab can feel like it’s not a good use of time until I’ve got hundreds of objects worth cleaning up. This workflow enables me to quickly clean up every time after I’ve completed testing instead of letting this work pile up.
(1) Right-click the datastore you want to delete, (2) hover over Pure Storage and (3) left-click on Destroy Datastore. After the confirmation prompt, the FlashArray volume backing that datastore will be destroyed and is pending eradication for whatever that value is configured on the FlashArray (default 24 hours, configurable up to 30 days with SafeMode). That’s it!
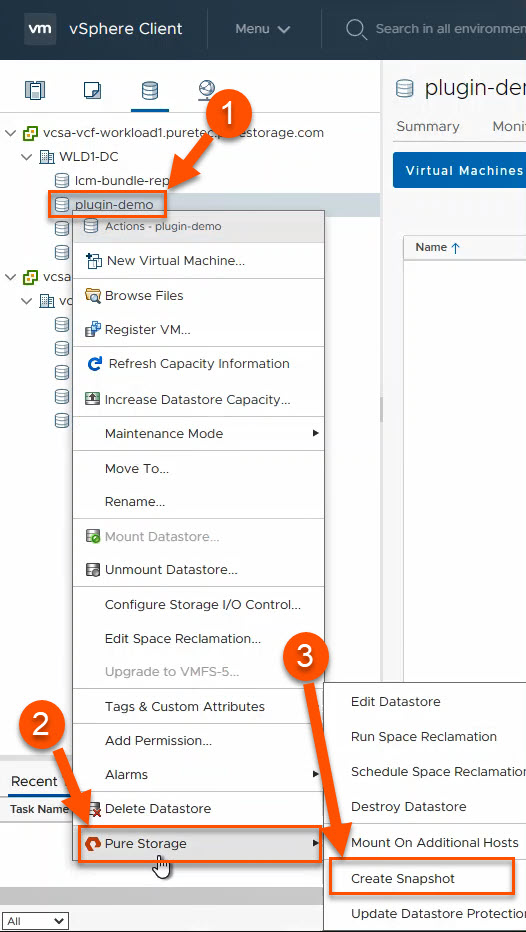
FlashArray Snapshot Creation
One of the benefits of FlashArray is its portable and lightweight snapshots. The good news is that you can create these directly from vSphere without having to log into the FlashArray. It’s worth mentioning that although the snapshot recovery workflows built into the vSphere plugin (vVols and VMFS) are far more powerful and useful when you really need them, I’m covering what I use regularly and I rarely have to recover from snapshots in my lab. I try to take snapshots every time I make a major change to my environment in case I need to quickly roll-back.
There are two separate workflows for snapshot creation: one for VMFS and one for vVols. The granularity advantage with vVols over VMFS is very clear here- with VMFS, you are taking snapshots of the entire VMFS datastore, no matter how many VMs or disks are attached to those VMs. With vVols, you only have to snapshot the volumes you need to, as granular as a single disk attached to a single VM.
With VMFS, (1) right click on the datastore, (2) hover over Pure Storage and (3) left click on Create Snapshot.
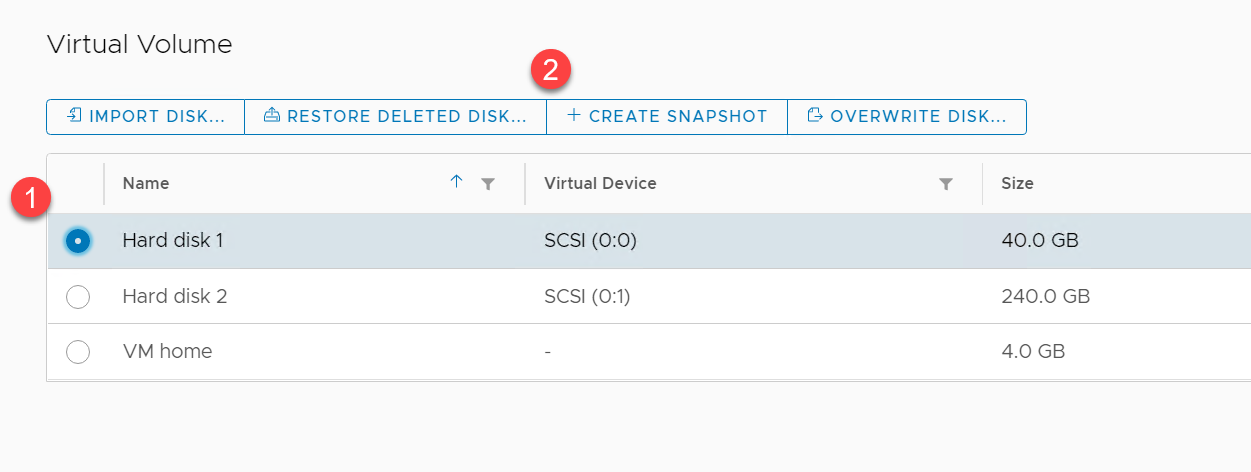
For a vVols backed disk, from the Virtual Machine Configure tab, navigate to the Pure Storage – Virtual Volumes pane, (1) select the disk you would like to snapshot and (2) click Create Snapshot.
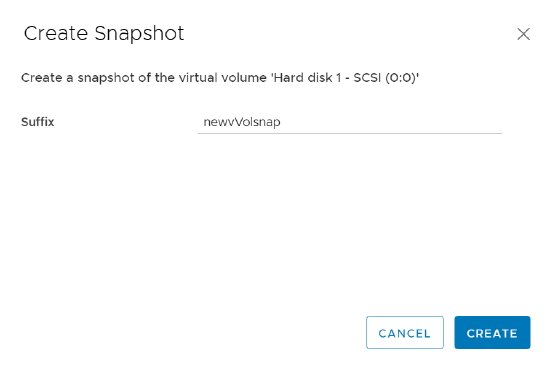
A prompt will pop up to add a suffix to the snapshot if you’d like; click on create and you’ve got your FlashArray snapshot of a vVols backed disk created!
Stay tuned for a blog on the vSphere plugin features you might not know about that, like the above, can save you a significant amount of time and effort.
This is going to be broken up into two parts- first, a live migration where no VMs get powered off during the migration; second, a migration where you temporarily power off VMs attached to the SCSI datastore.
Why would you want to do it one way or another?
Pros of live migration:
No VM downtime
Simpler configuration changes and overlap. Less to go wrong or mess up
Pros of powering off VMs:
The total migration time will be significantly less because no data will have to be moved. Currently VMware doesn’t support XCOPY (even on the same array) for NVMe-oF
Hello- Nelson Elam, a Solutions Engineer on Cody’s team at Pure, guest-writing here again.
If you are a current Pure customer and have had ESXi issues that warranted you checking the vmkernel logs of a host, you may have noticed a significant amount of messages similar to this for SCSI:
Cmd(0x45d96d9e6f48) 0x85, CmdSN 0x6 from world 2099867 to dev "naa.624a9370f439f7c5a4ab425000024d83" failed H:0x0 D:0x2 P:0x0 Valid sense data: 0x5 0x20 0x0
Or this for NVMe-oF:
WARNING: NvmeScsi: 172: SCSI opcode 0x85 (0x45d9757eeb48) on path vmhba67:C0:T1:L258692 to namespace eui.00f439f7c5a4ab4224a937500003f285 failed with NVMe error status: 0x1 translating to SCSI error
ScsiDeviceIO: 4131: Cmd(0x45d9757eeb48) 0x85, CmdSN 0xc from world 2099855 to dev "eui.00f439f7c5a4ab4224a937500003f285" failed H:0x0 D:0x2 P:0x0 Valid sense data: 0x5 0x20 0x0
If you reached out to Pure Storage support to ask what the deal is with this, you were likely told that these are 0x85s and nothing to worry about because it’s a VMware error that doesn’t mean anything with Pure devices.
But why would this be logged and what is happening here?
ESXi regularly checks the S.M.A.R.T. status of attached storage devices, including for array-backed devices that aren’t local. When the SCSI command is received on the FlashArray software, it returns 0x85 with the following sense data back to the ESXi host:
failed H:0x0 D:0x2 P:0x0 Valid sense data: 0x5 0x20 0x0
These can be quite challenging to decode. Luckily, virten.net has a powerful tool for decoding these. When I paste this output into that site, I get the following details:
Type
Code
Name
Description
Host Status
[0x0]
OK
This status is returned when there is no error on the host side. This is when you will see if there is a status for a Device or Plugin. It is also when you will see Valid sense data instead of Possible sense Data.
Device Status
[0x2]
CHECK_CONDITION
This status is returned when a command fails for a specific reason. When a CHECK CONDITION is received, the ESX storage stack will send out a SCSI command 0x3 (REQUEST SENSE) in order to get the SCSI sense data (Sense Key, Additional Sense Code, ASC Qualifier, and other bits). The sense data is listed after Valid sense data in the order of Sense Key, Additional Sense Code, and ASC Qualifier.
Plugin Status
[0x0]
GOOD
No error. (ESXi 5.x / 6.x only)
Sense Key
[0x5]
ILLEGAL REQUEST
Additional Sense Data
20/00
INVALID COMMAND OPERATION CODE
The key thing here is the Sense Key which has a value of ILLEGAL REQUEST. The FlashArray software does not support S.M.A.R.T. SCSI requests from hosts, so the FlashArray software returns ILLEGAL REQUEST to the ESXi host to tell the host we don’t support that request type.
This is for two reasons:
1. Since the FlashArray software’s volumes are not a physically attached storage device on the ESXi host, S.M.A.R.T. from the ESXi host doesn’t really make sense. 2. The FlashArray software handles drive failures and drive health independent of ESXi and monitoring the health of these drives that back the volumes is handled by the FlashArray software, not ESXi. You can read more about this in this datasheet.
Great Nelson, thanks for explaining that. Why are you talking about this now?
Pure has been working with VMware to reduce the noise and unnecessary concern caused by these errors. Seeing a failed ScsiDeviceIO in your vmkernel logs is alarming. In vSphere 7.0U3c, VMware fixed this problem and this will now only log once this when the ESXi host boots up instead of as often as every 15 minutes.
This means that in vSphere 7.0U3c if you are doing any ESXi host troubleshooting you no longer have to concern yourself with these errors; for me, this means I won’t have to filter these out in my greps anymore when looking into an ESXi issue in my lab. Great news all around!
In the world of SCSI, a storage device is generally addressed by two things:
LUN–Logical Unit Number. This is a number used to address the device down a specific path to a specific array, for a specific host. So it is not a unique number really, it is not guaranteed to be unique to an array, to a host, or a volume. So for every path to a volume there could be a different LUN number. Think of it like a street address. 100 Maple St. There are many “100 Maple Streets”. So it requires the city, the state/province/etc, the country to really be meaningful. And a street name can change. So can other things. So it can usually get you want you want, but it isn’t guaranteed.
Serial number. This is a globally unique identifier of the volume. This means it is entirely unique for that volume and it cannot be change. It is the same for everyone and everything who uses that volume. To continue our metaphor, look at it like the GPS coordinates of the house instead of the address. It will get you where you need, always.
So how does this change with NVMe? Well these things still exist, but how they interact is…different.
Now, first, let me remind that generally these concepts are vendor neutral, but how things are generated, reported, and even sometimes named vary. So I write this for Pure Storage, so keep that in mind.
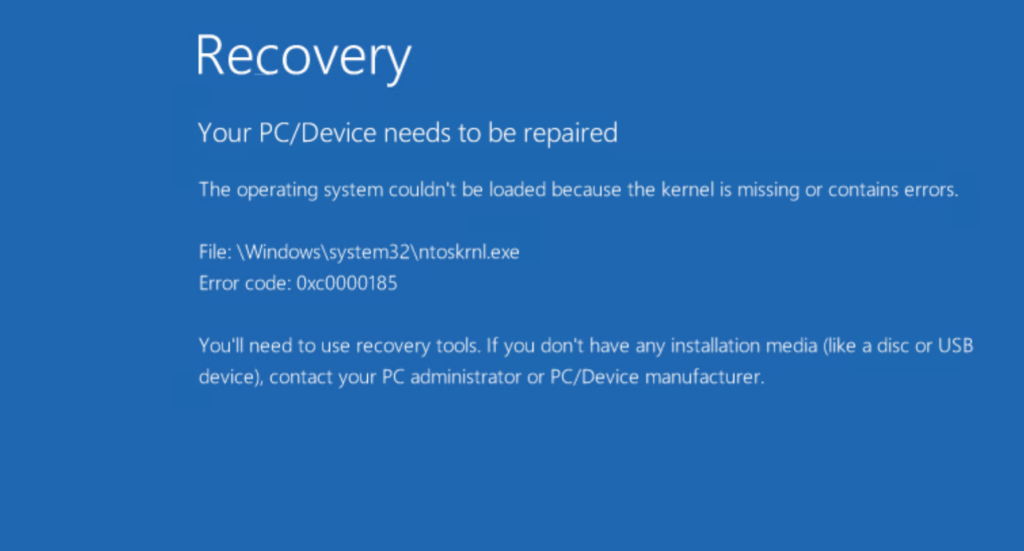
While the title of this post does sound like a halfway decent Harry Potter novel, this is far more nefarious. Pure Storage, like many other vendors have a best practice around lowering the Disk.DiskMaxIOSize setting on ESXi hosts when using UEFI boot for your Windows VMs. Why? Well:
Yes not having it set in a few situations would cause BSOD. First off, why?
In normal scenarios, you may not see much of a performance difference between the standard IOPS switching-based policy and the latency one. So don’t necessarily expect that switching policies will change anything. But then again, multipathing primarily exists not for healthy states, but instead exists to protect during times of poor health. Continue reading “Latency-based PSP in ESXi 6.7 Update 1: A test drive”