
Here is another “look what I found” storage-related post for vSphere 6. Once again, I am still looking into exact design changes, so this is what I observed and my educated guess on how it was done. Look for more details as time wears on.
***This blog post really turned out longer than I expected, probably should have been a two parter, so I apologize for the length.***
Like usual, let me wax historical for a bit… A little over a year ago, in my previous job, I wrote a proposal document to VMware to improve how they handled XCOPY. XCOPY, as you may be aware, is the SCSI command used by ESXi to clone/Storage vMotion/deploy from template VMs on a compatible array. It seems that in vSphere 6.0 VMware implemented these requests (my good friend Drew Tonnesen recently blogged on this). My request centered around three things:
- Allow XCOPY to use a much larger transfer size (current maximum is 16 MB) a.k.a, how much space a single XCOPY SCSI command can describe. Things like Microsoft ODX can handle XCOPY sizes up to 256 MB for example (though the ODX implementation is a bit different).
- Allow ESXi to query the Maximum Segment Length during an Extended Copy (XCOPY) Receive Copy Results and use that value. This value tells ESXi what to use as a maximum transfer size. This will allow the end user to avoid the hassle of having to deal with manual transfer size changes.
- Allow for thin virtual disks to leverage a larger transfer size than 1 MB.
The first two are currently supported in a very limited fashion by VMware right now, (but stay tuned on this!) so for this post I am going to focus on the thin virtual disk enhancement and what it means on the FlashArray.
So the first thing to understand is why an enhancement specific to thin virtual disks? Let’s describe the problem.
XCOPY is a SCSI command that tells an underlying array to move or copy certain blocks from one place to another, either internal to that device or another device on that array. This is what VMware uses to move/clone a virtual machine (well, really virtual disks). XCOPY uses what VMware refers to as a transfer size to control how much physical space a single XCOPY command can describe. Note–this is not how big the XCOPY command itself is–this is how much space it describes (the payload is not the data itself, the payload is the location of the data). This size is controlled by a setting on ESXi called the MaxHWTransfer size. This is at a default of 4 MB and can be either decreased or raised up to a maximum of 16 MB.

So why would this value need to be changed? The reason comes down to the architecture of the specific array and how it manages XCOPY sessions. A few arrays are best with the default, a few arrays are better with a smaller size and I’d say the majority prefer the transfer size to be as large as possible. A quick Google search seems to verify that.
On the FlashArray, the larger the better. The array is so good at handling XCOPY, that the bottleneck is really how quickly the ESXi host can issue all of the XCOPY commands to fully describe the given virtual machine’s virtual disk(s). So essentially, if a single XCOPY command can describe more space, less XCOPY commands are needed, and therefore it takes less time to issue all of the commands needed and the XCOPY operation is faster.
This is why we recommend upping the value of MaxHWTransferSize to the ceiling of 16 MB. Granted, upping the transfer size from 4 to 16 MB is not going to give you 4x the performance–note that this number is a maximum allowance for the transfer size, not an absolute static size. You really will not see a noticeable difference between 4 and 16 MB until you start cloning at scale (VDI deployments etc.).
So, again, why am I targeting thin virtual disks? The above option MaxHWTransferSize in vSphere 5.x only matters when it comes to ZeroedThick or EagerZeroedThick virtual disks. Thin virtual disks instead use a maximum transfer size that is dictated by the block size of the VMFS datastore on which it resides. For VMFS 5 the block size, with very few exceptions, is 1 MB. Therefore, thin virtual disks are limited to XCOPY transfer sizes of 1 MB–much smaller than what thick-type virtual disks can leverage. Thus, the time it takes to complete XCOPY-based sessions with thin virtual disks can be significantly longer than with thick.
There is a KB from VMware that alludes to this–not particularly informative but it is centered around this issue.
The next question, or arguably the main question is why can it not use a larger transfer size? Well, this is a complicated answer, but part of it is that ESXi cannot guarantee that thin virtual disks are going to use contiguous blocks–as by design thin virtual disks allocate blocks on command. Unlike its thick counterparts. Therefore, the work to find and include non-contiguous blocks in one XCOPY command may not really be worth it just to use a larger XCOPY transfer size.
What’s in vSphere 6?
In vSphere 6.0 this has been improved. Yay!
If I create a new virtual machine that leverages thin virtual disks, fill it with and OS/data then turn it into a template and then deploy VM from that template it is still relatively slow, when compared to a template of the same size using a thick type of virtual disk. This remains true in vSphere 6.0. But what is interesting is that if I clone that template and then deploy a new VM from the new cloned template the “deploy from template” process is much faster. It is now in line with a template that is using thick-type virtual disks. Let’s take a look.
I built a few Windows 2012 R2 virtual machines and loaded them with about 65 GB of data–the exact same dataset for the most part. One with a thin virtual disk and one with eagerzeroedthick virtual disks.
When I turned them into a template and deployed a virtual machine from each the eagerzeroedthick template took about 13 seconds to deploy. When I did it with the thin virtual disk template it took about 46 seconds:

If we look at esxtop, the XCOPY information is also drastically different.
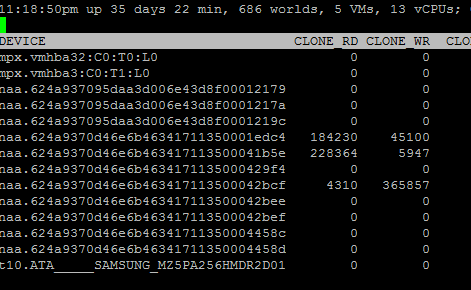
The eagerzeroedthick virtual disk template executed around 4,200 Write XCOPY commands and 4,000 Read XCOPY commands. If you do the math, this averages out to just under 16 MB transferred per XCOPY command listed in esxtop. Which makes sense as the MaxHWTransferSize is set to 16 MB.
For the thin virtual disk template, about 44,000 XCOPY commands were generated for the deploy process. This averages out to about 1.5 MB per XCOPY command. This explains the time difference (46 seconds compared to 13). It also indicates that there might be times where thin virtual disks in vSphere 6 right out of the box (without even this “defrag” optimization) can use a semi-larger transfer size since it is a bit bigger than the 1 MB block size.
So now if I take that thin virtual disk template and then clone it to a new template, the results are remarkably similar to eagerzeroedthick. Takes about 11 seconds and issues about 4,400 XCOPY commands. Making it use a 16 MB transfer size essentially.

So it seems that during a migration/clone process VMware does some work with thin virtual disks to allow them to use larger XCOPY transfer sizes in any subsequent migration/clone. My first guess is that the virtual disk essentially is fragmented during data placement, and the Storage vMotion/Clone/Deploy now actually defrags it in vSphere 6–allowing for contiguous VMFS block placement and therefore larger transfer sizes. Any XCOPY migration will allow subsequent sessions to be faster. So I can:
- Clone a VM from that template and then deploy from that to leverage larger transfer size from then on.
- Clone that template to a new template and all deployments from that new template will use a larger transfer size (note all deployments from the old one will still use the smaller transfer size).
- Turn the template back into a VM and storage vMotion it to another datastore. The migrated template will now allow for faster deployments from it.
Also note that if I drop the MaxHWTransferSize down to 8 MB both the eagerzeroedthick virtual disk template and the thin virtual disk template send around 8,700 XCOPY commands for a 8 MB average–so the thin virtual disk change does indeed seem to adhere to limits set in the MaxHWTransferSize.
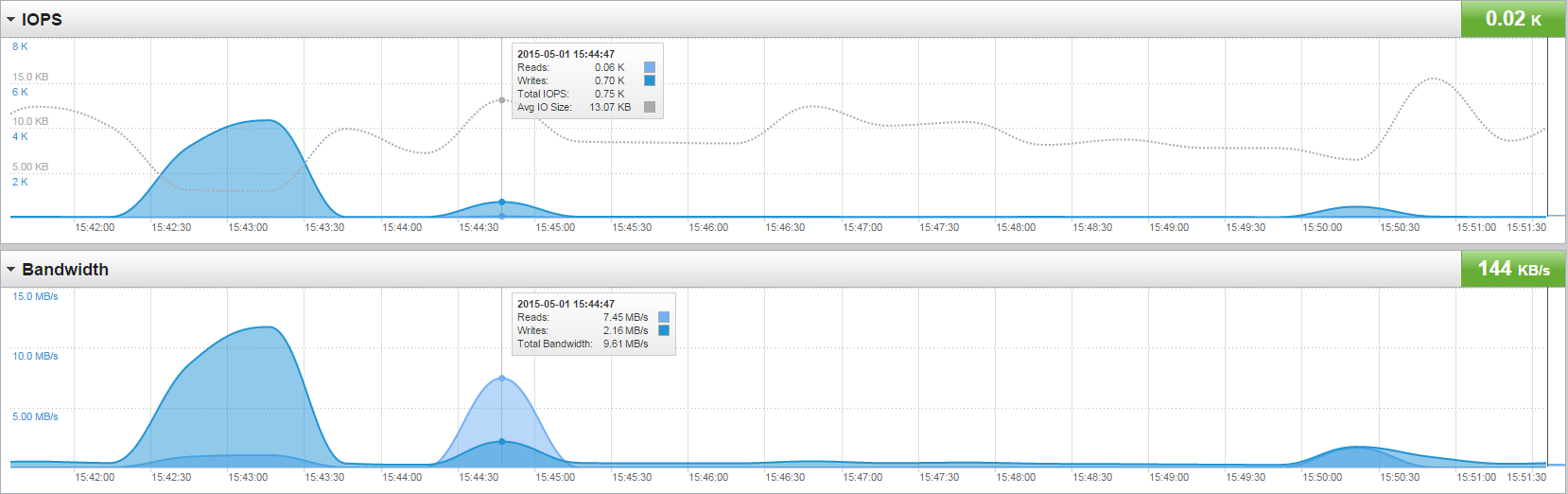
See the below array performance chart for these operations. There are three bumps, they describe the following operations respectively:
- Clone a thin template into a new template. This operation uses the 1 MB transfer size and takes the longest. But it is the operation that “cleans” it up.
- Deploy a VM from that new template. This uses the larger transfer size, is faster, and requires less IOPS and throughput.
- Deploy a VM from the eagerzeroedthick template. This takes about the same amount of time but does have even less than the “improved” thin deployment. So it seems the ESXi host still has to do a bit more work with thin.
What about non-XCOPY clones/migrations?
On a hunch I decided to look into whether or not this change could affect non-XCOPY clones. And indeed it does seem to! Taking two identical VMs, one that was not “defragged” by a clone operation and another one that was, I saw a 17% decrease in migration time from one array to another (XCOPY can’t be used when the source and target are on different arrays).

Looking at the array performance statistics, the IOPS remained pretty much the same but the throughput was higher with the “defragged” VMs, which is a function of the fact that the I/O size was higher for the “defragged” VM. ~52 KB as compared to ~63 KB and 325 MB/s as compared to 400 MB/s.
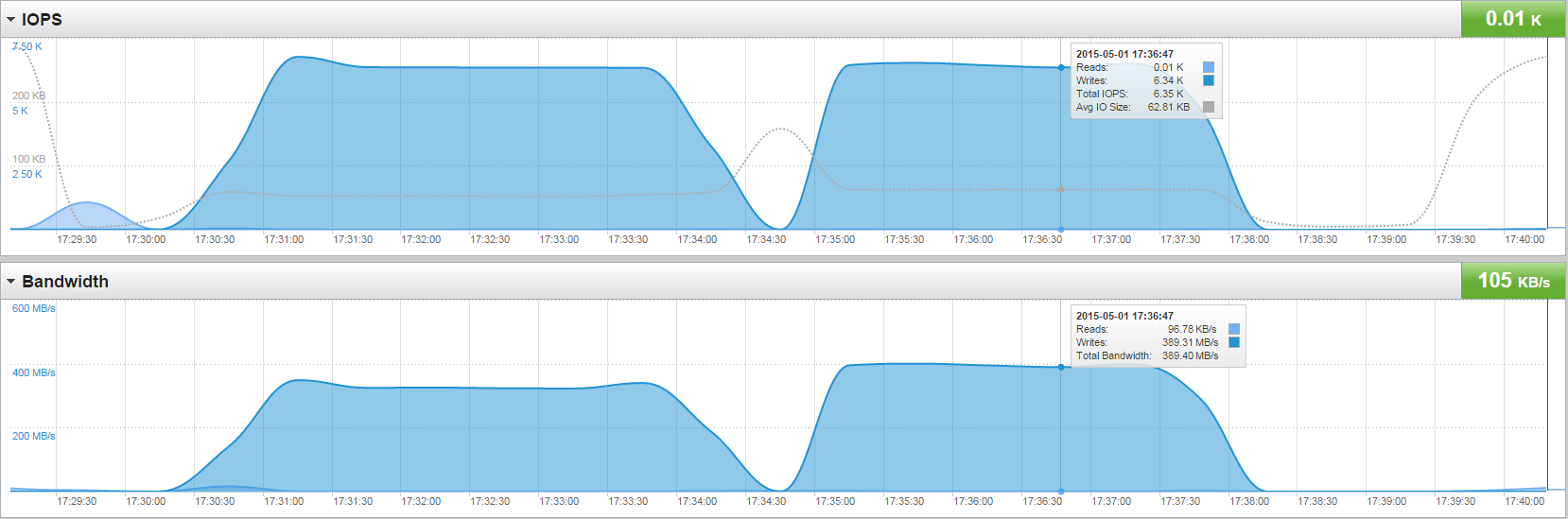
Kind of interesting. I’d be curious if others can re-create this result too. In my testing this also helps with non-XCOPY Storage vMotions as well with the same % improvement.
Doublechecking with vSphere 5.5
So I decided to sanity check with vSphere 5.5 U2 and run the same tests. This behavior is definitely not in 5.5 U2. Deploying a VM from a thin virtual disk template is slow no matter what–cloning it does not help. And is actually much slower even initially. So it seems that they have improved performance of XCOPY with Storage vMotion/Clone in vSphere 6.0 even without that “defrag” procedure.
When I followed esxtop in 5.5 for a deploy from template operation there were 69,231 XCOPY commands sent out, which for 65 GB of data is less than 1 MB average transfer size. In vSphere 6.0 it sent out about 44,000, which indicates that even fragmented thin virtual machines can indeed leverage somewhat larger transfer sizes now out of the box, when in vSphere 5.5 they could never. In review, and for a quick comparison of deployment times see the following chart:
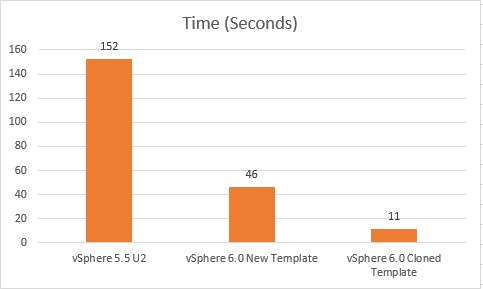
Essentially the same virtual machine takes wildly different times. They definitely did some good stuff in vSphere 6.
Final Thoughts…
Looks like this “defrag” process allows for both larger transfer sizes with thin XCOPY and larger general I/O sizes with non-XCOPY operations.
So all situations with the copying/deploying/migrating of thin virtual disk VMs are improved. And running one of those procedures once, improves it even more. I’d say if you have thin templates–clone them to a new template and use those instead–this will speed things up a lot for you if you are using vSphere 6.0. For VMs that aren’t templates, it doesn’t really make sense to Storage vMotion it just to speed up a subsequent one, but it might make a little sense if you are planning on moving it to another array shortly which will not use XCOPY.
So between this change and the new guest OS UNMAP support, this really makes thin virtual disks a bit more attractive. Look for a new post soon ruminating over these new considerations.
Once again, all of this is pretty much anecdotal–I haven’t gotten all of the details on these changes yet from VMware. For all I know my “defrag” analogy may be way off base, but I think it is probably at least an apt description. I imagine there are more than just one enhancements involved here to achieve this. Look for updates on this front as well.
Definitely time to update my Pure Storage VAAI White Paper. Add that to the queue…
Great post, Cody.
Thank you!