
Finally starting to catch up on work after VMworld. A lot of blog posts queued up in my head that I want to start getting out. Here is the first. I have completed an update of the FlashArray workflow package with some bug fixes and some new workflows. As always the workflow package can be found here:
https://github.com/codyhosterman/orchestrator/blob/master/com.purestorage.codyhosterman.package
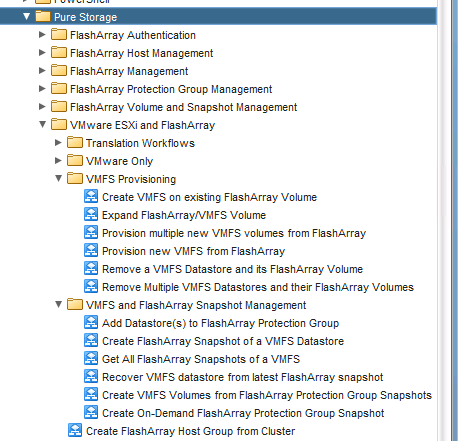
So what is in this release? First a few minor fixes:
- The Enable Remote Assist workflow had incorrect REST body content. This has been fixed.
- The Provision new VMFS on new FlashArray volume workflow didn’t work with FCoE devices–I have changed the code to be more flexible, so it will work with FC or FCoE. It still does not support iSCSI though.
- Some minor error handling improvements
Now for new features:
- vCenter Cluster to FlashArray host group translator workflow. Give it a vCenter Cluster and and a FlashArray and it will then give you the corresponding host group (if it exists). This requires a hard match, the host group must have the same number of hosts and the WWNs must match exactly. This will make creating your own provisioning workflows much easier. The input is a VC:computeCluster and a REST target (a FlashArray). It returns the host group name as a plain text string. This does not support iSCSI.
- Resignature one or more VMFS volumes. When you copy a VMFS with array based technology (snapshot or replication) the new VMFS copy is seen as invalid because its signature does not match the physical device serial number. So it needs to be given a new signature that matches before it can be used. This takes in one or more NAAs (one for each VMFS you want to resignature) and returns an array of datastore objects (VC:datastore).
- FlashArray Protection Group restore. This takes in a FlashArray and a protection group name and then find the latest snapshot group and restores volumes from each snapshot. So if a snapshot group has three snapshots in it, the workflow will create three new volumes. Returns an array of volume properties–the volumes that were created.
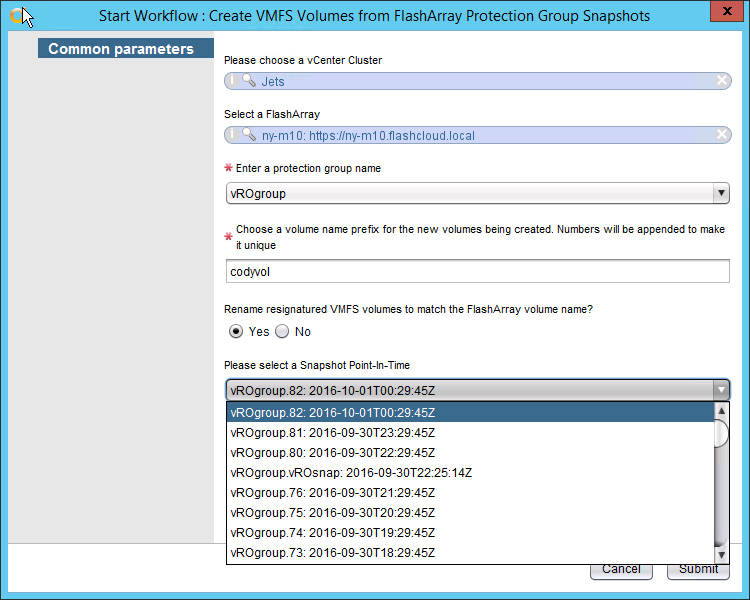
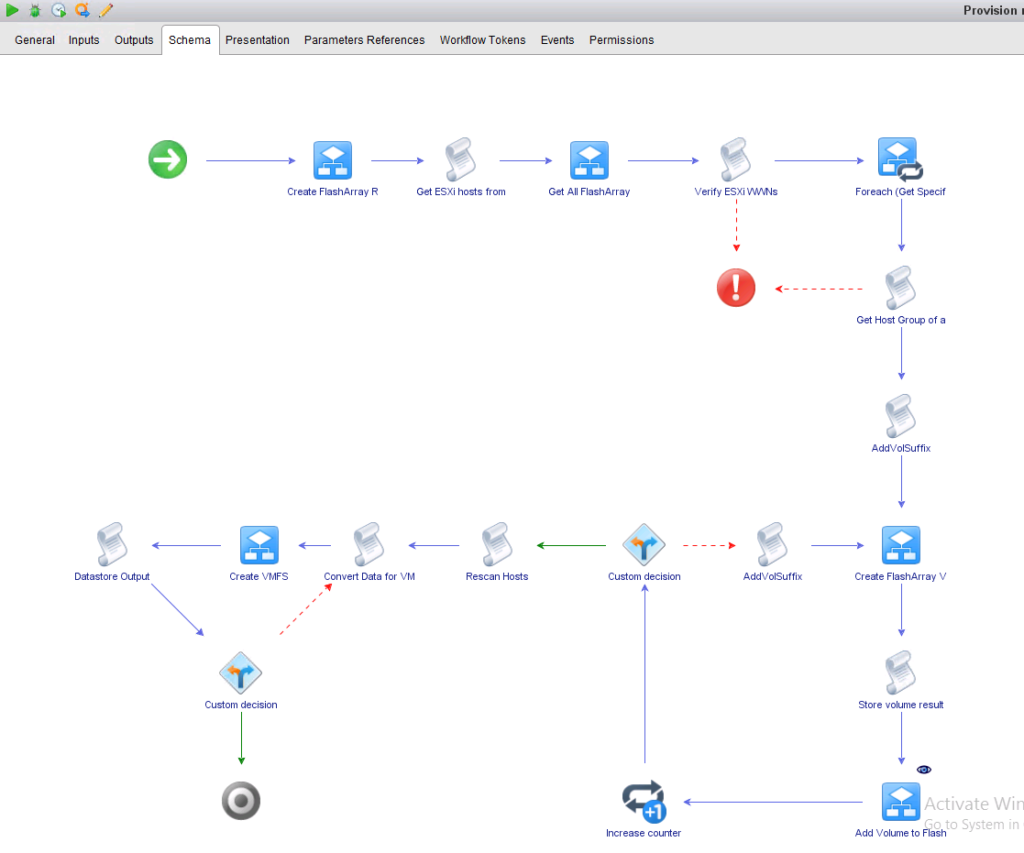
- VMFS restore from a FlashArray Protection Group. Takes the workflow above and adds VMware automation to it. This assumes that there are VMFS volume copies in each of those snapshots, so it also takes in a vCenter cluster. It then also uses the host group translator workflow from above and connects all of the volumes to the right host group. It then resignatures all of the volumes. It will also rename the newly resignatured volumes to the names of the volumes created on the FlashArray from the snapshots. This can optionally be turned off, so it just uses the default resignature name. Also supply a prefix for the new FlashArray volumes to be used. Numbers will be appended to make each unique. This works with local snapshots in a protection group or replicated ones in a remote protection group. The cool thing is that the wizard uses some new actions (I will talk about a bit later) I wrote to make a dynamic drop down of both protection groups (displays all protection groups on the selected FlashArray) and then all of the snapshot group in that protection group–displaying the time stamp of it and the name. The basic workflow in number 3 above uses the same wizard features.
- Provision multiple new VMFS volumes at once. One of the first workflows I wrote was provisioning a new VMFS on a new volume. This workflow does that but in a batch. So if you want to create five volumes (or however many) you can give a volume prefix name and it will assign numbers to make them unique. Takes in a cluster and a FlashArray and a volume prefix and size. It creates the volumes, connects them to the right host group, rescans the hosts, and then formats all of the volumes as VMFS.
- Remove VMFS volume workflow. Give it a datastore and it will unmount it from all of its ESXi hosts, detach it from them, then disconnect it on the FlashArray and then deletes it. The cluster is refreshed to remove the volume. There is also a remove multiple volumes at once version. This can take in one or more datastores on one or more respective FlashArrays and then remove them.
- Create on-demand snapshot of a protection group workflow.
- Enhancements to the wizards of many of the workflows. You no longer have to enter in 8T for a 8 TB volume, instead type a number and a capacity unit in the drop down.
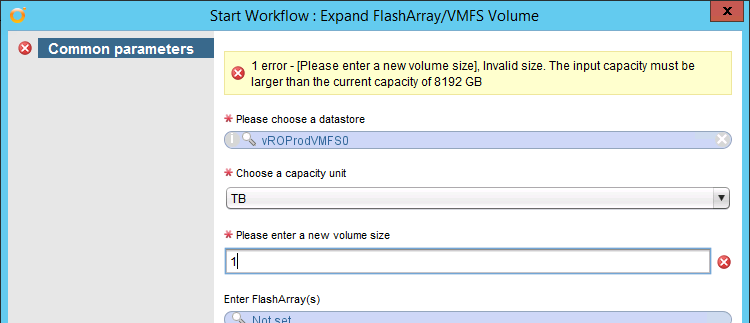
Also the expand VMFS worfklow now checks first thing that the new capacity is bigger than the current one, instead of just failing in the middle of the process like before.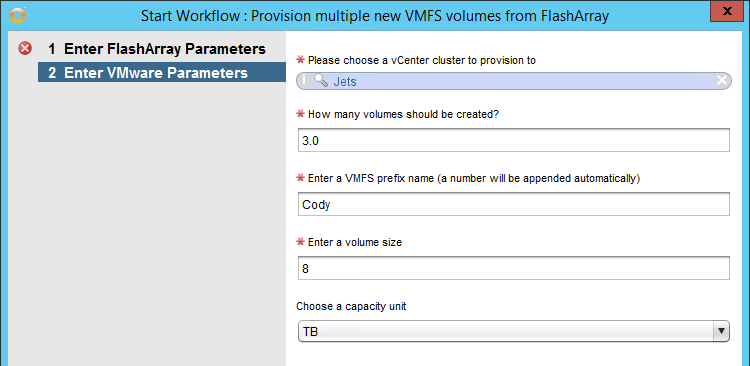
- Actions! This is what i should have done from the start instead a lot of the other workflows that really should be actions.
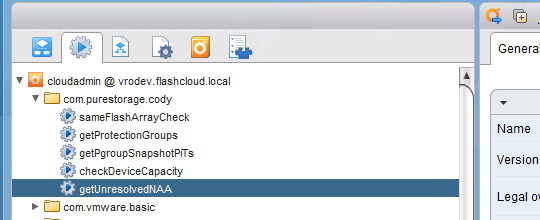
sameFlashArrayCheck simply takes in a few datastores and returns whether they are on the same array or different ones. This is useful for vRO custom validation where you might want to make sure immediately all of the datastores are on the same FlashArray.
getProtectionGroups. Returns the names of all of the protection groups on a given FlashArray
getPgroupSnapshotPiTs. Returns all of the snapshot names and their timestamps of a given protection group. Useful for VMFS recovery or copying workflow predefined OGNL inputs. (I am going to blog in more detail on this shortly)
checkDeviceCapacity, takes in a datastore and a capacity and makes sure that the new capacity is larger. Used in my expand VMFS workflow.
getUnresolvedNaa. Returns an array of string NAA numbers for any devices that contain unresolved VMFS volumes for a given ESXi host.
One note on the dynamic inputs. It slows down the wizard a decent amount until the pre-requisite information is populated (username/password for instance). From my reading this is a vRO GUI bug. This does not affect response time in vRA or the vSphere Web Client if you run it from there. I found changing the username and password from “inputs” to “attributes” and hard coding the values this issue went away.
See below for a video on this release. This shows:
- Creating multiple new VMFS volumes at once
- Adding them to a protection group
- Taking a protection group snapshot
- Recovering dev/test copies of those snapshots
- Deleting those dev/test copies at once