
So as you might be aware, vSphere 6.5 just went GA.
There is quite a bit of new stuff in this release and there have certainly been quite a few blogs concerning the flagship features. I want to take some time to dive into some new core storage features that might be somewhat less heralded. Let’s start with my favorite topic. UNMAP.
There are a couple of enhancements in space reclamation in ESXi 6.5:
- Automatic UNMAP. This is the big one.
- Linux-based In-Guest UNMAP support
Automatic UNMAP
This is something that was once in existence back in ESXi 5.0, but was withdrawn for a variety of reasons. It is finally back! Yay!
So let’s talk about what it requires:
- ESXi 6.5+
- vCenter 6.5+
- VMFS 6
- An array that supports UNMAP
So first, let’s take a look at turning it on. The feature can be seen on the “Configure” tab on the datastore object in vCenter:
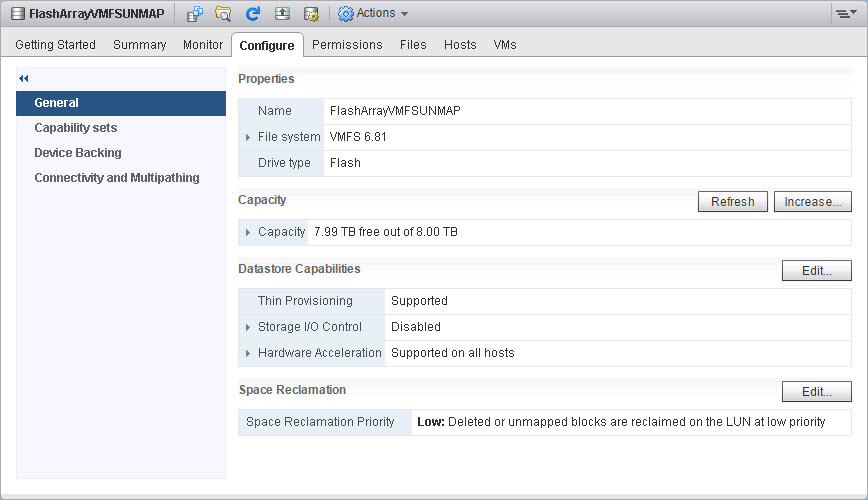
When you click the “Edit” button, you can turn UNMAP on or off. The default is on.
You can also configure it with esxcli:

Now there is a bit of confusion with the settings here. The almost GA version I have still allows you to set UNMAP to low, medium, and high. My sources at VMware tell me that only low is currently implemented in the kernel, so changing this to anything but none or low will not affect anything at this time. So keep an eye on this. I need to officially confirm this.
Now the important thing to note is that this UNMAP is asynchronous UNMAP. Meaning space is not reclaimed as soon as you kick off the delete. If you want immediate results, your handy esxcli storage vmfs unmap command will do the trick. Instead they have introduced a crawler, that runs on each ESXi hosts that on certain intervals will run reclamation on datastores to get space back. This is not immediate in any sense. Expect to see results within a day or so. The nice thing is that, dead space will be taken care of–you do not need to worry about it any more from a VMFS perspective.
So how can I tell if it is working? Well since it could happen at any time, this is a bit tougher. Of course, watching your array is an option. Is space going down? If yes, it is likely to be working.
From an ESXi perspective, you can run this on an ESXi server that hosts the volume:
vsish -e get /vmkModules/vmfs3/auto_unmap/volumes/FlashArrayVMFSUNMAP/properties
Volume specific unmap information {
Volume Name :FlashArrayVMFSUNMAP
FS Major Version :24
Metadata Alignment :4096
Allocation Unit/Blocksize :1048576
Unmap granularity in File :1048576
Volume: Unmap IOs :2
Volume: Unmapped blocks :48
Volume: Num wait cycles :0
Volume: Num from scanning :2088
Volume: Num from heap pool :2
Volume: Total num cycles :20225
}
The bold portions will say if anything has been issued to that VMFS. Vsish is not technically supported by VMware, so I am looking for a better option here.
Verifying In-Guest UNMAP Support with Linux
In vSphere 6.0, the ability to reclaim in-guest dead space with native OS UNMAP was introduced. Due to SCSI versioning support, only Windows 2012 R2 was able to take advantage of this behavior.
See this from VMware KB 2112333:
“…Some guest OSes that support unmapping of blocks, such as Linux-based systems, do not generate UNMAP commands on virtual disks in vSphere 6.0. This occurs because the level of SCSI support for ESXi 6.0 virtual disks is SCSI-2, while Linux expects 5 or higher for SPC-4 standard. This limitation prevents generation of UNMAP commands until the virtual disks are able to claim support for at least SPC-4 SCSI commands…”
In vSphere 6.5, SPC-4 support was added enabling in-guest UNMAP with Linux-based virtual machines. So what are the requirements to get this to work?
- ESXi 6.5
- Thin virtual disks
- Guest that supports UNMAP (as well as its filesystem)
First, how do we know it is working? Well there are a couple of ways. Of course you can check the above requirements. But how about from the guest?
So two things. First is it the right type of virtual disk (thin)? This can be achieved with the sg_vpd utility. You want to check the 0xb2 page of the virtual disk. Simplest way is a command like so:
sg_vpd /dev/sdc -p lbpv
Of course replace the device identifier (/dev/sdx).
The property you will look at is “Unmap command supported (LBPU):”.
If it is set to 0, it is thick (eager or sparse):
pureuser@ubuntu:/mnt$ sudo sg_vpd /dev/sdc -p lbpv Logical block provisioning VPD page (SBC): Unmap command supported (LBPU): 0 Write same (16) with unmap bit supported (LBWS): 0 Write same (10) with unmap bit supported (LBWS10): 0 Logical block provisioning read zeros (LBPRZ): 0 Anchored LBAs supported (ANC_SUP): 0 Threshold exponent: 1 Descriptor present (DP): 0 Provisioning type: 0
If it is set to 1 it is thin:
pureuser@ubuntu:/mnt/unmap$ sudo sg_vpd /dev/sdc -p lbpv Logical block provisioning VPD page (SBC): Unmap command supported (LBPU): 1 Write same (16) with unmap bit supported (LBWS): 0 Write same (10) with unmap bit supported (LBWS10): 0 Logical block provisioning read zeros (LBPRZ): 1 Anchored LBAs supported (ANC_SUP): 0 Threshold exponent: 1 Descriptor present (DP): 0 Provisioning type: 2
Also provisioning type seems to be set to 2 when it is thin, but I haven’t done enough testing or investigation to confirm that is true in all cases.
This will still report as 1 in ESXi 6.0 and earlier, just UNMAP operations do not work due to the SCSI version. So how do I know the SCSI version? Well sg_inq is your friend here. So, run the following, once again replacing your device:
sg_inq /dev/sdc -d
On a ESXi 6.0 virtual disk, we see this:
pureuser@ubuntu:/mnt/unmap$ sudo sg_inq /dev/sdc -d standard INQUIRY: PQual=0 Device_type=0 RMB=0 version=0x02 [SCSI-2] [AERC=0] [TrmTsk=0] NormACA=0 HiSUP=0 Resp_data_format=2 SCCS=0 ACC=0 TPGS=0 3PC=0 Protect=0 [BQue=0] EncServ=0 MultiP=0 [MChngr=0] [ACKREQQ=0] Addr16=0 [RelAdr=0] WBus16=1 Sync=1 Linked=0 [TranDis=0] CmdQue=1 length=36 (0x24) Peripheral device type: disk Vendor identification: VMware Product identification: Virtual disk Product revision level: 1.0
Note the version on the top and the virtual disk revision level (SCSI 2 as well as revision level 1). Now for a virtual disk in 6.5:
pureuser@ubuntu:/mnt$ sudo sg_inq -d /dev/sdb standard INQUIRY: PQual=0 Device_type=0 RMB=0 version=0x06 [SPC-4] [AERC=0] [TrmTsk=0] NormACA=0 HiSUP=0 Resp_data_format=2 SCCS=0 ACC=0 TPGS=0 3PC=0 Protect=0 [BQue=0] EncServ=0 MultiP=0 [MChngr=0] [ACKREQQ=0] Addr16=0 [RelAdr=0] WBus16=1 Sync=1 Linked=0 [TranDis=0] CmdQue=1 length=36 (0x24) Peripheral device type: disk Vendor identification: VMware Product identification: Virtual disk Product revision level: 2.0
SCSI version 6 and SPC-4 compliancy! Sweeeet. Also product revision level 2–this is the first revision of the virtual disk level I have seen. In 6.5 it is now two. This has to do with the SCSI version increase.
Okay. We have identified that we are supported. How does it work?
Executing In-Guest UNMAP with Linux
So there are a few options for reclaiming space in Linux:
- Mounting the filesystem with the discard option. This reclaims space automatically when files are deleted
- Running sg_unmap. This allows you to run UNMAP on specific LBAs.
- Running fstrim. This issues trim commands which ESXi converts to UNMAP operations at the vSCSI layer
So, the discard option is by far the best option. sg_unmap requires quite a bit of manual work and a decent know-how of logical block address placement. Fstrim, still runs into some alignment issues–I am still working on this.
UPDATE: This is fixed in 6.5 Patch 1! The alignment issues have been patched and fstrim now works well. See this post: In-Guest UNMAP Fix in ESXi 6.5 Part I: Windows
Let’s walk through the discard version.
In the following scenario an EXT4 filesystem was created and mounted in an Ubuntu guest with the discard option.
pureuser@ubuntu:/mnt$ sudo mount /dev/sdd /mnt/unmaptest -o discard
This virtual disk was thinly provisioned. Four files were added to the filesystem of about 13.5 GB in aggregate size.

The thin virtual disk grew to 13.5 GB after the file placement.
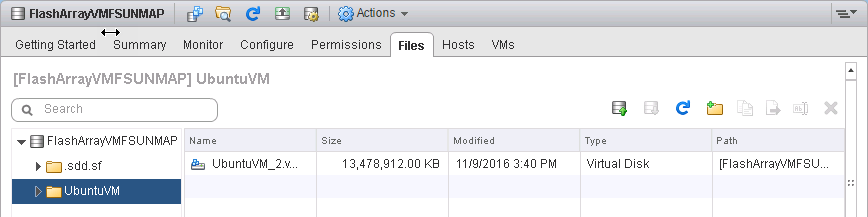
The files were deleted with the rm command

Due to the discard option being used, the space was reclaimed. The virtual disk shrunk by 13 GB:
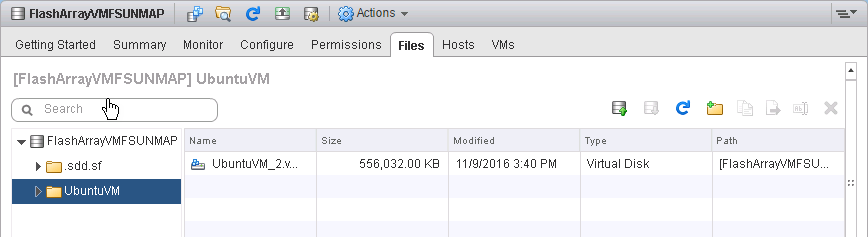
ESXi then issued its own UNMAP command because EnableBlockDelete was enabled on the host that was running the Ubuntu virtual machine. ESXTOP shows UNMAP being issued in the DELETE column:
![]()
The space is then reclaimed on the FlashArray volume hosting the VMFS datastore that contains the thin virtual disk:
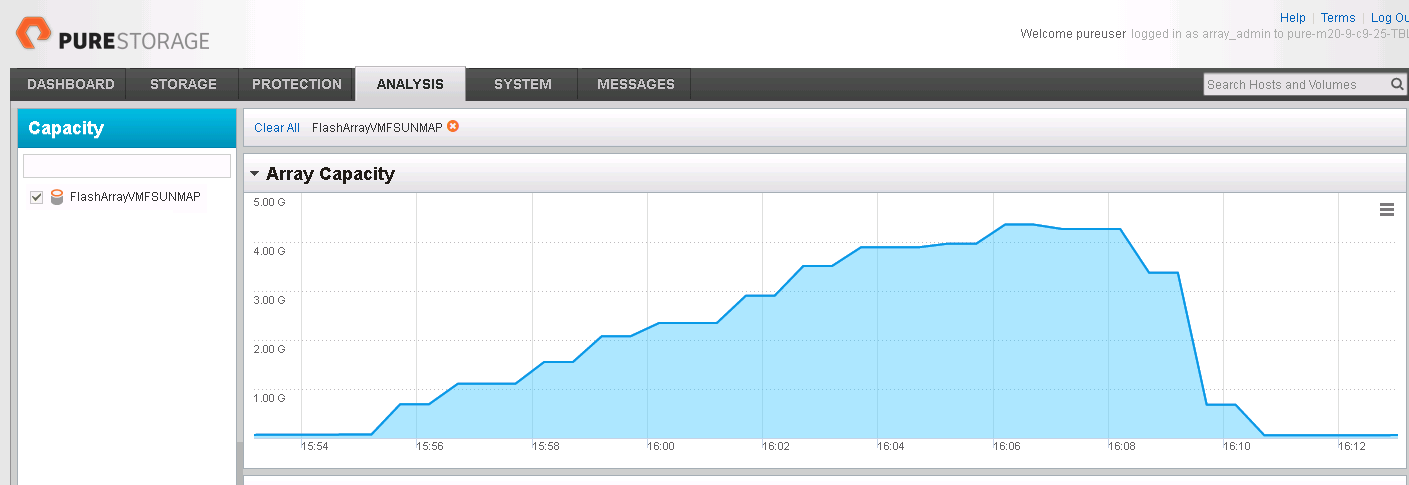
So one thing you might note is that it is not exactly 100% efficient. I’ve noticed that too. The thin virtual disk does not always quite shrink down to the exact size of the reduction. It gets close but not perfect. Stay tuned on this–I’ve made progress on some additional details surrounding this.
This is just the start, a lot more 6.5 blogging coming up!
Great article with examples and CLI! If this uses vSCSI, should this also work local disks (not in VSAN mode) ?
Can ESXi 6.5 translate in-guest OS trim to RPC truncate (for NFS storage arrays) ?
I noticed RPC truncate on Cormac Hogan’s blog at the time of vSphere 5.1 Flex-SE disk type: http://cormachogan.com/2012/09/05/vsphere-5-1-storage-enhancements-part-2-se-sparse-disks/
Thanks!! It should work with local disks as long as those have the proper trim/unmap support on them. Though, I cannot guarantee that as I do not have any local disk with the proper support to test it. But in theory the vSCSI layer doesnt treat them differently than SAN attached storage conceptually. I am not sure about the RPC truncate either (I don’t have any NFS)–though let me ask around!
Hi. Is vCenter must have?
Do we need vmware tools to be installed in guest OS?
Thanks
Hi! vCenter is not required and VMware tools does not need to be installed. This is entirely through SCSI
Do I need to enable EnableBlockDelete on VMFS6 with next command ?
esxcli settings advanced set –int-value 1 –option /VMFS3/EnableBlockDelete
I previously said this is only for VMFS 5, this still is required for end-to-end UNMAP with VMFS 6 too
Cody thanks for your reply!
Since I’m not native speaker, I want to ensure I have understood you correctly so I will re-phrase my question: do I need to enable UNMAP somehow for VMFS6 in vSphere 6.0/6.5 ?
Thanks!
Dear Cody,
do we need to use thin vdisks on thin LUNs in order to be able to utilize UNMAP?
To use in-guest UNMAP the virtual disk needs to be thin. The underlying physical LUN does not have to be thin, but most are these days. To use VMFS UNMAP–the physical LUN does have to be thin (for the most part, though there are some exceptions out there)
No need for this command in 6.0/6.5?
esxcli storage vmfs unmap -l myDatastore
This is still required in VMFS 5 (vSphere 6.0 or 6.5). If you are using VMFS-6 in vSphere 6.5 you do not need to use that command for that volume because ESXi will automatically unmap in the background. Though it can take some time (up to a day). If you want to reclaim space immediately though you can still run the command
You are very welcome! VMFS 6 is only in vSphere 6.5 so it is not in 6.0. If you format a volume in vSphere 6.5 as VMFS-6 UNMAP is enabled by default–you do not need to do anything to enable it.
I am a little confused with the automatic UNMAP and 6.5. I read your post about direct goes OS UNMAP and 6.0. Reading the post comments you said the only way you could get it to work automatically was to format NTFS using 64k clusters.
Does 6.5 overcome the NTFS 64k requirements for it to happen automatically with server 2012 R2+?
Since it is now an asynchronous process in 6.5. Regarding 6.0: when you format an NTFS volume with 64k clusters on server 2012 R2 and you delete items from the file system, when does the UNMAP against the storage array occur?
Thanks
Sorry, there are so many things at once it is easy to get wires crossed. Let me explain:
In vSphere 6.5, automatic UNMAP now exists for VMFS. This means when you delete or move a virtual disk (or entire VM) ESXi will issue UNMAP to the datastore in the course of a day or so. Reclaiming the space. Nothing is needed to get this done other than ESXi 6.5 and VMFS-6 and having the unmap setting set to “low”
The other part of this is in-guest UNMAP. This is when a file is deleted inside of a guest (inside of a virtual machine) from its filesystem, like NTFS or ext4 etc. When a file inside a guest is moved or deleted, if properly configured, the guest OS (Windows or Linux or whatever) can issue UNMAP to its filesystem. VMware will then shrink the virtual disk. If EnableBlockDelete is turned on, VMware will then translate the UNMAP to reclaim the space on the array itself. To enable this behavior automatically inside of a Windows VM, the NTFS must use the 64K allocation unit. If so, Windows can then issue UNMAP to a virtual disk and VMware will finish it at the array. Linux requires the discard option to be used to enable this behavior for its filesystems. This is different then VMFS unmap before as it starts at a higher level and it not deleting or moving a virtual disk–instead just shrinking it. Does that make sense?
Hi Cody,
I’m trying to get in-guest UNMAP working on a CentOS 7 VM. This is on a fully patched vSphere 6.5 system with ESXi 6.5 hosts. The file system is VMFS 6. All the per-requisites are good (checked with sg_vpd and sg_inq). I changed my entry in /etc/fstab from:
/dev/mapper/VolGroup00-root / xfs defaults 1 1
to:
/dev/mapper/VolGroup00-root / xfs defaults,discard 1 1
and rebooted the system. When I look at the mounts I don’t see the discard option:
[root@pattest ~]# mount | grep VolGroup00-root
/dev/mapper/VolGroup00-root on / type xfs (rw,relatime,seclabel,attr2,inode64,noquota)
Any thoughts? THANKS!
Pat,
Hmm I haven’t tried it with the automatic mount option like this, I have only manually mounted them with the discard option. Let me look into this and get back to you.
Thanks
Cody
Does this work with the new Virtual NVMe controllers on Enterprise Linux 6.5 (RHEL/Centos)? Fstrim seems to give FITRIM ioctl failed, seems to work OK with the regular controller though.
No UNMAP will not work with the vNVMe controller. You’ll need to stick with PVSCSI or LSI for that.
Ah OK, seems kind of strange that it wouldn’t work but its’ all good I suppose. Thanks
Sure thing! It actually makes sense when you think about it. NVMe replaces SCSI, and UNMAP and TRIM are SCSI commands, so for them to be translated the driver and stack needs to support what is called Dataset Management Commands in NVMe, which it doesn’t yet. I imagine that support is coming. VMware is just getting started with their NVMe support.
Thank you for explanation. It is very useful.
My question is: Should the command “vsish” work for any volumes?
Our datastore has two different disk groups with several volumes. Visish command for volumes on one diskgroup works well, but for volume on second disk group write: “VSISHCmdGetInt():Get failed: Failure”. Is it mean, that unmap doesn’t work on this volumes?
Thanks
You’re welcome! I have seen this fail and I am not sure why. I think there is something wrong with vsish. A reboot often has taken care of it, but I am not really sure why. You might want to open a case with VMware
I’m seeing different behaviour with regards to CBT. When I look at the drives on a CBT enabled guest the drives appear as standard “Hard disk drive”. I’ve updated the VM hardware and VMware tools, is there something else specific that I am missing?
I’m thinking perhaps trying to turn CBT off and on again, as it was enabled before the upgrade to 6.5 (Possibly as far back as 5.0/5.5)
Thanks
Interesting. Yeah try that and let me know. I will look into this as soon as I get a chance as well.
What linux distro are you using for the above testing?
I used Ubuntu, I dont remember offhand what version though
Cool. My esx hosts running 6.5 and vCenter is 6.5. I’ve installed latest distros of ubuntu and centos and can only ever seem to acheive [SCSI-2]. I’m beginning to think it is not important, but the perfectionist in me wants to see SCSI 6 with SPC4.
Are you using the latest version of vm hardware?
vmware hardware version 11. Essentially the latest of everything that is production ready.
The latest is 13 I think, I’m not at my desk but I thought that’s what you need to be on, I’ll check when I get a chance
correct. WIll try and get back to you. thanks.
hw version 13 did the trick. Thanks.
I have vsphere 6.5 running and it appears that the automated unmap was working. I migrated a VM from a datastore and the datastore is physically emtpy aside from vsphere folders/remnants. Vsphere claims 1.46gb of 3TB is used on the lun, which seems legit. The SAN thinks 263gb of 3TB is still allocated. This is down from 1TB to 263gb a few days ago (after I moved the VM).
The problem is, for the past 3 days, its stayed at 263gb on the SAN. I’ve tried running the command esxcli manually and it runs. The hostd logs say “unmapped 200 blocks from volume” regardless of what I list as the –reclaim-unit=
How can I get the SAN to match vsphere’s numbers?
A couple things:
1)If the datastore is physically empty (no running VMs) automatic UNMAP will not engage, so nothing will be reclaimed.
2)The block count is not configurable for VMFS-6 volumes, I believe this is a bug, but it will always use 200 no matter what you enter when doing manual UNMAP on VMFS-6
3)I believe there is also a bug where manual UNMAP will not reclaim blocks if they used to be allocated by thick type virtual disks. Only automatic UNMAP will get rid of that space. If there are no running VMs, that capacity is stranded. I think this is fixed in vSphere 6.7. I cannot confirm that though.
4)What array do you have? What vendor/model?
5)Regardless, you have two options. If the datastore is empty, you could just delete it and remove it on the array. Option two, depends on your array. If it has zero removal (like the FlashArray) you could just create a very large eagerzeroedthick virtual disk on the datastore. That will zero out the dead space and the array can remove it. But the ability for the array to do that depends on your array.
Hope that helps
Cody
@Cody, Thanks for the feedback.
1) I’m not certain this is necessarily the case. I vmotioned a VM from one datastore on an array to a completely different datastore on a different array. Once it was finished moving off, I was on the array’s management GUI and the next day or so, I could hit refresh and see blocks clearing out. I figured this was UNMAP working. Again, the array was empty at this point according to vsphere, but went from about 1T to 263gb.
2) That stinks
3)This VM definitely had large/beefy disks that were thick provisioned. One disk was 2T. It might be a big, but there were definitely blocks UNMAP’d despite this idea.
4)Kaminario.k2 K2-6800 it is all flash
5) Deleting this one would be fine, but I was more interested in how this all works for future causes. What if this happens again and I don’t have the ability to migrate the VMs off?
The zero out, I’ll have to look into. I’m not sure I fully follow though, create the eagerzerodisk and then what do I do, to confirm it released the blocks.
Thanks again
Sure thing! Essentially each host has an UNMAP crawler and it monitors only datastores that are “Active” for it, meaning they have a powered on VM. And every so often they kick into gear and run unmap. My guess is the host running that last VM was working on it and was able to reclaim some of the space even after it no longer had any VMs because it was still working. Though it is hard to say without looking at the UNMAP counters.
Yeah the thick virtual disk issue and UNMAP hasn’t been an issue I have seen, but a friend at EMC told me about it and that VMware had confirmed some issue. I dont know the specifics. Maybe it just doesnt work 100% of the time with thick.
So I believe Kaminario should be able to perform zero removal, so if you create a huge EZT disk and then delete it, the array should clean up the space. In theory. I dont know Kaminario at all, so I would ask them about how they handle contiguous zeroes.
In the end, most of the UNMAP issues I have seen with VMFS-6 seem to be when the datastore no longer has any VMs and automatic UNMAP stops doing its thing. Seems like people run into problems getting it fully cleaned up once that happens. One customer I had just deployed one small VM and let the host running it finish cleaning it up. When there is at least one VM it seems to work great, when there are none, the process breaks down. This is why I love VVols, no need for this any more
Hi Cody,
I noticed that I’m not getting any space reclamation and did some investigation. I’m focusing on some CentOS 7 VMs right now and verified that they support UNMAP:
[root@ssds-test ~]# sg_vpd /dev/sda -p lbpv |grep “Unmap”
Unmap command supported (LBPU): 1
When I run “fstrim /”, I get:
fstrim: /: FITRIM ioctl failed: Input/output error
I went back to one of your posts from April 24 when you mentioned, “No UNMAP will not work with the vNVMe controller. You’ll need to stick with PVSCSI or LSI for that.” I verified that the SCSI controller is the VMware Paravirtual controller.
The ESXi hosts are fully patched 6.5 (Build 8294253) and I’m connected via 10GB to a Pure //m20r2 running 4.10.5. Thanks for any helpful pointers.
BTW, I forgot to mention that all file systems are VMFS 6.
Pat
Hey! Hmm okay. My first question would be are you on the latest version of vm hardware?
Yup, they’re all HW level 13. Sorry I forgot to mention that.
Found the problem. I had patched the ESXi servers which required me to upgrade the VMware Tools. I had done that with the Powershell command with the noreboot option. Well, that was the problem. I needed to reboot the VM and now the fstrim works OK. Sorry for wasting your time.
Pat
No worries! Glad to hear!
Hi Cody,
We manage our over subscription of Storage at the Array level, and use EZT vDisks so that a datastore cannot be oversubscribed (We also do not permit VM snapshots but thats irrelevant to this conversation).
We are vey excited to use in-guest UNMAP, but it states it requires us to use thin vDIsks. Is there a VM Deployment method in which the vDisks are thin, thus getting us support for in-GUEST UNMAP, but fully blocks off the provisioned space at the datastore level so that our Admins can not over subscribe the datastore? Or even if it shows free is there posssibly a setting we can enable to prevent over subscription of the datastore?
Thank You,
Jess Simpson
Sr. Systems Engineer, Storage
Jess,
I wish… Unfortunately thin will always be thin (especially with in-guest UNMAP). You could fully write it out, but as soon as you delete something in guest, the allocation would be reclaimed. This is something that would be possible with VVols, because we (Pure) control the datastore allocation reporting.
From a VMFS perspective, I am not really aware of a way to do this from within vCenter itself. You could however control this from something like vRealize–but it would require that provisioning go through a portal like vRA or vRO
Hi cody ,
How is unmapping affecting pure storage ?
Is there a way to disable it on the pure storage side ? or only possible on vmware side ?
I see unmapping happens every Sunday on my pure storage and I am trying to stop it on the vmware side but without any success .
I have vmfs6 datastores.
How the pure storage arrays deals with extensive unmapping activity ?
Is there a particular reason you don’t want it? VMFS issues auto unmap by default to make sure dead capacity doesn’t persist. Disabling it will cause wasted space to build up in your array. Though this post shows how to disable it (change low to none). But I strongly discourage doing so. The unmap process is fairly unobtrusive and helpful.