
In Purity 5.1 there were a variety of new features introduced on the FlashArray like CloudSnap to NFS or volume throughput limits, but there were also a variety of internal enhancements. I’d like to start this series with one of them.
VAAI (VMware API for Array Integration) includes a variety of offloads that allow the underlying array to do certain storage-related tasks better (either faster, more efficiently, etc.) than ESXi can do them. One of these offloads is called Block Zero, which leverages the SCSI command called WRITE SAME. WRITE SAME is basically a SCSI operation that tells the storage to write a certain pattern, in this case zeros. So instead of ESXi issuing possibly terabytes of zeros, ESXi just issues a few hundred or thousand small WRITE SAME I/Os and the array takes care of the zeroing. This greatly speeds up the process and also significantly reduces the impact on the SAN.
WRITE SAME is used in quite a few places, but the most commonly encountered scenarios are:
- Creating an eagerzeroedthick virtual disk
- Zeroing-on demand in zeroedthick disks or thin disks
In Purity 5.1 (and actually also 5.0.7 and planned for 4.10.x too, but not yet) we improved our support for WRITE SAME.
For the most part the speed of our WRITE SAME handling was rather good–we don’t even write any zeroes, we just mark some metadata and return zeroes if read from. So it is almost a non-op for the FlashArray.
That being said there was some room for improvement. We had some support cases around VVols where migrations were kicked off and they took a bit longer than expected. Turns out this had to do with our handling of large WRITE SAMES (ESXi WS I/Os are generally 1 MB). Our sub-system was not tuned well for WRITE SAME of that size–which is somewhat silly since WRITE SAME is almost invariably that size. So we improved our handling of it.
Let’s run through some before and after tests.
Create EagerZeroedThick Disks
Let’s do the most common proof point of WRITE SAME–creating eagerzeroedthick virtual disks. When you create EZT disk, ESXi will first zero the whole thing out before it can be used. If the underlying storage supports WRITE SAME it will issue that.
I have two arrays:
A m50 running Purity 5.0.0 (fibre channel)
A m20 running Purity 5.1.0 (fibre channel)
So let’s run a quick test with WRITE SAME disabled just to get a baseline.
First, turn off WRITE SAME on ESXi:
Then I will use PowerCLI to create a new 1 TB eagerzeroedthick virtual disk. Using the measure-command cmdlet, it shows that it takes 17 minutes and 6 seconds to complete. Quite some time.
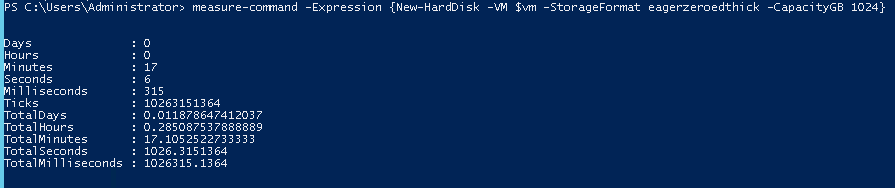
I also recorded esxtop and it shows 1 GB/s of writes going on the entire time.
Time to re-enable WRITE SAME. I will first run it on the array running old code (my m50).

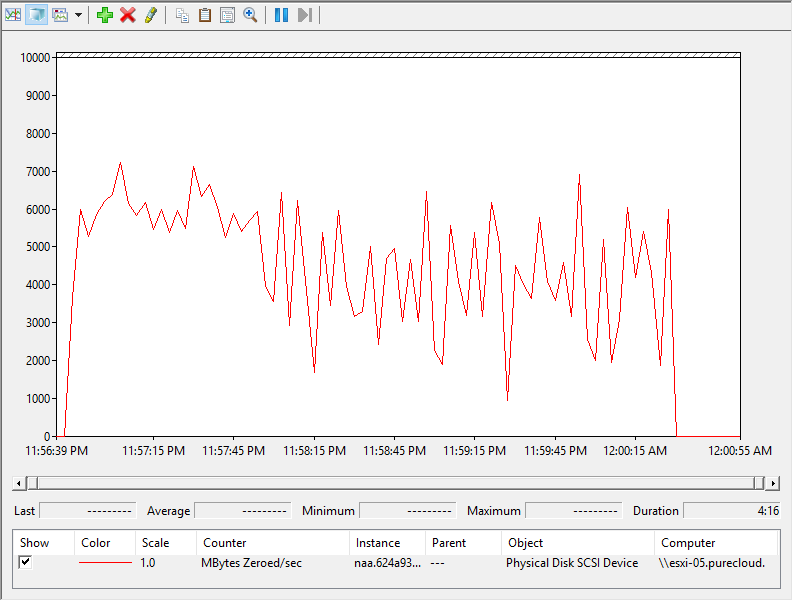
Took 3 minutes 47 seconds. Better certainly. Looking at esxtop, we can see the write throughput has dropped to almost nothing–a few MB/s, instead of 1 GB/s:
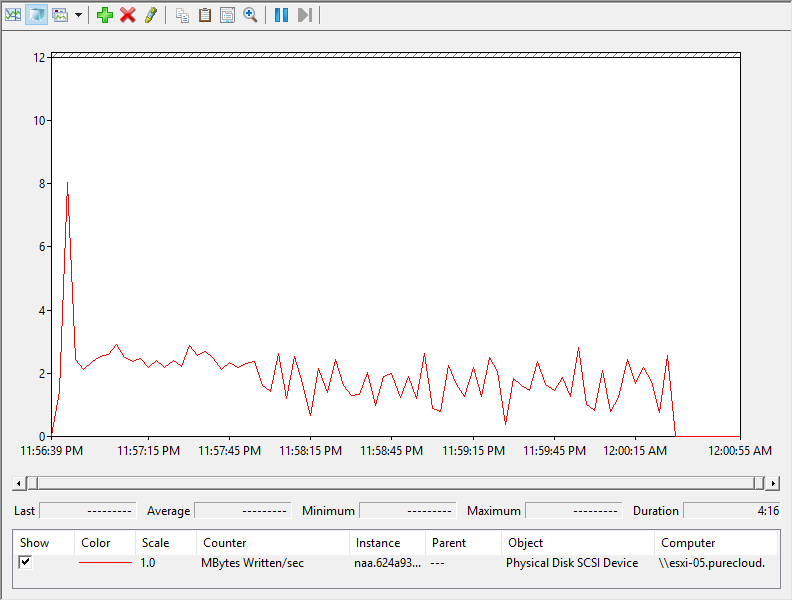
The WRITE SAME throughput is averages around 5 GB/s. Note that WRITE SAME throughput is not the same as regular I/O throughput–it is rather effective throughput, not the actual size of the I/Os. A 1 MB WRITE SAME I/O is not 1 MB in size, it just describes 1 MB of blocks–in reality it is quite small of an I/O.
Let’s re-run our test on my m20 running Purity 5.1:

1 minute and 10 seconds–3x faster than before.
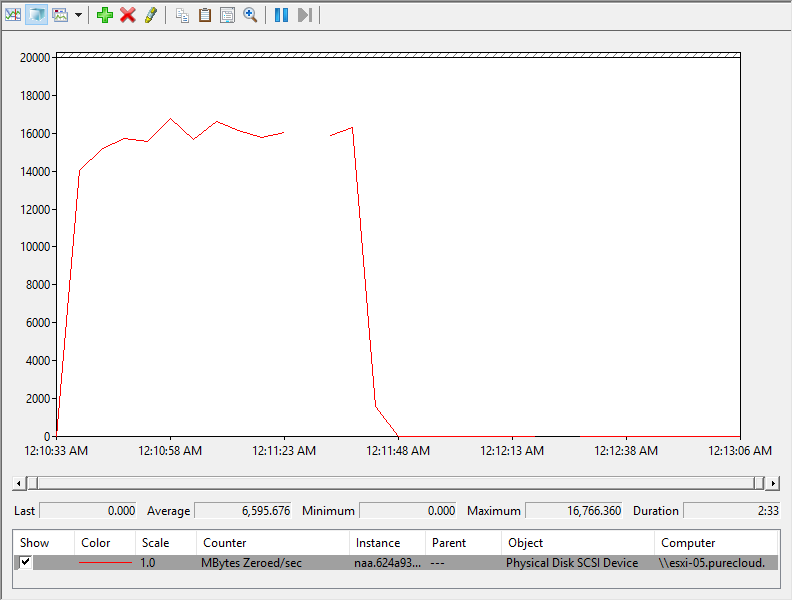
The WRITE SAME throughput jumped through the roof to average around 15 GB/s.
Much faster!
Zero-on-first-write
The other major area WRITE SAME is used is during lazy zeroing. In VMFS, ESXi will always zero out a virtual disk before a guest can write to it. When this zeroing happens is what changes. For eagerzeroedthick virtual disks it happens when it is created as shown above. For zeroedthick or thin it happens when the guest issues a write that goes to a new block. When a new block is needed, VMware will first zero it out and the guest can commit its writes. When that block is filled, the next one will be zeroed and then the data committed and so on.
This is why there is a slight latency penalty for new writes in zeroedthick and thin virtual disks on VMFS (as seen in this post).
With an improvement in WRITE SAME handling, let’s see if there is a performance improvement in new writes inside of a virtual disk.
I kicked off a vdbench workload with 100% sequential write 32 KB I/O size with 32 outstanding I/Os against a thin virtual disk and I ran it until the 20 GB virtual disk became fully allocated.
Against the array with the older code (my m50) the latency report that I recorded from inside of the guest is below: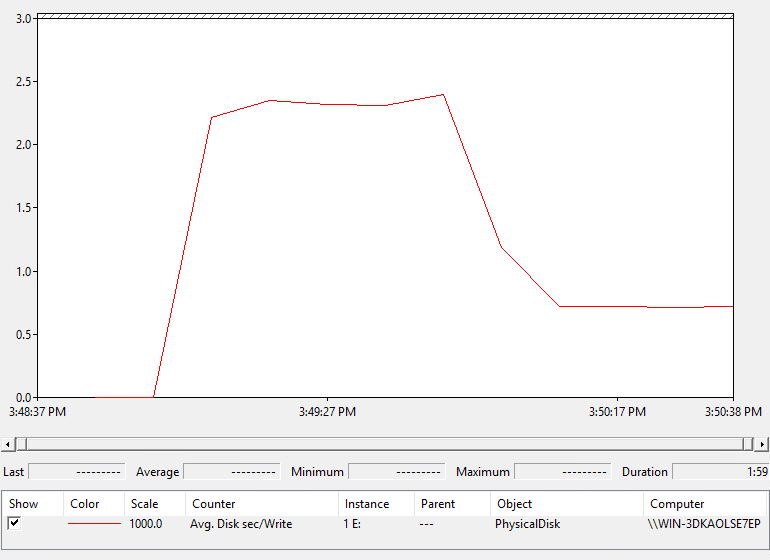
A few things to note:
- The latency for the first 40 seconds was around 2.25 ms. Most of this latency was due to guest I/Os waiting for WRITE SAME to be issued first.
- Once the 20 GB was fully allocated, no more WRITE SAME had to be issued, so there is no allocation penalty and the average latency dropped to .7 ms.
Now running the same test but on a thin virtual disk on the m20 with the new code:
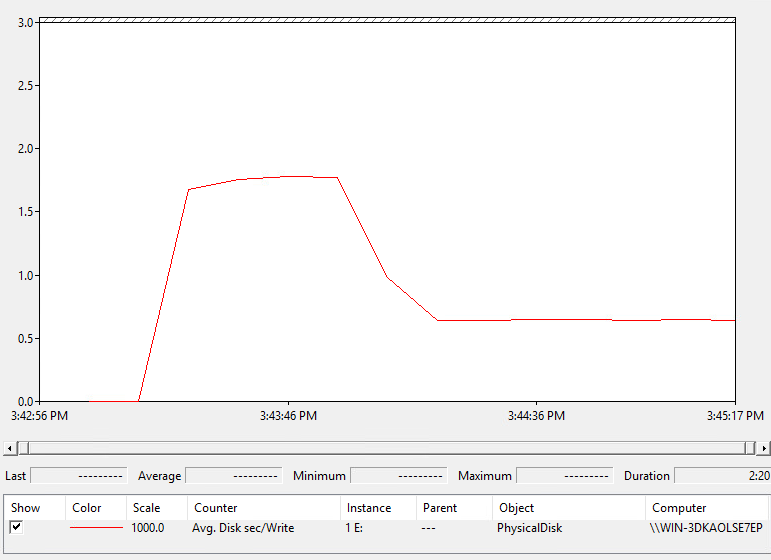
- The allocation penalty period is shorter–30 seconds instead of 40.
- The latency during the allocation period is lower, 1.6 ms instead of 2.25.
So in short, a nice internal enhancement.
Of course none of this matters too much with VVols 🙂 Thin VVols do not have an allocation penalty and there is no such thing on the FlashArray as a thick VVol, but since VMFS is still the majority at this point this is likely relevant for many.
Stay tuned for more posts from 5.1.
The size of system state partition has drastically increased since we have upgraded to 5.0.7. Is this a expected behavior?
No–please open a support case with Pure. Thank you!
Hi Cody,
big fan, met you on Accelerate 2019 and i love your stuff.
I have one big customer here in Germany, we have discussions about Block size (4k, which is place for 2000 VMs and 64k which is recommended from Pure for space reclamation) and also about the good old Thin vs Thick question.
In your post from 2014 (https://www.codyhosterman.com/2014/07/pure-storage-flasharray-and-re-examining-vmware-virtual-disk-types/) your conclussion is to use eagerzoeredthick as default and for performance heavy applications.
Did that change with the introduction of “write same”?
In the following document Pure basically says: Use thin as default.
(https://support.purestorage.com/Solutions/VMware_Platform_Guide/VMware_Best_Practices/FlashArray_VMware_Best_Practices/fffVirtual_Machine_and_Guest_Configuration#Space_Reclamation_In-Guest)
What is your opinion on that today?
Thanks!!! Glad you have found it useful. My opinion on that remains the same, as I wrote that when WRITE SAME was around–WS was introduced a few years prior. While the performance difference is smaller and smaller through a variety of enhancements, ESXi still has to do more work for a thin disk for new writes than EZT disks. So EZT will basically always perform a bit better on writes to unallocated space. But the difference is so smaller that really only the most sensitive applications will notice.