This is a simple but important one. iSCSI path limits. Since the dawn of human, ESXi has had a disparity in path limits between iSCSI and Fibre Channel. 32 paths for FC and 8 (8!) paths for iSCSI.
The vSphere “update” releases are much more significant than they used to be–traditionally most of the new features came in the major releases. 6.5, 6.7, etc. vSphere 7.0U2 just released and there are quite a bit of storage-related features.
In a few weeks, I will hit 7 years at Pure Storage. It has been REALLY fun. Helping to build our VMware integration ecosystem, pushing the vVol adoption/use case/efforts forward. Building what I believe to be a world-class solutions team that I manage.
I’ve hit my seven year itch. What is next? What should I tackle? Where can I make a big(ger) impact? What is something that is uncomfortable for me, that will allow me to grow?
Clearly, public cloud is a thing. Like, duh. Our customers see that, the industry sees that, and of course Pure Storage sees that. I think the potential there is really just starting–and I think tapping that potential is really going to accelerate efforts on-premises too. I think some of the work we are doing with Equinix Metal is proof of that.
I’ve focused on VMware, specifically VMware storage for my entire career. My first job out of university was just that. The VMware ecosystem though is not going away, and in fact is doing some really cool stuff too. Tanzu. VCF. VMware Cloud. vVols. NVMe-oF. A lot of exciting and differentiating work in that realm. One could easily remain there and perform super satisfying and impactful work. So continuing my focus there is definitely a great option.
Hello- my name is Nelson Elam and I’m a Solutions Engineer at Pure Storage. I am guest writing this blog for use on Cody’s website. I hope you find it helpful!
With the introduction of Purity 6.1, Pure now supports NVMe-oF via Fibre Channel, otherwise known as NVMe/FC. For VMware configurations with multipathing, there are some important considerations. Please note that these multipathing recommendations apply to both NVMe-RoCE and NVMe/FC.
I get this question quite a bit–in fact I got this question just today while discussing ways to grow the Pure Storage/VMware business. To folks who are close to the VMware storage ecosystem it might seem like an odd question, but it’s a good question!
VMware puts a lot of energy and time into vSAN. Lots of technical information, lots of marketing, lots of webinars, lots of great people discussing its ins and outs at VMware. So if vSAN is such a big storage thing at VMware, how does Pure support vSAN? What do we do with it? How can use deploy vSAN to use Pure Storage FlashArray storage?
Well let’s first take a look at what VMware really is offering with storage. VMware, at the highest level of storage is offering Storage Policy Based Management (SPBM). In a strong and steady movement away from caring about specific datastores, it is much more about the features and protections you want to apply to your VMs, or more specifically their disks. I want it replicated, I want it encrypted, I want it fast. Etc.
Note: This is another guest blog by Kyle Grossmiller. Kyle is a Sr. Solutions Architect at Pure and works with Cody on all things VMware.
VMware Tanzu is a great way for VMware users to manage their virtual machine environments while in parallel coming up to speed with containers all under the same familiar pane of glass. In fact, that’s possibly the biggest value proposition that Tanzu gives us today: extending vSphere and all of its enterprise features and goodness to the realm of K8s in a recognizable context.
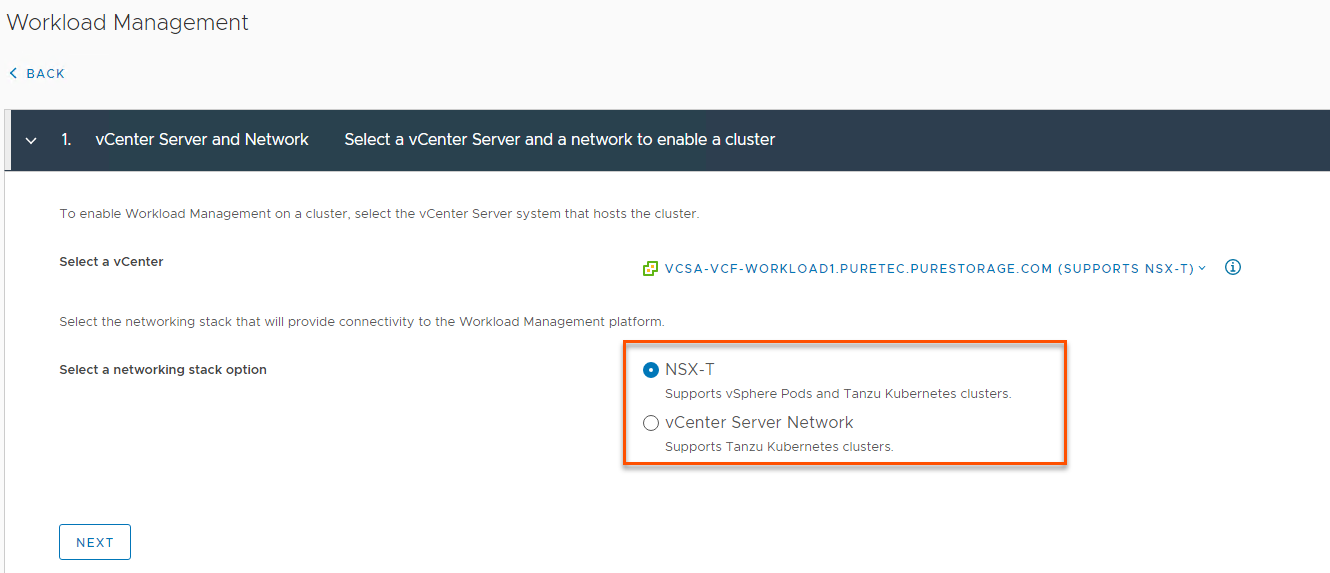
There’s a catch, though. Before one can start to use Tanzu one has to get Tanzu setup. While it’s reasonably straight forward to do so – it is also important to note that there are multiple ways to enable Tanzu and to distinguish the pros/cons of each of them. It’s also key to understand what these underlying components are and how they interact to help troubleshoot any potential problems. This post will focus on two of these methods: vCenter Network Option (HA-Proxy) and NSX-T (VMware Cloud Foundation). Cody covered the 3rd option of directly deploying Tanzu Kubernetes Grid to vSphere in an earlier post that can be found here.
It’s critical to note that you must be at a minimum of vSphere 7 before you can use either of these below methods we will cover. ESXi 6.7U3 and up is supported via the method shown in Cody’s post I linked above. The two Workload Management enablement networking options are built right into the vSphere 7 UI under Workload Management when you add a cluster:
The other important prerequisite is that you will need one or more SPBM (Storage Policy Based Management) policies defined in order to get the Supervisor Cluster up and running. There are a couple of KB articles on our Platform Guide which shows how to do this on the FlashArray and the differences between VMFS and vVols based policies.
So let’s lay out the key components and differences between the vCenter Server Network and NSX-T backed Workload Management options and provide some more information on how to enable each of them…
The vCenter Server Network option allows customers to get Workload Management working in their vSphere environment by deploying a single OVA (known as HA-Proxy) and does not require any other external products like NSX-T or SDDC Manager. This OVA and associated information can be found at this link on GitHub. The main benefit of this option is the relative simplicity of getting Tanzu running since the only items you need to setup are a distributed switch portgroup to handle your Kubernetes ingress/egress ranges and the HA-Proxy OVA itself. The HA-Proxy will act as the load balancer for kubernetes traffic and provide the supervisor cluster API endpoint. The downside is that the HA-Proxy VM represents a single point of failure and larger kubernetes deployments at some point will more than likely overwhelm the CPU/memory resources available to it. This option is best for those who want to look at Tanzu in a POC/exploratory type of setup.
Here’s a quick narrated technical video I created showing how to setup Workload Management with the HA-Proxy OVA:
After Workload Management was enabled, I created another quick demo video showing how to create Namespaces and deploy a Tanzu Kubernetes Guest Cluster:
NSX-T based Workload Management is recommended to be backed/managed by a VMware Cloud Foundation deployment. This option gives you all of the enterprise grade features, resilience and lifecycle management that comes embedded with SDDC Manager. The con of this option is there is more setup work and moving pieces involved than the other Tanzu deployment choices and it requires additional licensing once the trial period expires. The key component that needs to be setup for Tanzu in particular is called an NSX-T Edge Cluster. An Edge Cluster is comprised of at least one (but really it should be two for resiliency) Edge VMs which help route and load balance network traffic from your top of rack switch to the underlying kubernetes deployments. The Edge Cluster deployment can be automated to a large extent from within SDDC Manager via a wizard.
In our lab, I went the route of manually deploying a 2 node Edge Cluster within NSX-T as this gives a better ‘under the hood’ view of how everything works together. As most customers likely do not have top of rack switch access to setup BGP, I also decided to use the static routing option within NSX-T. Here’s a video showing how to set this up end-to-end:
With the EdgeCluster built, the next step is to enable Workload Management which is shown in this video:
Hopefully this post has provided a bit of guidance and insight in terms of what Tanzu solution might be right for your environment. We are continuing to investigate and document how to best leverage the FlashArray with kubernetes so please check back here and our platform guide often for updates. Thanks for reading.
One of the initial limitations around NVMe-oF was the (in)ability to boot from SAN–though this is no longer the case. And you need some fairly new drivers across the board to do it. As far as I am aware, (as of the publication of this post) boot from SAN via NVMe is only currently supported via Fibre Channel, not RoCEv2. But I will keep an eye on that. You do need NVMe-oF/FC capable HBAs–a list of them can be found here:
I am using Emulex LightPulse LPe32002-M2 2-Port 32Gb Fibre Channel Adapter in my server, so I will go through the Emulex instructions. The ESXi-side of things will be similar for other vendors, but the HBA driver version/configuration will be different.
First off, want to learn more about NVMe? Check out this from SNIA:
NVMe. A continued march to rid ourselves of the vestigial SCSI standard. As I have said in the past, SCSI was designed for spinning disk–where performance and density are not friendly to one another. NVMe, however, was built for flash. The FlashArray was built for, well, flash. Shocking, I know.
Putting SCSI in front of flash, at any layer, constricts what performance density can be offered. It isn’t just about latency–but throughput/IOPS per GB. A spinning disk can get larger, but it really doesn’t get faster. Flash performance scales much better with capacity however. So larger flash drives don’t get slower per GB. But this really requires the HW and the SW to take advantage of it. SCSI has bottlenecks–queue limits that are low. NVMe has fantastically larger queues. It opens up the full performance, and specifically performance density of your flash, and in turn, your array. We added NVMe to our NVRAM, then our internal flash to the chassis, then NVMe-oF to our expansion shelves, then NVMe-oF to our front end from the host. The next step is to work with our partners to enable NVMe in their stack. We worked with VMware to release it in ESXi 7.0. More info on all of this in the following posts:
I am working on some new integration efforts around a feature we call “offload” and figured since I am setting it up, I might as well document it.
For the un-initiated we have a feature called Snapshot Offload that creates snapshots of one or more sets of volumes in a write-consistent manner and sends them to a non-FlashArray target (similar to our snapshot replication from one FlashArray to another conceptually). Those snapshots can then be ingested back to that FlashArray, a different one, or a Cloud Block Store instance in AWS or Azure.
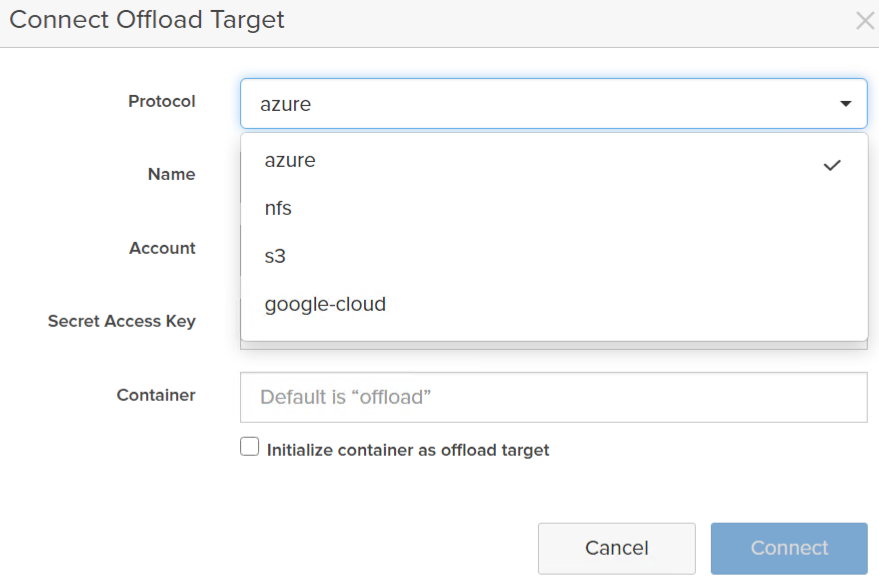
Snapshot offload allows you to send to either some object store, so AWS S3, Azure Blob, GCP Object, or a random NFS target:
For this post I am going to walk through creating an AWS S3 bucket, providing credentials, and then configuring a protection group.
In the world of SCSI, a storage device is generally addressed by two things:
LUN–Logical Unit Number. This is a number used to address the device down a specific path to a specific array, for a specific host. So it is not a unique number really, it is not guaranteed to be unique to an array, to a host, or a volume. So for every path to a volume there could be a different LUN number. Think of it like a street address. 100 Maple St. There are many “100 Maple Streets”. So it requires the city, the state/province/etc, the country to really be meaningful. And a street name can change. So can other things. So it can usually get you want you want, but it isn’t guaranteed.
Serial number. This is a globally unique identifier of the volume. This means it is entirely unique for that volume and it cannot be change. It is the same for everyone and everything who uses that volume. To continue our metaphor, look at it like the GPS coordinates of the house instead of the address. It will get you where you need, always.
So how does this change with NVMe? Well these things still exist, but how they interact is…different.
Now, first, let me remind that generally these concepts are vendor neutral, but how things are generated, reported, and even sometimes named vary. So I write this for Pure Storage, so keep that in mind.