
Another UNMAP post, are you shocked? A common question that came up was what volumes have dead space? What datastores should I run UNMAP on?
My usual response was, well it is hard to say. Dead space is introduced when you move a VM or you delete one. The array will not release the space until you either delete the physical volume, overwrite it, or issue UNMAP. Until vSphere 6.5, UNMAP for VMFS was not automatic. You had to run a CLI command to do it. So that leads back to the question, well I have 100 datastores, which ones should I run it on?
So to find out, you need to know two things:
- How much space the file system reports as currently being used.
- How much space the array is physically storing for the volume hosting that file system.
The delta between this is the amount of dead space that can be reclaimed. If the array number is much higher, that means there is a lot of dead space. Because that delta represents the space consumed by files that have been deleted or moved.
With a Data Reduction AFA like the FlashArray, this is not necessarily a simple thing. The FlashArray, for instance, reports how much space after data reduction is being stored. Data reduction including pattern removal (such as zero removal), compression and deduplication. So this reduces the footprint of what the FlashArray reports as actually used. So you can’t really just compare the two numbers.
Let’s take this example:
I have 80 GB used on my file system and the FlashArray reports 20 GB used for the underlying volume–the data reduction ratio is 4:1. If I delete 20 GB from my file system, that will reduce my file system usage down to 60 GB. So 20 GB of dead space now. My array still reports 20 GB though because it does not know the files were deleted.
But the 20 GB is still far less than file system-reported 60 GB. So you don’t really know that you have up to 20 GB of dead space (depending on how reducible the deleted space is dictates how much you will actually get back) it just looks like your data set is reducing 3:1 now instead of 4:1. So unless you deleted A LOT of data (or your data set is not reducible), it would be hard to know you have dead space on a volume because our number is almost always going to be lower than whatever the file system says.
So this begs the question–is there a way on the FlashArray to see what the host has written in total at a point in time for a given device, before data reduction? Well up until recently I didn’t think so. But after an unrelated conversation with engineering I found out there is indeed a way to figure this out!
So we have a metric called “thin_provisioning” and this is reported as a percentage in our CLI and REST and not reflected in our GUI.
I always thought this was a throw-away number, who cares about thin provisioning savings? All that matter is how well your actual data is reduced by data reduction techniques? Who cares how much physical capacity is saved by using array-based thin provisioning? That is sooo 2008…
But! Actually! This is an important metric when it comes to dead space identification. Let’s look at what this metric actually means. What this actually means is the percentage of the overall space that the host has never written to. So basically 1 minus the thin provisioning percentage will give you the percentage of the volume the host has actually written to. Multiply that by the provisioned capacity of the volume and you get how much space we think the host has written to us.
(1 – thin_provisioning ) * size = host written space
Pretty simple! So you take this number and subtract what the file system itself shows as written you get the dead space!
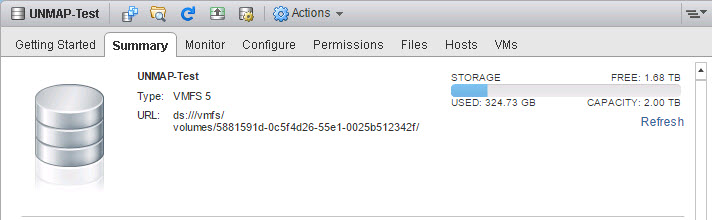
Let’s look at an example. I have a VMFS with 20 VMs on it and it is currently using 320 GB (1.68 TB is free) out of 2 TB:
Now to look at the FlashArray volume. You can do this a variety of ways, I used our REST API via vRealize Orchestrator and our vRO plugin. You can use anything that can make REST calls or of course our CLI.
This is the GET REST call with the URI of:
https://pure01.example.com/api/1.9/volume/UNMAP-Test?space=true
The CLI command would be:
purevol list UNMAP-Test –space
I prefer REST because it gives you a very accurate number. The CLI reports just two digits. But that is probably good enough regardless.’
My volume report a value of 0.8438614518381655 for thin_provisioning.

If I run that number through the math:
(1 – 0.8438614518381655 ) * 2048 GB = Virtual Space
I get the FlashArray reports 319.77 GB as used. Which is exactly (well other than some rounding error) what VMFS sees! So let’s create some dead space–I will delete half of my VMs.
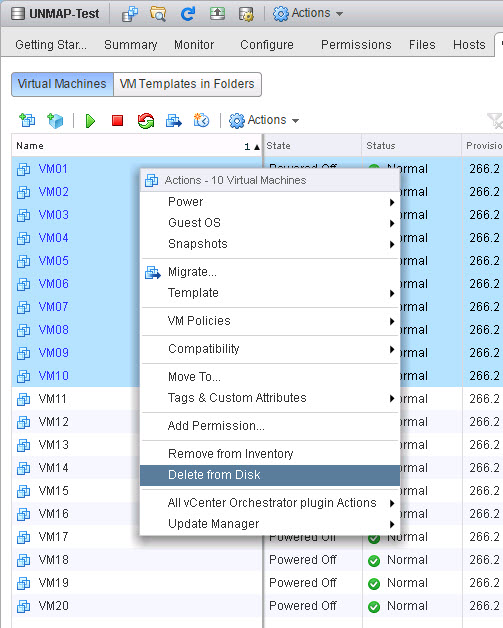
We can see that half have been deleted and I now have 160 GB used instead of 320 GB.
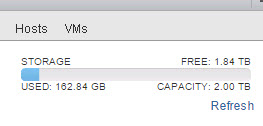
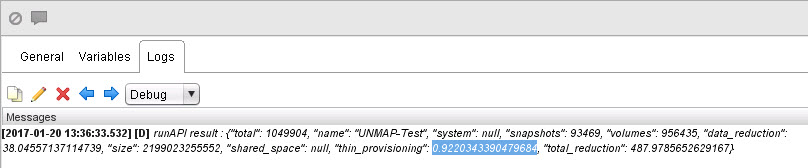
But if we look at the FlashArray, we see that the thin_provisioning value has not changed. This is because it does not know that these VMs have been deleted. So it still reports 320 GB as being used by the file system.
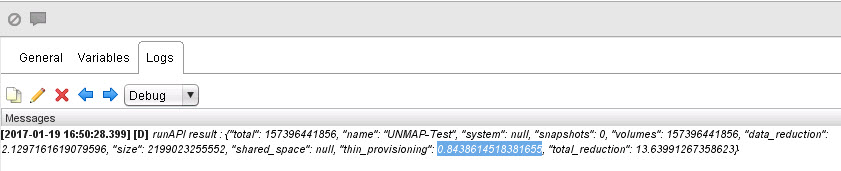
The difference between VMFS and the FlashArray is now 320 GB – 160 GB, so we have 160 GB of dead space! Time to run UNMAP!
A million ways to run UNMAP, but I will just use the old fashioned SSH and esxcli:
![]()
Now if we check the thin_provisioning value for that volume again it is now up to 92%, and if you do the math that is now at the 160 GB like VMFS reports! Dead space totally gone!
So a quick FAQ:
Q: If I run UNMAP on this volume, will I get physical space back on my array?
A: Maybe, maybe not. This is reporting dead virtual space, so if that space is heavily deduplicated it may not be returned immediately. Running UNMAP on the FlashArray is about cleaning up the meta data tables. Once the final meta data pointer has been cleared for a given block, the physical space of that block will be returned.
Q: Is this 100% accurate?
A: This is pretty accurate in my testing. The major caveat is that this is only very accurate when thin virtual disks are used. Since thick virtual disks increase the allocate, but not written space on the VMFS–the array does not consider a full thick virtual disk host written space. So with thick type virtual disks results may vary. With datastores with thin virtual disks only, this works very well.
Q: What about vSphere 6.5 and VMFS-6?
A: Since space reclamation is automatic with VMFS-6, this is really only targeted at VMFS-5. So upgrade to vSphere 6.5 and VMFS-6 and you don’t need to worry about this anymore.
Q:How to I automate this?
A: I wrote a PowerShell/PowerCLI script! Read on.
PowerCLI Script
So I wrote a PowerCLI script to automate the discovery of this. This script does the following:
- Fully interactive. There is no need to edit the script. Just run it, and it will ask you what it needs.
- It will ask you how many FlashArrays you want to look at. Essentially it looks at your datastores and then figures out what FlashArrays they are on. So we need to provide connectivity to the script for each FlashArray. Enter how many, and then an IP/FQDN for each.
- Enter in FlashArray credentials.
- Enter in vCenter IP/FQDN
- Either let it re-use your FlashArray creds for vCenter, if they have access of course to vCenter, or enter in new ones.
- Enter a dead space threshold. This script will look at all of the FlashArray datastores and then find how much space they currently have allocated from a VMFS perspective, and then look at what the FlashArray sees as virtually allocated. The difference is the dead space. It then returns the datastores. Now you may not care if a volume has 30 MB of dead space. So entering a number here will filter out any volume that has less than some amount in GB of dead space. I choose 25 in my video below.
- The script requires PowerCLI 6.3 or later. It will check for it and import it, if it is installed.
- The script also requires the FlashArray PowerShell SDK. It will check for it and import it, if it is installed.
- It also logs everything out to a log file. It will ask you for a directory. Some basic information is spit out to the screen.
Download it here:
https://github.com/codyhosterman/powercli/blob/master/IdentifyDeadSpace.ps1
See a demo here:
Hi, I am getting below error when running the identify dead space script.
I am using Powercli 6.3 Release 1 and latest Pure SDK
Pure Storage VMware ESXi Dead Space Detection Script v1.0
—————————————————————————————————-
How many FlashArrays do you want to search? (enter a number): 1
Please enter a FlashArray IP or FQDN: 172.24.255.103
Please enter a vCenter IP or FQDN: 172.24.255.176
Re-use the FlashArray credentials for vCenter? (y/n): n
What virtual dead space threshold in GB do you want to limit the results to? (enter a number): 1
Exception calling “ToInt32” with “2” argument(s): “Additional non-parsable characters are at the end of the string.”
At D:\purecli\Powercli\IdentifyDeadSpace.ps1:275 char:21
+ $deadspace = [convert]::ToInt32($deadspace, 10)
+ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+ CategoryInfo : NotSpecified: (:) [], MethodInvocationException
+ FullyQualifiedErrorId : FormatException
Exception calling “ToInt32” with “2” argument(s): “Additional non-parsable characters are at the end of the string.”
At D:\purecli\Powercli\IdentifyDeadSpace.ps1:275 char:21
+ $deadspace = [convert]::ToInt32($deadspace, 10)
+ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+ CategoryInfo : NotSpecified: (:) [], MethodInvocationException
+ FullyQualifiedErrorId : FormatException
Exception calling “ToInt32” with “2” argument(s): “Additional non-parsable characters are at the end of the string.”
At D:\purecli\Powercli\IdentifyDeadSpace.ps1:275 char:21
+ $deadspace = [convert]::ToInt32($deadspace, 10)
+ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+ CategoryInfo : NotSpecified: (:) [], MethodInvocationException
+ FullyQualifiedErrorId : FormatException
Exception calling “ToInt32” with “2” argument(s): “Additional non-parsable characters are at the end of the string.”
At D:\purecli\Powercli\IdentifyDeadSpace.ps1:275 char:21
+ $deadspace = [convert]::ToInt32($deadspace, 10)
+ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+ CategoryInfo : NotSpecified: (:) [], MethodInvocationException
+ FullyQualifiedErrorId : FormatException
Exception calling “ToInt32” with “2” argument(s): “Additional non-parsable characters are at the end of the string.”
At D:\purecli\Powercli\IdentifyDeadSpace.ps1:275 char:21
+ $deadspace = [convert]::ToInt32($deadspace, 10)
+ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+ CategoryInfo : NotSpecified: (:) [], MethodInvocationException
+ FullyQualifiedErrorId : FormatException
Analysis for all volumes is complete. Total possible virtual space that can be reclaimed is 21 GB:
The following datastores have more than 1 GB of virtual dead space and are recommended for UNMAP
DatastoreName DeadSpaceGB
————- ———–
Pure_UAT_Shared_Vol_1 -1,415
Pure_UAT_GHC_Vol_1 1,461
Pure_UAT_Shared_Vol_2 -1,275
Pure_UAT_Shared_Vol_3 134
Pure-UnityVSA 2,290
Pure_UAT_GHC_Vol_2 -1,174
Let me look into this and get back to you.
This has been fixed. Get version 1.1 from my Github page.
We are using VMWARE ESXi 5.5 and vCenter 5.5
I too see this error.
vSphere 6 & vCenter 6
Exception calling “ToInt32” with “2” argument(s): “Additional non-parsable characters are at the end of the string.”
At C:\UNMAP\IdentifyDeadSpace.ps1:275 char:21
+ $deadspace = [convert]::ToInt32($deadspace, 10)
+ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+ CategoryInfo : NotSpecified: (:) [], MethodInvocationException
+ FullyQualifiedErrorId : FormatException
Exception calling “ToInt32” with “2” argument(s): “Additional non-parsable characters are at the end of the string.”
At C:\UNMAP\IdentifyDeadSpace.ps1:275 char:21
+ $deadspace = [convert]::ToInt32($deadspace, 10)
+ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+ CategoryInfo : NotSpecified: (:) [], MethodInvocationException
+ FullyQualifiedErrorId : FormatException
Finally have some time to look at this. Stay tuned.
This has been fixed. Get version 1.1 from my Github page.
Cool…Now it is working..
Thanks
Madhusudan
Cody
What means if the script reports numbers starting with – (minus)?
DatastoreName DeadSpaceGB
————- ———–
FA1_VMFS_150 -5.450
FA1_VMFS_151 -5.982
FA1_VMFS_152 -6.170
FA1_VMFS_165 -6.425
FA1_VMFS_166 -4.261
FA1_VMFS_176 197
FA1_VMFS_181 -4.123
FA1_VMFS_183 -3.867
FA1_VMFS_184 -3.133
FA1_VMFS_188 -3.117
FA1_VMFS_189 -3.244
FA1_VMFS_196 -3.010
FA1_VMFS_198 -4.504
FA1_VMFS_201 -3.653
FA1_VMFS_203 -3.878
FA1_VMFS_208 -3.653
FA1_VMFS_210 -4.140
FA1_VMFS_213 -3.157
FA1_VMFS_226 -3.002
FA1_VMFS_234 -3.407
FA1_VMFS_236 -3.653
FA1_VMFS_237 -4.679
FA1_VMFS_238 -3.392
FA1_VMFS_239 -3.356
FA1_VMFS_251 -3.417
FA1_VMFS_253 -3.754
FA1_VMFS_173 -4.660
Are you using the latest version? I fixed this issue in the last release
Hi Cody,
We are using the version 1.0, because the version 1.1 is showing the error below at the end of the output and is not listing the FlashArrays volumes, just the volumes of another storages:
Exception calling “ToInt32” with “2” argument(s): “Additional non-parsable characters are at the end of the string.”
Versions:
PowerCLI version is 6.5 Release 1 build 4624819
VMware vCenter Server Version 6.0.0 Build 5112529
Thank you!
Hi Cody
No we are using version 1.0.
We are getting the error below when running version 1.1:
Exception calling “ToInt32” with “2” argument(s): “Additional non-parsable characters are at the end of the string.”
Versions:
PowerCLI version is 6.5 Release 1 build 4624819
VMware vCenter Server Version 6.0.0 Build 5112529
Thanks.
Could you post your log possibly?
Cody
Please see below:
Connected to the following FlashArray(s):
10.2.4.235
—————————————————————————————————-
Connected to vCenter at srv-vcenter
—————————————————————————————————-
02/06/2017 09:59:01
The datastore named DSLocal-LabDF-DELL is being examined
The UUID for this volume is:
naa.6c81f660de4b73001a5863e11b461e17
The volume is not a FlashArray device, skipping…
—————————————————————————————————-
02/06/2017 09:59:01
The datastore named DSLocal-AC-DELL is being examined
The UUID for this volume is:
naa.6c81f660dcc816001a45cd711ad1bfd2
The volume is not a FlashArray device, skipping…
02/06/2017 09:59:05
The datastore named FA1_VMFS_150 is being examined
The UUID for this volume is:
naa.624a9370ccc97a81262845b800011085
The volume is on the FlashArray 10.2.4.235
This datastore is a Pure Storage volume named FA1_VMFS_150
Exception calling “ToInt32” with “2” argument(s): “Additional non-parsable characters are at the end of the string.”
Maybe we should just have a call about this. Could you open a Pure Storage support ticket and reference our conversation? We can track and troubleshoot this through that
Pretty new to PowerShell, not sure if this is OE or something wrong in the script….
At C:\Users\Ezra\Box Sync\operations\vendors\PureStorage\IdentifyDeadSpace.ps1:127 char:19
+
+ ~
The ‘<' operator is reserved for future use.
At C:\Users\Ezra\Box Sync\operations\vendors\PureStorage\IdentifyDeadSpace.ps1:131 char:19
+
+ ~
The ‘<' operator is reserved for future use.
At C:\Users\Ezra\Box Sync\operations\vendors\PureStorage\IdentifyDeadSpace.ps1:136 char:19
+
+ ~
The ‘<' operator is reserved for future use.
At C:\Users\Ezra\Box Sync\operations\vendors\PureStorage\IdentifyDeadSpace.ps1:141 char:19
+
+ ~
The ‘<' operator is reserved for future use.
At C:\Users\Ezra\Box Sync\operations\vendors\PureStorage\IdentifyDeadSpace.ps1:145 char:19
+
+ ~
The ‘<input name="utf8" type="hidden" value="✓" …
+ ~
The ampersand (&) character is not allowed. The & operator is reserved for future use; wrap an ampersand in double
quotation marks ("&") to pass it as part of a string.
At C:\Users\Ezra\Box Sync\operations\vendors\PureStorage\IdentifyDeadSpace.ps1:1946 char:10
+
+ ~
The ‘<' operator is reserved for future use.
At C:\Users\Ezra\Box Sync\operations\vendors\PureStorage\IdentifyDeadSpace.ps1:1961 char:24
+ © 2017 <span title="0.18997s from unicorn …
+ ~
The ampersand (&) character is not allowed. The & operator is reserved for future use; wrap an ampersand in double
quotation marks ("&") to pass it as part of a string.
At C:\Users\Ezra\Box Sync\operations\vendors\PureStorage\IdentifyDeadSpace.ps1:1961 char:36
+ © 2017 <span title="0.18997s from unicorn …
+ ~
The '<' operator is reserved for future use.
At C:\Users\Ezra\Box Sync\operations\vendors\PureStorage\IdentifyDeadSpace.ps1:1961 char:42
+ … 2017 GitHubGitHub’ in expression or statement.
Not all parse errors were reported. Correct the reported errors and try again.
+ CategoryInfo : ParserError: (:) [], ParseException
+ FullyQualifiedErrorId : RedirectionNotSupported
Ezra, it looks like you copy and pasted the GitHUB HTML (or more likely right-clicked and saved it). You need to go to the GitHub page and then copy/paste the code in the display box into a ps1 file.
Was there a solution to the negative numbers being returned by the script ? I have the latest 1.2 and the it returns negative GB numbers for the datastores..
Hmm, I thought I fixed it, but maybe I only fixed it in the actual UNMAP script. I will take a look. In short though all I do is round negatives to zero. In other words, those datastores with negatives are unlikely to have dead space or at least a lot of it.
Hi Cody, Brilliant script.
Is there any way to use the script to query 1 flash array but have multiple center(s)? or do i have to it one by one?
Ta
Thanks!! Well it is certainly possible–just not in the current state. It would just have to be altered to loop through the vCenters. At this point it is written just for a single vCenter. I will work on adding support to the script to do that.
Hi Cody. I’m sure the 1.2 version of the script is brilliant when it works, but if you take a look at my log, you’ll see that I get some strange results.
By the way, nothing is displayed in the Powershell window after the line “What virtual dead space threshold in GB do you want to limit the results to? (enter a number): 1”
The script writes a few empty lines and finishes as if it all is OK
The log file:
Connected to the following FlashArray(s):
10.32.15.230
—————————————————————————————————-
Connected to vCenter at xxxxxx.no
—————————————————————————————————-
25.05.2019 01.54.04
The datastore named Iso is being examined
This volume is not a VMFS volume, it is of type NFS and cannot be reclaimed. Skipping…
—————————————————————————————————-
25.05.2019 01.54.04
The datastore named PURW13-BGNHPC01-SYS-AAS-01 is being examined
The UUID for this volume is:
naa.624a93708818b0700bf631290034f312
The volume is on the FlashArray 10.32.15.230
This datastore is a Pure Storage volume named PURW13-BGNHPC01-SYS-AAS-01
This volume has -380 GB of dead space.
This is less than the specified UNMAP threshold of 1 GB and will be skipped.
—————————————————————————————————-
25.05.2019 01.54.04
The datastore named PURW13-BGNTST01-SYS-AAS-01 is being examined
The UUID for this volume is:
naa.624a93708818b0700bf631290034f364
The volume is on the FlashArray 10.32.15.230
This datastore is a Pure Storage volume named PURW13-BGNTST01-SYS-AAS-01
This volume has 137 GB of dead space.
This is greater than the specified UNMAP threshold of 1 GB and should be reclaimed.
—————————————————————————————————-
25.05.2019 01.54.04
The datastore named PURW13-BGNTST01-SYS-AAS-02 is being examined
The UUID for this volume is:
naa.624a93708818b0700bf63129003533e6
The volume is on the FlashArray 10.32.15.230
This datastore is a Pure Storage volume named PURW13-BGNTST01-SYS-AAS-02
This volume has -473 GB of dead space.
This is less than the specified UNMAP threshold of 1 GB and will be skipped.
—————————————————————————————————-
25.05.2019 01.54.05
The datastore named PURW13-BGNTST01-SYS-AAS-03 is being examined
The UUID for this volume is:
naa.624a93708818b0700bf6312900355c6f
The volume is on the FlashArray 10.32.15.230
This datastore is a Pure Storage volume named PURW13-BGNTST01-SYS-AAS-03
This volume has -918 GB of dead space.
This is less than the specified UNMAP threshold of 1 GB and will be skipped.
—————————————————————————————————-
25.05.2019 01.54.05
The datastore named PURW13-BGNTST01-SYS-AAS-04 is being examined
The UUID for this volume is:
naa.624a93708818b0700bf631290035ebc2
The volume is on the FlashArray 10.32.15.230
This datastore is a Pure Storage volume named PURW13-BGNTST01-SYS-AAS-04
This volume has -420 GB of dead space.
This is less than the specified UNMAP threshold of 1 GB and will be skipped.
—————————————————————————————————-
25.05.2019 01.54.05
The datastore named UNI01W13-BGNHPC01-DAT-ANN-01 is being examined
The UUID for this volume is:
naa.6006016087304200a3caaa5a9841fde3
The volume is not a FlashArray device, skipping…
—————————————————————————————————-
25.05.2019 01.54.05
The datastore named UNI01W13-BGNTST01-DAT-ANN-01 is being examined
The UUID for this volume is:
naa.60060160873042002d83ab5ab3f49878
The volume is not a FlashArray device, skipping…
—————————————————————————————————-
25.05.2019 01.54.05
The datastore named UNI01W13-BGNTST01-DAT-ANN-02 is being examined
The UUID for this volume is:
naa.600601608e304700a19c615b8d9ad106
The volume is not a FlashArray device, skipping…
—————————————————————————————————-
25.05.2019 01.54.05
The datastore named UNI01W13-BGNTST01-DAT-ANN-03 is being examined
The UUID for this volume is:
naa.6006016094304700ff580a5ce755f93e
The volume is not a FlashArray device, skipping…
—————————————————————————————————-
25.05.2019 01.54.05
The datastore named VeeamBackup_BCK-001.Bluegarden.Tst is being examined
This volume is not a VMFS volume, it is of type NFS and cannot be reclaimed. Skipping…
—————————————————————————————————-
25.05.2019 01.54.05
The datastore named bgnhpcesxd001.local is being examined
The UUID for this volume is:
naa.6d094660490fd900222bef8b9f4c55a4
The volume is not a FlashArray device, skipping…
—————————————————————————————————-
25.05.2019 01.54.05
The datastore named bgnhpcesxd002.local is being examined
The UUID for this volume is:
naa.6d094660490b9200222c06e0a1bb04d1
The volume is not a FlashArray device, skipping…
—————————————————————————————————-
25.05.2019 01.54.05
The datastore named bgnhpcesxd003.local is being examined
The UUID for this volume is:
naa.6d094660490b9600222bf06198985240
The volume is not a FlashArray device, skipping…
—————————————————————————————————-
25.05.2019 01.54.05
The datastore named bgntstesxd001.local is being examined
The UUID for this volume is:
naa.6d094660490fda00222bf0a1e9fac7f8
The volume is not a FlashArray device, skipping…
—————————————————————————————————-
25.05.2019 01.54.05
The datastore named bgntstesxd002.local is being examined
The UUID for this volume is:
naa.6d09466048de3400222bf7319b2082f1
The volume is not a FlashArray device, skipping…
—————————————————————————————————-
25.05.2019 01.54.05
The datastore named bgntstesxd003.local is being examined
The UUID for this volume is:
naa.6d09466048e46900222d4bc7a61d6313
The volume is not a FlashArray device, skipping…
—————————————————————————————————-
25.05.2019 01.54.05
The datastore named Iso is being examined
This volume is not a VMFS volume, it is of type NFS and cannot be reclaimed. Skipping…
—————————————————————————————————-
25.05.2019 01.54.05
The datastore named PURAC12-VODPROD-DAT-ANN-01 is being examined
The UUID for this volume is:
naa.624a9370884f142d3e67d302002fa2b8
ERROR: This volume has not been found. Please make sure that all of the FlashArrays presented to this vCenter are entered into this script.
—————————————————————————————————-
25.05.2019 01.54.05
The datastore named PURAC12-VODPROD-SYS-AAN-01 is being examined
The UUID for this volume is:
naa.624a9370884f142d3e67d3020019507e
ERROR: This volume has not been found. Please make sure that all of the FlashArrays presented to this vCenter are entered into this script.
—————————————————————————————————-
25.05.2019 01.54.05
The datastore named PURW13-VODPROD-DAT-ANN-01 is being examined
The UUID for this volume is:
naa.624a93708818b0700bf631290035fa12
The volume is on the FlashArray 10.32.15.230
This datastore is a Pure Storage volume named PURW13-VODPROD-DAT-ANN-01
Cannot convert argument “d”, with value: “-2 321”, for “Floor” to type “System.Double”: “Cannot convert value “-2 321” to type “System.Double”. Error: “Input string was not in a correct format.””
I think I need to update this script to use the logic I put in my UNMAP script (handling negatives). Though I dont write much to the screen–most of it here just goes to the log. My plan is to merge this into my module and just write to the debug log in Windows most likely.
Hi,
Will this script work if the datastore is formated with NFS? Does the storage array have to be all flash ( i think our EMC Unity is all flash or might be a hybrid, have to check)
Unfortunately no. This script was built to interact specifically with the FlashArray API and make comparisons with VMware metrics. So it will only work on the FlashArray. But conceptually could be used with other storage platforms if the script was updated for their API and how they report host written. But for NFS the problem shouldn’t quite exist–it depends on how the platform renegotiates space when a file (VM or VMDK) is deleted from the NFS mount. If the NFS mount is “thinly” provisioned I would hope it would do that. But that could only be answered by the folks at EMC