
I posted a few months back about ESXi queue depth limits and how it affects performance. Just recently, Pure Storage announced our upcoming support for vSphere Virtual Volumes. So, this begs the question, what changes with VVols when it comes to queuing? In a certain view, a lot. But conceptually, actually very little. Let’s dig into this a bit more. 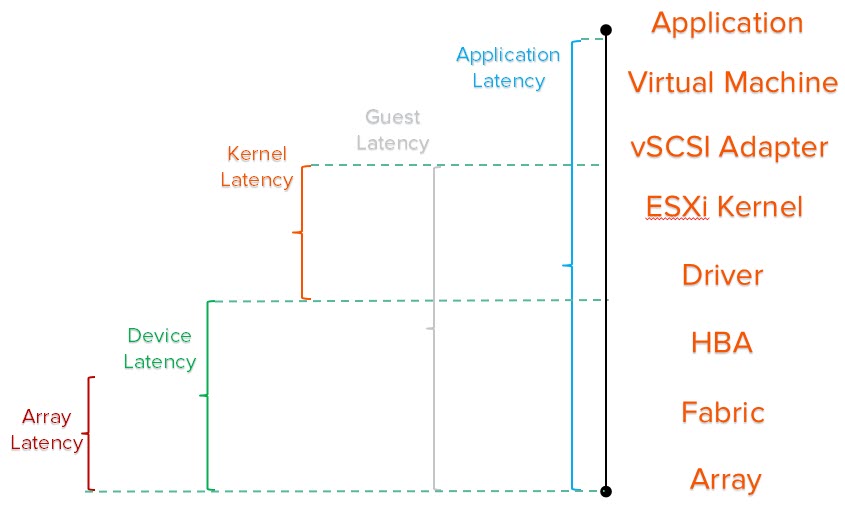
So to review, there are a few important queue depth limits:
- Array queue depth limit. This might be on a volume basis, or a target (port) basis or array basis. Or there might not be one, like in the case of the FlashArray we do not have a volume or target limit
- HBA queue depth limit. This indicates how many I/Os can be in-flight to all of the devices on a single HBA at once.
- HBA Device queue depth limit. This indicates how many I/Os can be in-flight to a given single device at once.
- Virtual SCSI adapter queue depth limit. This indicates how many I/Os can be in-flight to all of the disks on a single virtual SCSI adapter at once.
- Virtual device queue depth limit. This indicates how many I/Os can be in-flight to a given single virtual disk (or RDM) from a guest at once.
So what about protocol endpoints? Let’s review quickly what they are.
ESXi has device and path limitations (256 devices/1,024 logical paths in ESXi 6.0 and earlier, and those number doubled in 6.5). So presenting a VVol to a host in a normal way would very quickly exhaust available paths and devices. So it needed to be done in a different way. So virtual volumes use the concept of an administrative logical unit (ALU) and a subsidiary logical unit (SLU) (more info can be found here in a SAM-5 draft).
An ALU is a device that has other devices accessed through it as sub-LUN. Kind of like a mount point. A SLU is one of those sub-LUNs–it is only accessible via an ALU.
A protocol endpoint is a ALU. A VVol is a SLU. So a PE would have a LUN ID of let’s say 244 and a SLU “bound” to it would have a LUN ID of 243:4 for instance. Unlike with standard volumes, VMware supports much higher LUN addressing for SLUs (up to 16,383 or 0x3FFF).
So what this means you can have up to 16,383 VVols bound to a single PE. So a lot of VVols!
Understanding PE Queue Depth Handling
Which then begs the question: Will my PE be a performance bottleneck? All of the I/O for those VVols go to the PE and then are dealt with by the array. So the multi-pathing and queue depth limits are set on the PE. Let’s take a look at how queue depth limits work with PEs.
So first off, the storage array queue depth limit depends on the array, so ask your vendor. The FlashArray doesn’t have one, so any possible bottleneck on that front would be in ESXi (or eventually the array itself). From the guest perspective, nothing changes. PVSCSI settings and queues are identical to what happens with VMs on VMFS. So refer to my earlier post on that.
For standard volumes (VMFS or RDMs) the actual queue depth limit (called DQLEN) is calculated from the minimum of two values. and The HBA device queue depth limit and Disk.SchedNumReqOutstanding.
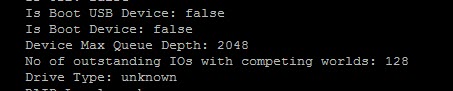
NOTE: DSRNO doesn’t really exist any more–as that was a host-wide setting retired in ESXi 5.5. It is now a per-device setting called “No of outstanding IOs with competing worlds”. I am just going to keep using the term DSRNO because it is just easier to type 🙂
The DSRNO setting for a standard device defaults to 32. In ESXi 6.0 and earlier this could be increased up to 256. In ESXi 6.5 this can be set to a maximum of whatever the current HBA device queue depth limit is.
Protocol endpoints do not default to 32. They default to 128 and this setting is controlled with a new setting called Scsi.ScsiVVolPESNRO–this is a host-wide setting.
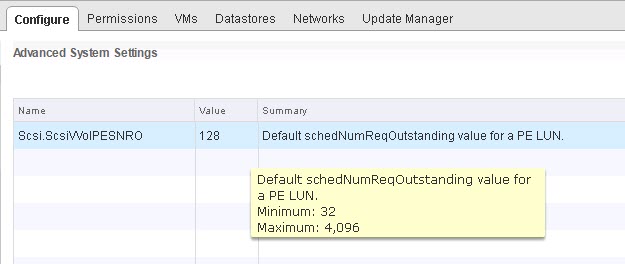
This can go up to 4,096. Quite high. Some notes on this setting:
- It is not an online change. If you change it, the PEs will not alter their queue depth limit. They will only upon restart
- There is no point to setting this higher than what the HBA device queue depth limit supports
- If a given PE’s PESNRO is manually overridden, it will ignore this value from that point on, as the manual setting will be observed.
Now, this setting just handles the default queue depth limit for a PE. But it can be set and handled individually as well. And doing this is no different than with a standard volume, you change the No of outstanding IOs with competing worlds value:
esxcli storage core device set -O <number> -d <naa>
This allows you to override this value for individual PEs, if you want. My PE below is presented via software iSCSI, so the default HBA device queue depth limit is 128. The default setting for Scsi.ScsiVVolPESNRO is also 128, so both are reflected as such in the esxcli storage core device list -d command:
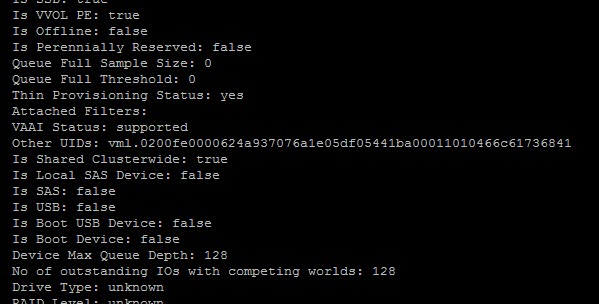
So if I want to up this setting for all PEs I could change Scsi.ScsiVVolPESNRO to whatever. Let’s say 256. But that would require a reboot. So the other option is to use the esxcli command. Individual PESNRO follows the same rule as DSRNO does though–it cannot be set higher than the HBA device queue depth limit. As seen above, my current HBA device queue depth limit is 128. So, if I try 256 it will fail:
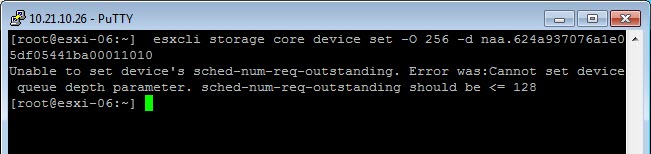
So, I need to up my HBA device queue depth limit, which requires a reboot.
esxcli system module parameters set -m iscsi_vmk -p iscsivmk_LunQDepth=2048
Now I can try to set the PESNRO on this specific PE to 256:
esxcli storage core device set -O 256 -d naa.624a937076a1e05df05441ba00011010
This time it works and my ” No of outstanding IOs with competing worlds” is up to 256. ![]()
Or I can make it up to 2,048 even:
So the point is, that the number of outstanding I/Os can be set very high for a protocol endpoint.
Do I need more than one PE?
Well this is really up to your storage vendor, and of course it depends on the underlying capabilities of a single PE. So, for the FlashArray instance where the physical device (PE) isn’t a bottleneck on the storage side, do I need more than one?
Unlikely.
The crux of this is a very simple equation referred to as Little’s Law:
“The long-term average number of customers in a stable system L is equal to the long-term average effective arrival rate, λ, multiplied by the average time a customer spends in the system, W.” –Wikipedia
So the equation looks like: L = λW
This is a fancy way of saying if it takes a certain amount of time to do a task, take a certain duration of time and divide it by the the task time and that is how many times it can be done in that specified duration if done in a serial fashion. Let’s take the fast food restaurant example. If it takes a customer 1 minute to be served, the store can help 60 customers in an hour (60 minutes/1 minute). This is the case of one register.
So. Let’s look at this from a storage latency perspective. Let’s say my average latency is 1.0 ms. I would usually expect it to be half that or even less, but let’s be conservative and say 1.
There are 1,000 milliseconds in a second. So, 1,000/1 is 1,000.
So this means with one outstanding I/O, I can do 1,000 IOPS. But with let’s say 256 outstanding I/Os I can therefore do 256,000 IOPS to that single PE from that host. Each host has it’s own queue. And a PE can be set much higher than 256. So there can be quite the parallelism from ESXi. With 4,096, this math works out to 8,192,000 IOPS per PE.
This is all somewhat theoretical at this point, just basing it off some early testing and simply running the numbers. But, I’d say at least for the FlashArray one PE per array should be fine. I will update this as I do more testing–look for my best practices document for VVols close to our actual GA.
Hi Cody
Presumably using FlashArray, more than one PE won’t actually cause any issues either?
Nope. Using more than one is perfectly fine. Of course until I complete testing and we go GA I cannot 100% confirm anything
Hi,
i’ve observed issue with ansible module purefa_info with more than one PE per FA.
Mind reporting this in the Pure Code Slack team in the #ansible channel? You can self-register at code.purestorage.com. If you can’t let me know and I will try to follow up on this.
I reported this issue via email to our local support contact during the proof of concept of FA. Assuming it got lost on the way. Simply said:
When I have a second PE named ‘Test’ (or whatever) on the FA purefa_info crashes with stack trace. It seems it does not expect more than one PE. The problem disappears if i remove PE ‘Test’ from FA’s configuration.
Interested part of the trace:
…ansible/modules/storage/purestorage/purefa_info.py\”, line 986, in main\n
…ansible/modules/storage/purestorage/purefa_info.py\”, line 660, in generate_vol_dict\nKeyError: ‘Test’\n”
I will chase this down with the Ansible folks. Thanks!!! Sorry to hear that it got lost in the fold
Hey Cody,
I know this slightly off topic for this post, but will there be an easy process of transitioning from typical LUN based datastores to a VVOL approach with PURE?
Thanks man, love your website.
You’re welcome! Thank you! Glad you like it. Yup, to move a VM from VMFS to VVols you just use Storage vMotion. Nice and simple.
Hello Cody!
I always come back here to visit your articles, from time to time I learn a different thing from same article, its incredible. Congrats.
There is a gap in my knowledge about VVols and PEs, and I will be very glad to hear a word from you about this topic!
In a tradition VMFS-Centric approach VMware developed several technologies in order to relief the performance problems. We can see VMFS datastore clusters with Storage DRS balancing for latency for example. In fact, as you already known those technologies combines regular storage vMotion operations to migrate “hot” VMs from one datastore to another.
Please can you explain how VVols deals about this problem, as we can see storage DRS is not supported for VVols?
Thank you! Glad to hear it is useful!
Yeah it is a bit of a different situation. SIOC (which is the underpinning of SDRS) is based on a file system performance test, which is a 4k random read injector, that doesn’t really have a place in VVols. Since the VVol datastore isnt a file system, where does the performance test go? A PE? But that might be used by other datastores.
So there are a couple things here. First off, because of the separation of the management path (the VVol datastore) and the data path (the PE), SDRS is lost on the VVol river without a paddle. It needs a major update for it to work there. If updated, should it issue rebinds to different PEs? Should it move to different arrays? Should it have the array reconfigure it? Simply moving to a different PE or different datastore doesnt mean it will solve a performance problem, or potentially even a capacity issue. Ideally storage policies should control the performance levels of the VM and the array should be doing what it can to adhere to them, if there is issue, the VM should be issued a compliance alert. Let me write a deeper blog post on this question–as its a good question.
From a Pure perspective we are working on this in a few ways. Improving our QoS support, better insight into VVols with Pure1 and the array “total load” meter and a few other things.
Also working on the SDRS question as there is still value to be had there, but it needs an overhaul. SIOC and SDRS were built with spindles in mind–which isnt much of a reality for VMFS today, and rarely VVols.
Is it possible to access volumes connected via protocol endpoint under Linux? I.e. without VMware or VASA provider involved.
Suppose the protocol endpoint (PE) itself is accessible via iSCSI (as /dev/sdw below), two volumes are connected to Linux host via the PE using Pure Storage FA REST API.
The ‘REPORT LUNS’ finds the sub-LUNs as ‘subsidiary elements’:
# sg_luns –decode /dev/sdw
Lun list length = 16 which imples 2 lun entries
Report luns [select_report=0x0]:
00fee20000000001
>>Administrative element:
Simple lu addressing: 254
>>Subsidiary element:
Long extended flat space addressing: lun=1
00fee20000000002
>>Administrative element:
Simple lu addressing: 254
>>Subsidiary element:
Long extended flat space addressing: lun=2
But how do I access/mount these sub-LUNs as devices?