
I have been talking a lot about Virtual Volumes (VVols) lately with customers and when I describe what they are a frequent response is “oh so basically RDMs then?”. ..
…ugh sorry I just threw up in my mouth a bit…
The answer to that is an unequivocal “no” of course, but the question deserves a thorough response.
So first let’s look at how they are the same, then let’s look at their differences. And not just how they compare to RDMs, but also VMDKs as you traditionally know them.
First off, as you are aware, a virtual machine can have many “drives”. Every drive is presented to a virtual machine via a storage adapter (Paravirtual SCSI, LSI Logic etc). To review:
Each drive can be either a virtual disk or a raw device mapping.
A virtual disk can be one of the following:
- A standalone file. Colloquially, this is what is often referred to as a virtual disk/VMDK. Each drive is a file on a file system (NFS or VMFS) that is presented to a VM to look like a standalone SCSI volume. Writes are actually stored in the file. Each array volume can hold many of these. All I/O goes through the virtual SCSI stack.

- A VVol. Each VVol is a volume on the array. Reads and writes do not go to a file, as there isn’t one. I/O goes through the virtual SCSI stack, so the guest does not have direct access to the volume and therefore it looks like a VMware “virtual” disk to the OS.
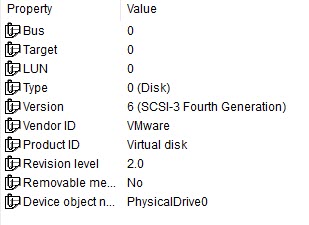
A Raw Device Mapping (RDM) is one of the two:
- Physical mode. Each pRDM is a volume on an array. No I/Os go through the virtual SCSI stack, instead the VM has direct access to the volume with minor exceptions. The OS sees the volume as presented by the array.
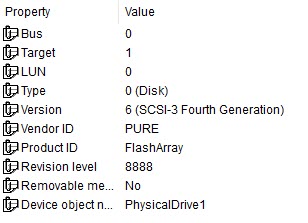
- Virtual mode. Each vRDM is a volume on an array. I/O goes through the virtual SCSI stack, so the guest does not have direct access to the volume and therefore it looks like a VMware “virtual” disk to the OS.

So with the exception of a pRDM, the base inquiry data is rather similar for the other types.
So I am going to cover the differences between VMDKs, pRDMs, vRDMs and VVols. I will focus on the following areas for each:
- Creation–How are they created?
- Performance–do they perform differently?
- Dead Space–How friendly are they to removing dead space on the array and using UNMAP? How are they deleted?
- SCSI Rescans–Do they require frequent rescans? Rescans can be expensive, especially in large environments. Really reducing how quickly and easily you can provision storage.
- Migration/Cloning–how are they cloned/migrated?
- Portability–how much do they lock in your data?
- Snapshots–how are they snapshotted?
- Restore–How easily can they be restored if deleted?
- Clustering–Can it be used with MS failover clustering?
There are certainly more, but I think those are a good place to start.
I will compare them all, but at the end, I will discuss one of the real benefits that VVol clearly has above over all of these methods.
Virtual Disks vs. VVols
So first off let’s compare a “standard” virtual disk and a VVol. For brevity’s sake, I will refer to a standard virtual disks henceforth as a vmdk. There are some similarities of course.
Creation
First off, both can be created on demand. There is no need provision storage every time you need a new one. The difference of course is that with a vmdk, a file is created on a VMFS/NFS. With VVols, an actual volume is created on the array.
Winner: VVol
Performance
This depends. A thin VMDK needs to allocate space and also zero upon new writes. A VVol never needs to do this. So there is a difference in performance for first writes if the VMDK is thin. If the VMDK is zeroedthick, VMware does not need to allocate space, but it does need to zero for new writes. So there is also a performance difference for zeroedthick VMDKs compared to VVols. If the VMDK is eagerzeroedthick, there is no zeroing on demand, so the performance difference is negligible or zero.
Winner: VVol. Worse case–performance is the same.
Dead Space
Furthermore, when deleted, the object is removed. So for a vmdk, the file is removed. For a VVol, the actual volume is deleted on the array. The difference here is that when you delete a vmdk, you need to run UNMAP to tell the array the space has been reclaimed. With a VVol, there is no need–the volume gets removed so the array knows the space is no longer needed, so no UNMAP! Also, when files are deleted in a VMDK, that space is stranded on the array. To reclaim it, a variety of VMware requirements need to be satisfied, and if so, the guest can issue UNMAP to the VMDK, which ESXi will shrink and then ESXi issues UNMAP to the array. Somewhat complex. With a VVol, the guest OS can issue UNMAP directly the array (there’s no VMDK in the way). Much cleaner.
Winner: VVol
SCSI Rescans
This segment is of course not relevant to NFS, just block.
When you present a new VMFS, you must rescan and format it everytime. Copies of VMFS volumes require rescan and resignature. For VMDKs, you do not need to rescan every time you create a new one, but if you need a new datastore, or if you need to expand one, or copy one, you need to rescan.
With VVols, only one rescan if ever really needed. You create a single protocol endpoint once (this can be somewhat vendor specific, so ask you vendor). Once created, rescan the host and you are done rescanning for that array forever. When VVols are created, they are presented through the PE as a sub lun (the PE is LUN 255 and the VVol is LUN 255:5 for instance). VVols are seen via REPORT LUNs to the PE, not a SCSI bus rescan. REPORT LUNs is far less expensive and much more expedient as compared to a SCSI bus rescan.
Lastly, VVols, unlike VMFS, does not consume a SCSI slot or additional logical paths. As these are both limited in number by ESXi. Only the one PE does. Under that you can have 16,383 VVols per each PE per host if needed.
Winner: VVol
Migration/Cloning
They can both be Storage vMotioned. They can both be cloned. Though there is a major difference here. These operations are MUCH faster with VVols as compared to vmdks (somewhat depending on the array architecture). When cloning or storage vMotioning vmdks, the VAAI primitive XCOPY is used, so 1000’s of XCOPY SCSI commands need to be sent to the array to describe where the vmdk is and also where it needs to be. Then the array copies/moves it. This makes it faster, but certainly not instant and especially large VMDKs can still take a good deal of time.
With VVols, each object is a volume, so the array doesn’t need 1000’s of command to be told what to do. It really just needs 1 (copy this volume). Therefore, they can directly leverage their snapshot/cloning mechanism to do this all at once. This can make it tremendously fast. With the example of the Pure Storage FlashArray, when we clone volumes it is a metadata copy. So for all intents and purposes, we can copy any size volume instantaneously. I did a test cloning 100, 500 GB VMDKs with XCOPY and it took about 24 minutes. When I did it with the same data but on 100, 500 GB VVols, it took 93 seconds. Frankly, I think I can do even better if I improve the parallelization of my PowerCLI script.
I will note that these technologies only come into play when cloning/migration within the same array (XCOPY or VVol array cloning). When moving between arrays they both use the standard network copy. That being said, work is underway to allow array based replication to assist in this process for VVols, so stay tuned.
Winner: VVol
Portability
The main issue with a VMDK can be portability. Without host-based copying, or a converter of some sort VMDKs can’t really be used by anything but VMware. A VMDK encapsulates the file system of the guest inside of a VMDK which is further encapsulated on another file system. Want to present it to a physical server? Want to present it to another hypervisor? Want to send it to the public cloud for dev/test (or whatever)? Not really doable without some work.
VVols are portable. VMware does not change the way a file system is laid down on the physical volume on the array. They do not encapsulate the file system. You want to present the data in a VVol to a physical server? Connect a copy (or even the VVol itself!) to a physical server as a regular LUN connection. Present it to a Hyper-V VM as a pass-through disk. Present it to an older version of ESXi as an RDM even.
A feature we are adding to the FlashArray next year is CloudSnap– two parts of CloudSnap are sending an array snapshot to S3 to be sent to glacier for long term retention, or brought up in EBS for an EC2 instance in AWS. You can send your VMware snapshots to the cloud in other words!
VVols enable all of this.
Winner: VVol
Snapshots
Both VMDKs and VVols can be snapshotted inside of VMware (right-click on VM and create snapshot). Though this is dramatically different.
VMDK snapshots are delta files that store the changes–the VM runs from the delta snapshot. So there is a performance impact to their creation and existence–in the form of significantly increased latency. Even deleting them is quite impactful. The changes have to be reconsolidated back into the base disk–which incurs a lot of additional I/O and takes a long time. See a blog post on all of this here. In short, they are bad times. Practicality dictates that you do not keep these around long. Limiting their usefulness to really just “I’m about to make a change, protect me until I know that change didn’t break anything”.
You can create array based snapshots of vmdks, but it is actually of the datastore, so you are snapshotting possibly many, many VMDKs as well, which you may not want. Plus without integration, quiescing isn’t really an option.
With VVols, a VMware snapshot is an array-based snapshot. ESXi tells the array what VVols are presented to that VM and which ones to snapshot. Furthermore, you can still take advantage of VMware tools quiescing, or memory state preservation. Importantly, unlike manually creating array snapshots of a VMFS–they are granular (one snapshot for each VVol) and can be managed just like always through vCenter (created, restored to, deleted). Lastly, they take advantage of whatever the underlying array has to offer with their snapshots. So like with the Pure Storage FlashArray, zero performance impact and can be created/restored from/copied instantly.
Since, unlike VMDKs and VMware snapshots, the VM still runs from the source, not the delta snapshot (see a good post on that here), those snapshots can be used for other things. First off, they can be kept for a much longer time if needed without worrying about performance. Because they are granular array snapshots–they are simply just snapshots of a volume with a file system (whatever the guest put on it–ext4, XFS, NTFS, whatever). So you could literally take a VMware-created snapshot of a VVol and present a copy of it to a physical server, or another VM, or whatever. Definitely a lot of possibilities here, worthy of its own upcoming blog post.
Winner: VVol
Restore
If you accidentally remove a VMDK and choose “delete from disk”, recovering it is not guaranteed. If you do not have backup, or an array-based snapshot you are out of luck.
With VVols, arrays can help you here. Like with the FlashArray (and a few others too), when you delete any volume (VVol or otherwise), it goes into a temporary recycling bin for 24 hours. Therefore, even if you have no array snapshots, or backup, you have an option to restore it within a day of the incident. Remember though, this is just what VVols enable the array to do, not all arrays do this–so certainly understand your arrays behavior before you rely on this. And please, I am not saying don’t use backup! This just gives you a nice, easy, fast way to restore a VM VVol in case of an accidental deletion.
Winner: VVol
Clustering
Microsoft Failover Clustering is only supported with traditional VMFS-based virtual disks if the disk type is eagerzeroedthick AND all of the cluster VMs are on the same ESXi host. Fairly limiting. VVols do support MSFC and the VMs can be on different ESXi hosts, but you do need to be on ESXi 6.7 U1, but the multipathing algorithm must be on FIXED or MRU for the PE. The ability to use Round Robin should be resolved by VMware soon.
Winner: VVol, but this gap will widen soon.
pRDM and VVol
Creation
Creating a RDM is a bit of a process. Create the volume on the array, connect it to the host, rescan, then add it the VM. Creating a VVol is only the last part–adding to the VM. The rest of the process is automated natively by VMware.
Winner: VVol
Performance
A VVol is basically a RDM–there is no allocating of space, there is no zeroing on demand. It is just writes to the FlashArray. So it is a wash there. The only possible exception here is that a pRDM has its own queue depth limit. VVols share the queue depth limit of a PE. With that being said, people rarely hit the queue depth limit of a RDM anyways and furthermore a PE has a much higher default queue depth limit than a RDM has. So it is pretty much a wash here.
Winner: Tie.
Dead Space
In-guest dead space is handled almost identically by a pRDM and a VVol–a VMDK does not intercept the I/O, therefore allowing a guest to issue UNMAP directly to the array. So they are tied somewhat there.
Where they differ is when they are deleted.
When a pRDM is deleted from a VM, just the association is removed. So the volume is still presented to ESXi and still exists on the array. So you need to disconnect it from the host(s) then delete it on the array. Consequently, it can be easy to miss removing it and it can end up being stranded, forgotten and alone on the array, wasting capacity.
When a VVol is deleted–the array is informed and the volume is removed from the array automatically.
Winner: VVol
SCSI Rescans
Any time you need a new pRDM, you need to rescan your host. Everytime you remove one, to clean up ESXi, you need to rescan.
No need for this for VVols. Other than the initial PE of course. ‘Nuff said.
Winner: VVol
Migration/Cloning
Something like Storage vMotion of a VM with a pRDM is not really possible. You can relocate the virtual machines’ files, but the data on the RDM will stay on that RDM. Moving the data from an RDM to another volume requires going to the array to use array based tools. Or you can shut the VM down and run a Storage vMotion, but that will just convert the RDM into a VMDK–which you may not want. RDM to RDM migration has never been too easy.
VVols support Storage vMotion within one array, or to another array entirely. All entirely within VMware.
The same issue exists with cloning, VMware cannot clone a pRDM–you need to use array-based tools/plugins.
VVols can be cloned entirely inside of VMware.
Winner: VVol
Portability
Since pRDMs are individual volumes on the array with no file encapsulation, they offer great portability between VMware and everything else–this is the primary reason for their existence these days.
The same case for VVols.
Winner: Tied
Snapshots
VMware does not provide the ability to create snapshots of pRDMs, so you need to go to the array and create them manually. You can use plugins of course to make this easier. Also they allow you to use things like in-guest VSS to quiesce and create a snapshot on the array if your array/application supports it. The nice thing is that they are drive granular and since they are array-based they can be used for many things and kept around longer.
VMware supports creating array-based snapshots of VVols, plus the benefits of memory preservation or VMware tools-induced quiescing. Since they are array-based you get all of the same benefits but with the additional benefit of being able to create and manage them within VMware natively.
Winner: VVol
Restoring
If you delete an RDM from a virtual machine the volume is not immediately deleted, so there is some recourse, because to really remove it you need to go to the array. Furthermore, like on the FlashArray, the recycling bin offers additional protection.
VVols, when deleted from the VM are removed from the array, so especially if you don’t have recycling bin-type protection on the array, you are more prone to fully delete a VVol as compared to an RDM, due to the simple nature that to delete a RDM you really need to mean it–there are a lot of steps to do delete one. Which is benefit or disadvantage depending on how you look at it, but looking solely at restore protection, I guess I have to give the edge to pRDMs.
Winner: pRDM
Clustering
pRDMs are supported with MSFC, and the VMs can be on the same ESXi host or different ones and the round robin algorithm is supported and it can be done with all ESXi versions. VVols requires 6.7 U1 and must be set to FIXED.
Winner: pRDMs, but this gap will shorten soon.
vRDM and VVol
Creation
Same differences as pRDM, see that section.
Winner: VVol
Performance
Same differences as pRDM, see that section.
Winner: Tie.
Dead Space
Same differences as pRDM, see that section.
Winner: VVol
SCSI Rescans
Same differences as pRDM, see that section.
Winner: VVol
Migration/Cloning
Similar limitations exist with vRDMs as with pRDMs when it comes to migration. No capability to move to a new RDM. Though, unlike pRDMs, you can move it online from a vRDM to a vmdk.
Cloning is possible online as well for vRDMs, but only from vRDM to a vmdk.
As stated many times before, Storage vMotion and cloning of VVols is fully supported, integrated, and super fast.
Winner: VVol
Portability
Same differences as pRDM, see that section.
Winner: Tied
Snapshots
vRDM snapshots can be snapshotted by VMware (using the delta file technique) and you can also create snapshots by using array-tools. So slightly better than pRDMs because you can use VMware-integrated snapshots to protect it (of course along with all of those pesky downsides) and you can use array-snapshots at a granular level, though they have to be created, managed, and deleted external of VMware.
VVols provide both–VMware snapshots that are actually granular array snapshots that are managed within VMware. And of course you also have the option to create array snapshots of VVols outside of VMware that VMware won’t know about. So the best of both worlds.
Winner: VVol
Restoring
Same differences as pRDM, see that section.
Winner: VVol
Clustering
Microsoft Failover Clustering is only supported with vRDMs if all of the cluster VMs are on the same ESXi host. Fairly limiting. VVols do support MSFC and the VMs can be on different ESXi hosts, but you do need to be on ESXi 6.7 U1, but the multipathing algorithm must be on FIXED or MRU for the PE. The ability to use Round Robin should be resolved by VMware soon.
Winner: VVol
But wait, there’s more!
So one could argue well most of this stuff is just block issues, NFS doesn’t suffer from this. That’s true to a certain extent, rescans etc. Things around granularity too. But it still has disadvantages above (portability etc.).
But regardless, there is one major benefit that VVols have that blows everything else out of the water. This is storage policy based management.
When VVols are created you can specify a configuration policy (replication, snapshots, location, whatever…).
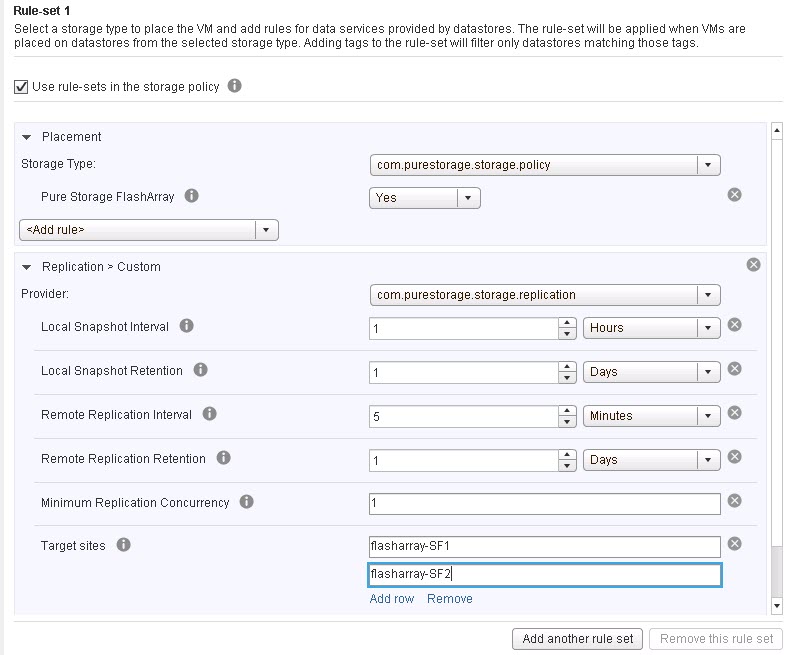
When you go to create a new VM, or add a new virtual disk, you can choose a policy you created and VMware will tell you what storage can satisfy it.
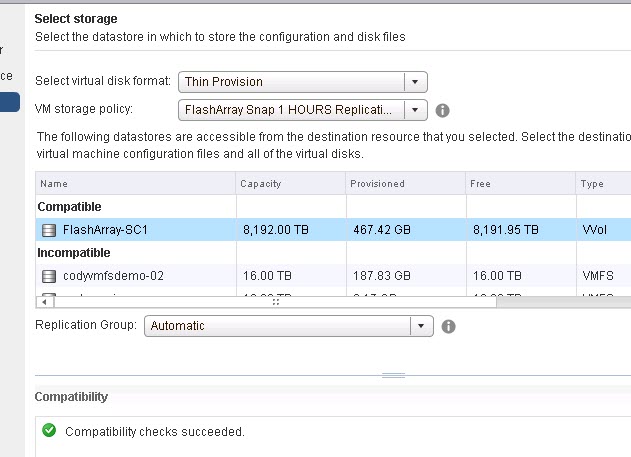
You can somewhat do this today, with plugins I guess, but it is on the datastore level and not integrated into vCenter (just the GUI) and/or it is at the datastore level, not the VM or virtual drive level. Or you can use RDMs, but you lose a lot from VMware when you do.
When you choose the right target that is compatible, vCenter will have the array create the VVols and apply the correct array capabilities to them as dictated by the selected policy.
VVols and SPBM integrates array capabilities and volume configuration into the intelligence of vCenter provisioning. But this isn’t just initial day zero provisioning but also day 2 compliance.
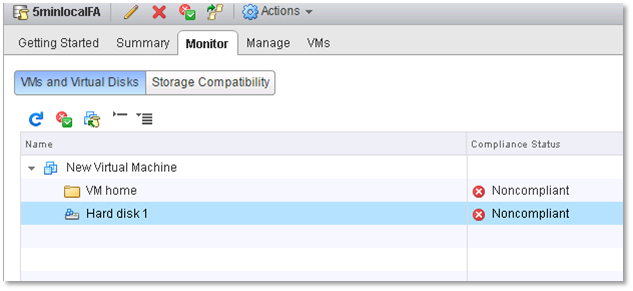
If someone manually override your VVol configuration on your array, vCenter marks that VM or individual VVol as non-compliant. So you can either go to the array and fix it, or re-run it through the configuration wizard to apply the proper configuration. So you can, initially configure VVols, maintain and monitor them or change them as needed.
The point to take home: VMware realized all of the current tradeoffs you have with earlier options (VMDKs and RDMs) and built VVols specifically to avoid having to choose which disadvantage you can live with. With the additional benefit of letting array vendors value add on top of it even more.
Our org was recently told that Pure Active Array (for HA purposes) is not currently available for vvol datastores, and that VMDK is necessary for that purpose.
Do we have a feel for if that might be available in the future, and when that might be?
Or, are there other replication schemes you could do between two Flash Arrays (same datacenter, different physical racks and power) using vvol datastores?
Last year we converted to vvols and like how fast they are, but we’d like to get into an Active HA situation.
Thanks.
If you’re referring to ActiveCluster and vVols yes it is currently not supported. We are currently scoping the next vvol projects now that we shipped the latest. I’ll have a better idea in the coming months