
If you are Pure Storage customer and you recently logged into Pure1 (which is our cloud-based management/analytics/support portal), you might have noticed a notification the first time you logged in this week:
What is this? Well this is the great thing about Pure1–we just add features all of the time and this is an exciting one. Two years or so ago I wrote this blog post:
Understanding VMware ESXi Queuing and the FlashArray
That went into storage troubleshooting with ESXi. Got a lot of positive feedback on that and also a lot of questions–it was a situation where people definitely needed more helpful tools to identify performance issues, or simply just to track who was doing what and where.
https://blog.purestorage.com/vm-analytics-now-available-in-pure1/
This week we introduced what we call “VM Analytics” to Pure1. All customers get it for free.
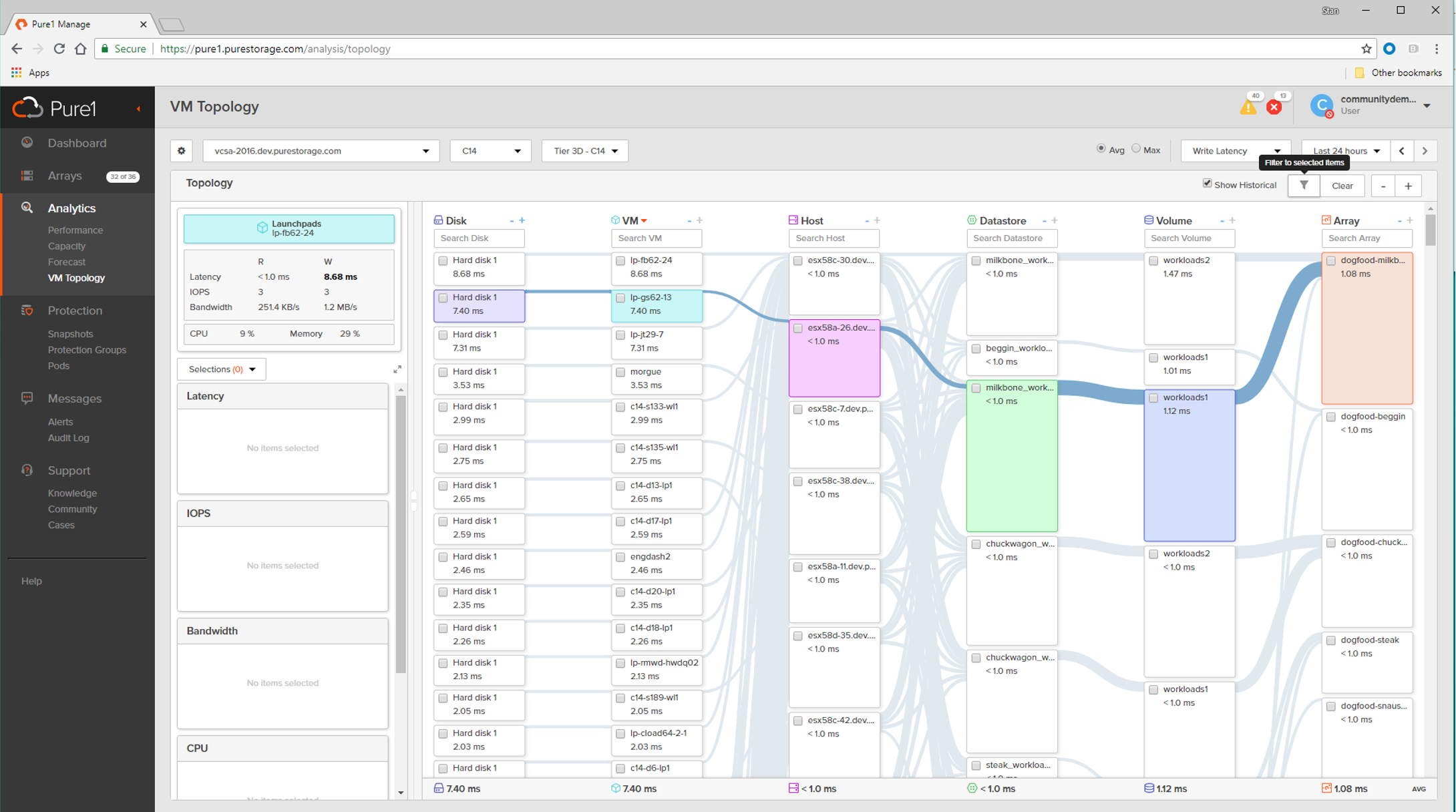
How does it work? Well, first, you configure a collector. There are two options for this. We can either run the collector inside of a FlashArray (it runs inside of our Purity/Run platform as a docker container) or you can instantiate the container on docker yourself as an off array collector. The collector then is authorized to one or more vCenters (read-only creds are fine) and pulls in your VM topologies and metrics. It pulls in:
- VMs
- Virtual Disks
- Datastores
- Hosts
- Clusters
- Datacenters
From a metric standpoint, it pulls in the relevant metrics for VMs, Datastores, Virtual disks, and hosts:
- IOPS (R and W)
- Throughput (R and W)
- Latency (R and W)
- CPU
- Memory
Each vCenter is polled every 10 minutes and then this information then gets dialed home back to Pure1 hourly. Inside of Pure1, you can now see you VMware topology. Sort VMs or their disks by latency, IOPS etc. What VM is where? What datastore is on what FlashArray? What are the latency differences through the stack?
So before we dive into how you use it, let’s go through setting it up.
As I mentioned there are two methods for the collector on array or off array. For on array, just simply open a Pure support case and ask for it. What are the requirements?
-
Purity 4.10.x (preferably latest)
-
M20 or higher
Fairly straight forward. If you do not have at least one array that matches those requirements, fear not–the off array collector is for you. Let’s walk through setup.
On-Array Collector vs Off-Array
Personally I am a fan of the off array collector–it is super easy to setup, you just need a vanilla Ubuntu VM and the collector takes only a few minutes to setup at most. And you can do it entirely yourself, no need to call support.
I would recommend the on-array in two scenarios:
- Your network cannot route out. In this case your Ubuntu VM cannot talk to the internet and cannot download what you need for the collector.
- You cant/dont use Ubuntu.
Install the On Array Collector
Call Pure support–they do all the work for you.
Default credentials are pureuser/pureuser. You can find the connection IP to SSH to by logging into your FlashArray GUI:
Install the Off Array Collector
IGNORE THIS. It is now a simple OVA:
https://www.codyhosterman.com/2019/10/vm-analytics-collector-now-an-ova/
For a VERY DETAILED step-by-step process go see this blog post
https://www.codyhosterman.com/2018/10/configuring-pure1-vm-analytics-detailed-guide/
If you know how to install/configure Ubuntu this post should do just fine, so continue on.
NOTE: if you had support configure the on array collector you can skip all of this and go to the section on Configuring the collector.
The step is to login to pure1.
https://pure1.purestorage.com/
Click on VM Topology then the gear icon that says “Collector configuration” when you hover over it.
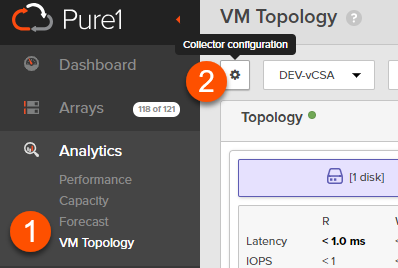
In the pop-up that appears, click Create Collector and enter a name for your collector.
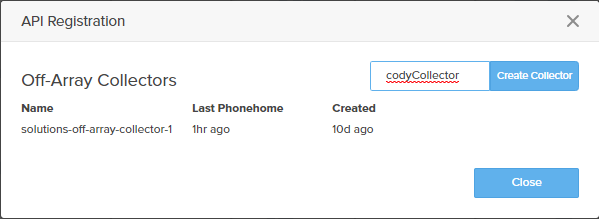
There are no real requirements on this name, this is just a friendly name for you to use as a reference.
This will add a collector instance. If you hover to the right of it, you can click on “View installation script”. 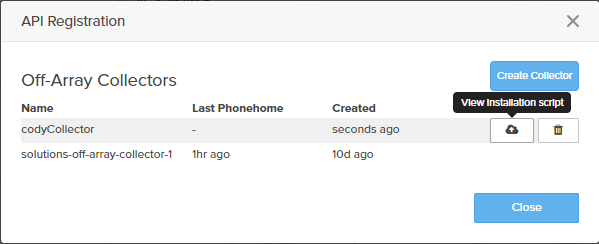
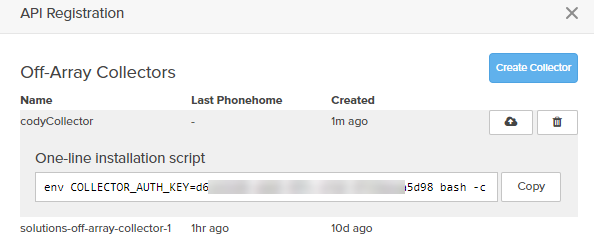
Click copy and save this for later.
The next step is to configure my collector. In this case, I have a Ubuntu 16.04.1 VM:
A pretty bare bones Ubuntu installation at this point. The following are the requirements:
-
Ubuntu 16.04
-
x86_64 cpu with at least 2 cores Minimum 2GB RAM
-
Docker EE 1.11.2 or newer, or CE 17.03 or newer
-
python 3.5.2 or later
-
logrotate, and cron installed and running
I have python 3.5.2 already:
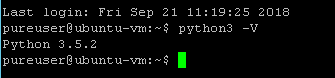
If you do not have it installed, install it. I won’t cover it here but there are plenty of blogs out there that walk through that–it is pretty straight forward.
Next to install Docker–I will go with CE. I will also not walk through this, because there is a great and accurate resource here:
https://docs.docker.com/install/linux/docker-ce/ubuntu/#install-docker-ce-1
This walks through installing it. Follow ALL of the instructions (step 1-4 under SET UP THE REPOSITORY and step 1 and 2 under INSTALL DOCKER CE).
Do not skip the apt-get updates (there are two). Configure the repository and then install Docker. Just run the commands listed in that page. Takes a minute or so.
When you are done you should have Docker ready to go:
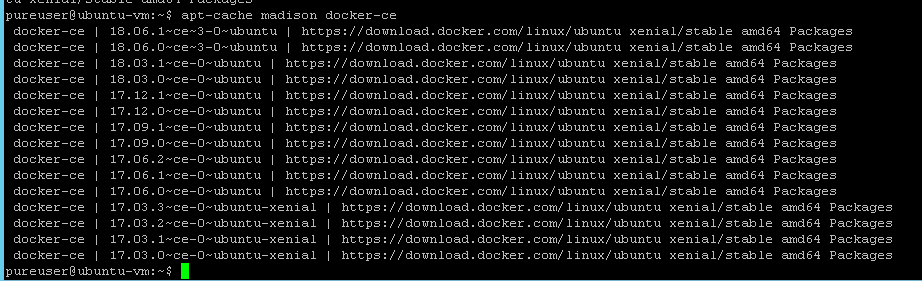
Lastly, set logrotate to hourly:![]()
Now install the collector. Grab that script you copied from Pure1. Mine is:
env COLLECTOR_AUTH_KEY=dxxxxxxxxxxxxxxxxxx8 bash -c "$(wget -O - https://static.pure1.purestorage.com/vm-analytics-collector/install.sh)"
Run that now. You will likely have to add sudo to it. If you forget, it will remind you.
This will not take long (10-20 seconds). It will download the necessary files and install the collector.
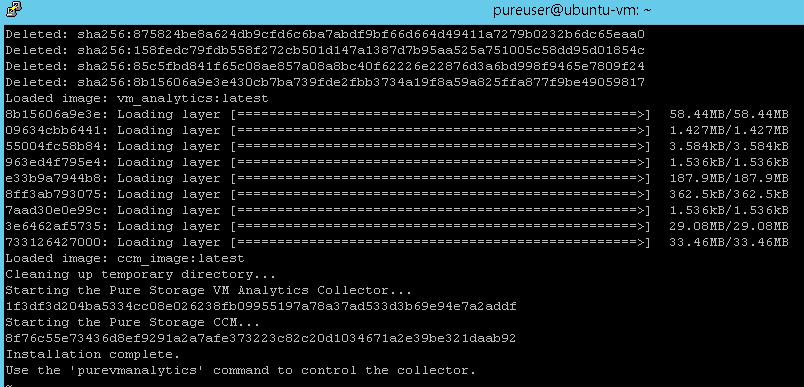
Done!
Configure the Collector
If you are using the off-array collector, just SSH into that VM. If you are using the on-array collector, SSH into the Docker VM support configured for you.
Now authenticate with vCenter! I will add three of mine using the purevmanalytics command:
You should add sudo here too likely.
sudo purevmanalytics connect --hostname <hostname>--username <username> --password <password>

You can review the status with purevmanalytics list:

You’re done! You should see data starting to populate in Pure1 in an hour or so.
Verifying/Checking Logs
The collector puts its logs here:
/var/log/docker/vm_analytics
You can look at the phonehome status in the ccm log and general collection information in the vmanalytics.log file.
Also you can check in Pure1 for the last time the collector has phoned home:
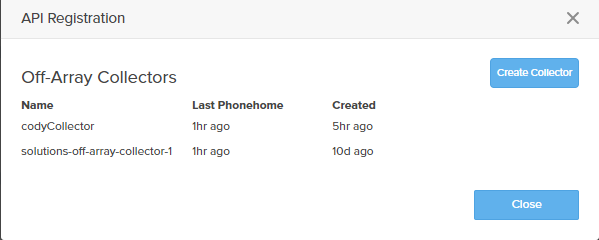
Note that it might take a few hours for the first metrics to show up. Even if you force a phonehome. If the logs have not rolled over yet, nothing will be sent.
FAQ
Some basic questions:
Do I need many collectors?
No usually. As long as the collector can reach all of your vCenters, you do not need to have more than one. If the networks are firewalled, then you might though if a given collector and not reach a certain vCenter.
Do I need to authenticate my FlashArrays?
No. They dial home themselves, Pure1 already has their information/metrics.
What are the network requirements?
Refer to this:
Can I force a phone home?
Yes for the off-array collector only though. purevmanalytics phonehome.
What FlashArray models does it support?
While the collector can only run on certain FlashArray models–all support FlashArrays are supported with the feature itself. So 400 series, //m and //x. They will all show up and be available in the Pure1 topology.
VMware support?
vCenter 5.5 and later.
Does it support VVols? RDMs? VMFS?
Today this supports VMFS and RDMs. VVols support is coming.
Hyper-V?
Not today (2018). This is VMware only at this point, but it will change.
In the next post, I will go over using it and what you can see in Pure1.
Hi mate,
With the Off Array Collector are you able to add multiple SANs to a single Ubuntu server under a separate container or will you require one server per SAN?
The considerations are twofold. First off the collector doesn’t need to talk to any FlashArrays—it only collects from vCenters. It then dials that information home. The FlashArrays dial home their own information separately. So it only needs access to your vCenters. So you only need more than one collector if you have vCenters that are on completely different networks. If a collector can route to every vCenter over the IP network you really only need one. That’s the primary consideration. The other consideration is if you have multiple organizations within Pure1. If you have more than one organization in Pure1 it means that different users or groups from your company can login to Pure1 but they see totally distinct FlashArrays. In this case you would need a different collector for each org. In general, most customers will likely need only one.
Thanks for the clarification, the information i got from Pure support was one collector per array, but since it is brand new they may not have all the information yet.
Hi.
Can you tell me what firewall rules are required ?
Can it work through a proxy server ?
Our implementation is behind a corporate firewall and proxy server.
Here is a link to requirements:
https://support.purestorage.com/Pure1/Pure1_Manage/001_Overview/Pure1_Manage_-_VM_Topology
The short answer is that it should work but I do not believe it was tested in time for GA–so there is no documentation on this currently. I have already received this question twice in two days, so I have it on my list as a priority to look into
Hello Cody, I read the ubuntu 16.04 is used, the 18.04 doesn’t work with purevmanalytics ?
Just as long as it is 16.04 or later you are fine
Strangely the installation works with a 18.04 but no data goes in Pure1. I follow the documentation with a 16.04 and it works perfectly fine.
Have a nice Weekend
Just found out that 18.04 does not currently work, engineering is working on fixing it for the next release. Apparently there are some issues with DNS configuration that need to be resolved.There is a workaround though:
The workaround is to:
Deactivate systemd-resolved:
pure@docker:~$ sudo systemctl disable systemd-resolved.service
Stop systemd-resolved:
pure@docker:~$ sudo service systemd-resolved stop
Remove the symlink to /etc/resolv.conf
pure@docker:~$ sudo rm /etc/resolv.conf
Create a new resolv.conf file
pure@docker:~$ sudo touch /etc/resolv.conf
Configure your nameservers
Your /etc/resolv.conf should look like this afterwards:
pure@docker:~$ cat /etc/resolv.conf
nameserver 8.8.8.8
search mydomain.com
Re-Install the VM Analytics Collector: bash -c “$(wget -O – https://static.pure1.purestorage.com/vm-analytics-collector/install.sh)”
pure@docker:~$ sudo env COLLECTOR_AUTH_KEY=
Was I actually supposed the run that exact last line to re-install the connector? I ran it and now when I run my script I get Exception: Specified key xxxxxx-xxx-xxxx-xxxx-xxxxxx does not match existing key xxxxxxxx-xxxx-xxxx-xxxx-xxxxx. Pure suggested I rebuild my server. thx
Sorry for the delay here. Probably that is the right move, once the key has been generated it might be tied to some UUID that gets generated upon install that won’t allow it to be used again. I will dig into that. We are working on making this an OVA, so a lot of this stuff will change in the future. Let me know how it goes
Ok, il will try it monday, thx a lot.
Great, let me know how it goes. Enjoy the weekend!
The workaround seems to be working, the “last phonehome” has info now.
Thanks a lot.
Great! You’re welcome
What permissions does the account the collector need in vcenter? I’m assuming Read Only will work?
Yup read only is fine
Hey Cody,
Just wanted to say thanks for the blog post on this.
Saved me a call to support or some google time around setting logrotate to hourly.
Glad I could help!
This should be an OVA.
Consider the man hours wasted over all the Purestorage installs.
We have something in the works–we want to do OVAs right and we have a plan for it. But waiting for it would delay this significantly. So stay tuned.
Thanks for a cool tool. We would be fine with an OVA. If this isn’t possible, we would like to get the required modules listed so that we can deploy this in RedHat. Either option is fine.
You’re welcome! We are actively working on both of those options. I suspect RedHat will come sooner than the OVA though.
Great article, works like a charm, thanks for this Cody
Best
Markus
Great post. Works fine for me. Thanks!
Hi Cody!
This is a great tool and provides a lot of information. We had the off-array collector deployed soon after it was GA.
Eagerly waiting for Pure to add an option to export the information to CSV or PDFs in the future.
Glad to hear you like it! We have a lot of plans to improve it as well–though I do not believe that is planned in the near term.
Hi Cody,
We’re using active cluster. Our Purity version is 5.1.7. Which configuration is recommended, on-array collector or off-array?
I’d probably personally go with off-array. Running it on-array takes some resources, and AC also has some overhead, so probably best to leave the resources for the array to do its thing. But there really isn’t a best practice on it. If you have the resources on the array, go for it. You can always retire the on array and move to the off array. With that being said, if Pure1 says your busy meter is 70% or more, I would definitely go the off array route. The on-array is a bit simpler to set up, since you don’t need your own VM. But the difference isnt stark enough to make me want one over the other.
Hi Cody,
VM analytics works great and give detailed stats on Pure datastore. We also have datastores provisioned on other storage vendor’s device. I noticed that VM analytics also gives stats on virtual host and non-Pure datastore level, but not in VM level. Can I trust the stats of virtual host and non-Pure datastore?
Glad to hear you like it! We should report on everything above the storage for non-pure storage. If the VM information doesn’t show up that is a incorrect I believe. Open a support case to verify. Anything below the datastore will only be reported if it is Pure Storage. The stats we do report are just pulled from vCenter–so if you trust those stats these can be trusted as well. We do not manipulate the data, just pass it from vCenter to Pure1
What the status of the OVA?
I have a meeting today to finalize the start of the project. But I do not have a timeline as to release–yet. To be clear, we do not plan on just releasing an simple OVA just for the collector and moving on, we want to do this right and we want the OVA to be useful for many other things beyond the collector, so we plan on putting a lot of effort into it, so it will not be a short project. In the long run, we think it will much better for users of any integration we offer that requires something to run in outside of the array
I have deployed the VM fine with no issues. I still dont see any data populated ? it has been 3 hours now ? can you help here Cody ?
So this generally is one of a few reasons:
-The original install failed for some reason and it was retried on the same VM or a different VM with the same collector ID. Due to certificate/security communication depending on how where it failed this either of these can cause issues with communication to Pure1
-Proxy. If you use a proxy, it cannot route to Pure1. This not being configured correctly is a common cause.
-Time. Sometimes you just need to wait a bit longer. Check the CCM log in the collector, see if it is communicating properly, if there are no errors, wait a bit more
-Something wrong in the Pure1 account. Sometimes things get screwed up in the backend, and support needs to reconnect/reassociate things for you.
-Log rotate not being set to hourly. Default is daily, which will cause things to wait a long time
-Firewall misconfiguration–pure1 cannot be reached at all if the firewall blocks it
Usually one of these things. We are working on improving this process (big part of this will be the OVA). But adding better checks, logging and alerting on issues.
Thank You Cody. I did check all the basic things. I will open up a case with support now.
Hi Cody,
I would like to access pure1 API through proxy. Using python 3 on RHEL.
What means this exactly:
“-Proxy. If you use a proxy, it cannot route to Pure1. This not being configured correctly is a common cause.”
How can I access pure1 through proxy?
I have tried to configure https_proxy shell env variable, but no luck.
Thanks!
StoraGee
Hmm. I know we had a customer get this working, they said it worked on our Code channel. Anyways, we are adding this feature directly to our python toolkit, the code hasn’t been checked in yet, but it will be soon (as you are the 2nd person in two days to ask me). So open a ticket if you havent so they can let you know when it is resolved. Or join our Code Slack channel as we will note it there too
Also on a putty session to collector , It is showing Last collection is completed @ a particular time and state as idle but doesnt show any on pure1 web page – which is interesting !
Could still be a dial home issue. Collection just means it is pulling stats from vCenter fine. CCM log will display if there is some kind of communication issue with Pure1. If there is nothing it could be a org issue in Pure1 that support has to fix. We plan on improving the status reporting, because most issues are not talking to vCenter, but Pure1.
Thank You Cody. I will check with support.
I had to “re-do” my collector. When I try to authenticate vCenter, i receive an error message. Error: Duplicate name
Any ideas?
You can disregard my issue. Its working now.
Ah okay cool. BTW we have an OVA coming out VERY soon, so this will be a much better process
Cody,
Will the OVA be running 16.04 or 18.04?
Hi!
About the best practices: wich role its neccesary to connect to Pure Analytics Collector?
purevmanalytics connect –hostname –username –password
Hi! sorry, I saw it https://www.codyhosterman.com/2020/01/read-only-users-for-pure1-vm-analytics/