
I recently was doing some troubleshooting for a customer that was using my UNMAP PowerCLI script and discovered a change in ESXi 5.5+ UNMAP. The issue was that the script was taking quite a while to complete. After some logic optimizations and increasing timeouts the script was sped up a bit and less timeout errors occurred, but a bunch of the UNMAP operations were still taking a lot longer than expected. Eventually we threw our hands up and said it was good enough. A bit more recently, I was testing a 3rd party UNMAP tool and ran into similar behavior so I dug into it a bit more and found some semi-unexpected changes in how UNMAP works, specifically the behavior when leveraging non-default block iteration counts.
Long story short, the new best practice for UNMAP block counts with the Pure Storage FlashArray will be 1% or less of the free space of a VMFS datastore, this is instead of a static number recommendation. This is because ESXi will now override any block count that is above 1% of the free capacity for the target VMFS datastore–therefore you should make the block count as large as possible to receive the best UNMAP duration improvement. This recommendation (for simplicity) will be for all versions of ESXi 5.5 and 6.0. Read on if you want to know more about why this has changed.
***Update, I have confirmed this behavior with VMware engineering. Our documentation (and theirs) will be updated***
The details…
For some history, ESXi 5.5+ uses an improved version of UNMAP as compared to 5.0 and 5.1–it allows you to indicate an iteration block count when running an UNMAP operation on a VMFS datastore instead of just executing against all of the free space at once. Essentially whatever amount you indicate, it will UNMAP that amount of space at a time and then move on and repeat until the entire free space on the datastore has been reclaimed (default is 200 MB). In my testing I found that increasing this block count on the Pure Storage FlashArray dramatically decreases the time to UNMAP the datastore, from tens of minutes down to tens of seconds or less.
***UPDATE July 13th 2015*** I have also found out that if the target datastore is 75% or more full, the block count will ALWAYS be overridden to 200 blocks.***
A note, I will be referring to block and MB interchangeably because on VMFS 5, 1 block is almost invariably 1 MB.
The original testing I did to verify this recommendation was on ESXi 5.5, 5.5 U1 and 5.5 U2.
Anyways, in testing a 3rd party UNMAP product (I will blog about that product specifically soon) and simultaneously sanity testing vSphere 6.0 with the existing recommendation, I found that UNMAP operations were taking an inordinate amount of time even when using larger block counts (the recommendation was 60,000 blocks, in other words 60 GB at a time). So either there was a bug or something had changed.
I took a look at esxtop to see if anything jumped out from the VAAI UNMAP stats and sure enough the MBDEL/s column was much lower than I would expect for the entered 60,000 MB I entered into the UNMAP command.
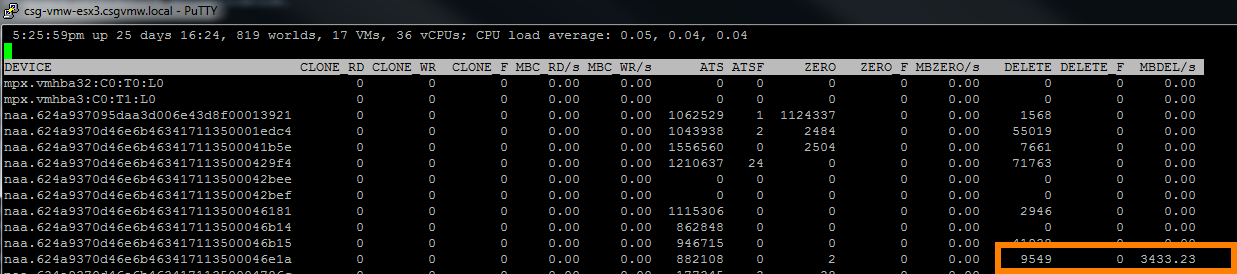
Of course, what esxtop reports isn’t necessarily an exact science, but it was definitely indicating that ESXi was not using the block count I told it to. ESXi, I figured, had to log that somewhere. So after tailing some different logs, I found that the hostd log does indeed do this. It show what ESXi is actually using when running UNMAP by listing how many blocks each iteration is reclaiming at once during the UNMAP operation. Each iteration is logged, below is an excerpt from the end of an operation:
Unmap: Async Unmapped 200 blocks from volume 5572373e-751a763c-b2b3-90e2ba392084
Unmap: Async Unmapped 200 blocks from volume 5572373e-751a763c-b2b3-90e2ba392084
Unmap: Async Unmapped 200 blocks from volume 5572373e-751a763c-b2b3-90e2ba392084
Unmap: Async Unmapped 200 blocks from volume 5572373e-751a763c-b2b3-90e2ba392084
Unmap: Async Unmapped 145 blocks from volume 5572373e-751a763c-b2b3-90e2ba392084
Unmap: Done : Total Unmapped blocks from volume 5572373e-751a763c-b2b3-90e2ba392084 : 944945
This is the tail end of an UNMAP operation, as you can see, the reclamation procedure is issuing UNMAP to 200 blocks per iteration until the very end where it issues it to only 145 blocks–this is because that was the only remaining free space on the volume, there wasn’t enough to do a full iteration of 200 MB (in other words the total free space wasn’t divisible by 200 MB).
As a side note, it is also important to understand that the last log line about total “Unmapped” blocks does not indicate how much space will actually be reclaimed on the array–it is actually highly unlikely that all or even most of that space is dirty, so actual reclaimed physical space will always be much less than that number. That line just reports on how much logical space UNMAP was issued to.
Anyways, so we can see that it was overriding my 60,000 block count and using 200, which is why it was super slow. What if I entered something smaller? Like let’s say 1,500 blocks? Also, the datastore I am using is 1 TB in size.
esxcli storage vmfs unmap -l UNMAP_DS1 -n 1500
Looking at my hostd log, I see:
Unmap: Async Unmapped 1500 blocks from volume 5572373e-751a763c-b2b3-90e2ba392084
Hmm, so it does not ALWAYS override it. So using a smaller number doesn’t get overridden. So the question is what is the threshold? Using the good old divide and conquer sorting method for my particular 1 TB volume I narrowed my exact maximum block count to 9,449. 9,450 would revert to 200 blocks, but 9,449 and lower were fine. After testing with different sized volumes this number also varied, up and down. So something to do with capacity, but what exactly…
After looking at various numbers, it had to do with free capacity, not total volume size. Remember that last line in the UNMAP procedure in the hostd log?
Unmap: Done : Total Unmapped blocks from volume 5572373e-751a763c-b2b3-90e2ba392084 : 944945
That number look familiar? 94,445? My number for UNMAP (9,445) happens to be 1% of the free capacity (with the decimal rounded off). After testing this with a variety of volume sizes, and more importantly various free capacities, the threshold was always 1% of the free space. Since the block counts are in megabytes, calculate the 1 % threshold off of the number of MB of free space. So if you are calculating from the GUI and it is in GB:
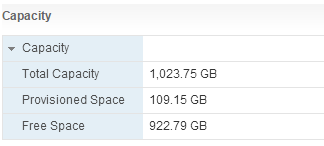
Take free space in GB, multiply by 1,024 to make it MB and then multiply by 1 % and round off the decimal point to get the maximum allowed block count:
922.79 * 1,024 *.01 = 9449.3696
Maximum block count is 9,449 for that volume.
With larger volumes the Web Client reports capacities in TB, so this value gets rounded a bit more so you will probably have to lower the value a bit. But personally, I would recommend not using the Web Client at all to get this information. PowerCLI is a much better option!
Such as:
$datastore = get-datastore <datastore name>
$blockcount = [math]::floor($datastore.FreeSpaceMB * .01)
That will change free capacity into a rounded off number and then give you the proper block count for any given datastore. Throw that number ($blockcount in the above instance) into an UNMAP command and you will be good to go.
My UNMAP PowerCLI script is updated to reflect this new best practice.
Support/Versioning/More info…
The final question is when was this change introduced. I first noticed this in ESXi 6.0, but it looks like this is not when this change was made. I have narrowed it down to ESXi 5.5 Patch 3, also known as build 2143827. Any build of 5.5 later than this will behave as described above.
I have not seen this behavior documented anywhere yet, well at least not directly. About six months or so I was involved in a few UNMAP escalations with VMware where hosts could experience physical CPU lockups and subsequently a purple screen during UNMAP when non-default block sizes were used (this was a storage vendor agnostic problem). It seemed to happen for sufficiently large volumes that were also rather full. A VMware fix was released to address this and eventually rolled into P3 and later. My original understanding is that it would override any non-default block count when it matched the situation (large, full VMFS) where a purple screen could potentially occur. It looks like that is not exactly what was done. Instead it will override only when the block count is above 1% of the free capacity for a VMFS of any size.
Conclusion.
So if you are on this ESXi level, change your UNMAP scripts (or download my new one) to alter the block count number to 1% of the free space. In the end you may not have as fast UNMAP operations as you did before when they successfully used very large counts, but you will use the largest value now that VMware supports for that given volume configuration, providing you with the fastest UNMAP times that will not cause a purple screen.
So if you are not on this ESXi version yet (in the 5.5 branch) and are using the 5.5 version of UNMAP, I highly, highly recommend upgrading. Then also alter your scripts or processes or whatever to reflect this behavior change.
Does this script also works with Purity 3.4.9?
Kind of. The UNMAP process will work fine, but I make a bunch of REST calls in the script, before and after each VMFS datastore UNMAP operation to report on how much space has been actually reclaimed. Those calls use REST version 1.2 which is only in Purity 4.x, so those calls will fail. The space will be still be reclaimed. So you can run it successfully, you will just see a bunch of REST errors.
Thanks! Is it also possible to point to more then one pure vip in the script? Now you get the REST output only from one off the systems.
It is certainly possible, just the script needs to be enhanced to do it. This has been on my to-do list, but I have not had a chance to do it
Thanks, Cody! This explains why I’ve never experienced the super-fast UNMAP performance that you’ve always advertised–because I’ve been above build 2143827 since before we deployed Pure. ‘Appreciate you sleuthing this out!
You’re welcome! Yeah this has been happening more and more, and I thought I was losing my mind! Finally decided it was possible I wasn’t nuts and dug into this. Let me know if you see anything different
Excellent troubleshooting here Cody and thanks for the information!
Thanks! And you’re welcome! This behavior was bothering me for some time, glad I finally got to the bottom of it.
I can’t help but feel the UNMAP restrictions in ESXi were introduced due to issues with only a small number of arrays. Modern arrays (both flash or disk/hybrid) should be able to handle large swaths of UNMAP just fine.
Well this change actually has nothing to do with the storage underneath, it still will issue large amounts of UNMAP simultaneously if the volume is large. This is more of a processing issue from the hostd process side. If there is a large amount of fragmented meta data large counts can cause an issue, this change was to help essentially eliminate the chance of that. The move of UNMAP from vmkfstools and how it did it to esxcli was more about getting around issues legacy arrays had.
Great article!
Thanks Cody!
Nice blog dude, helped us today!