Hello- this is part 4 in the series of blogs on ActiveDR + NFS datastores. In part 3, I covered how to configure vSphere for a test failover and then how to perform a test failover. In this blog I’ll be covering how to perform a failover and failback.
FlashArray Failure – ActiveDR Failover
What happens if an array fails? I’m going to forcefully stop Purity on both controllers of the source FlashArray (flasharray-x50-1) to simulate this situation. In this case, the workflow is the same as during the failover test except disconnecting the networking from the VMs you are about to power on. It is probably not a good idea to disconnect that so in general, you’ll want to leave these VMs as-is for this scenario. The requirements of your environment might require something else here. So you’ll promote the surviving array and power on the VMs based on the last-replicated state of the VMs.
If this is a test you are doing in a test/proof of concept deployment, to replicate what I’m doing, simply unplug the power cables on the FlashArray. Please do not pull power on your production FlashArrays :-). Here’s a table of articles in this series:
Hello- Nelson Elam here. I wanted to go over the reasons why I think you should enable automatic directory management (autodir) if you are planning to use NFS datastores on FA File. A quick note before we get started- autodir is not restricted to ESXi hosts but ESXi hosts will be the focus of this blog.
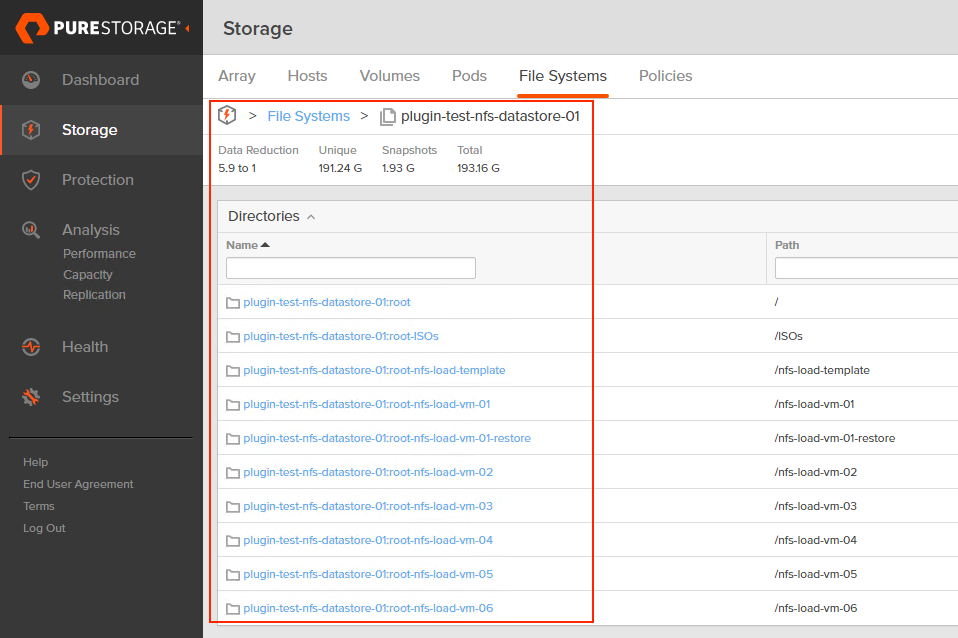
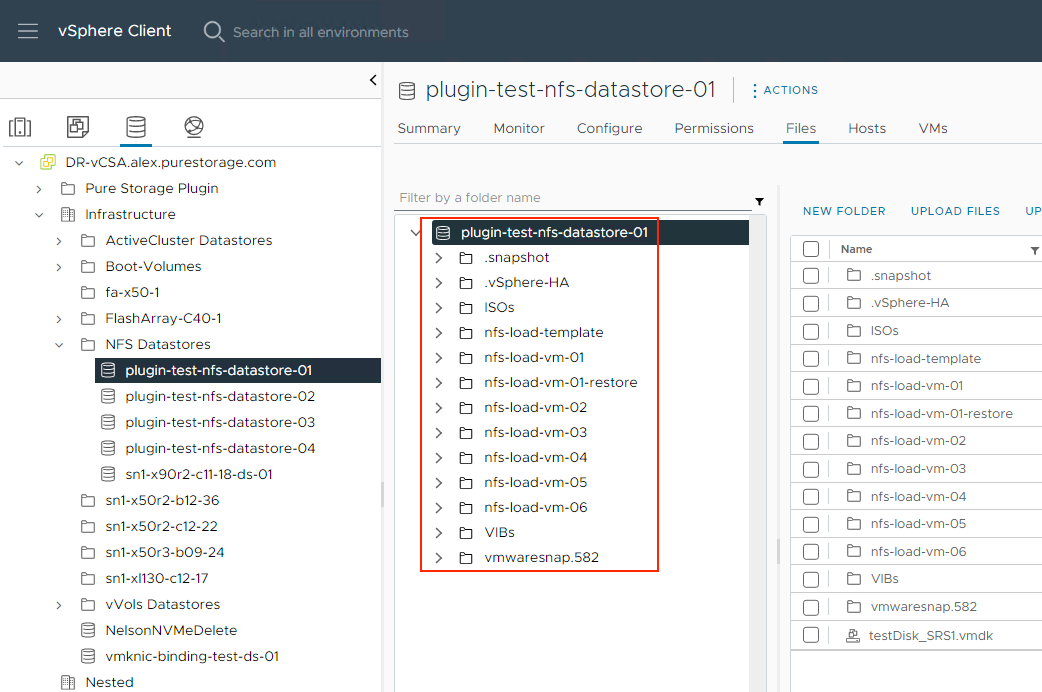
What is autodir? Autodir is a way for FlashArray to reflect the current directory structure on an NFS datastore that’s managed by a connected host- a managed directory. What does this mean for ESXi? Whenever a VM gets created on an NFS datastore, a new directory (folder) gets created for the VM on the datastore. When a VM gets deleted from disk, the directory gets destroyed. Note that directories you create or destroy manually on an NFS datastore in vCenter get reflected in FlashArray as well. Simple enough!
If you’ve read the FA File launch blogs or have seen some of the webinars we’ve done about FA File or NFS datastores, you’ve likely seen or heard us talk about VM granular management being part of FA File. Autodir enables VM granular management. Let’s dive into VM granular management in the context of NFS datastores.
With autodir enabled, these changes are reflected on FlashArray and enable FlashArray administrators to be able to see the current state of the NFS file system from a directory perspective.
Want to figure out why the data reduction ratio of a file system dropped so significantly? Now you can see that at a per-VM basis on FlashArray.
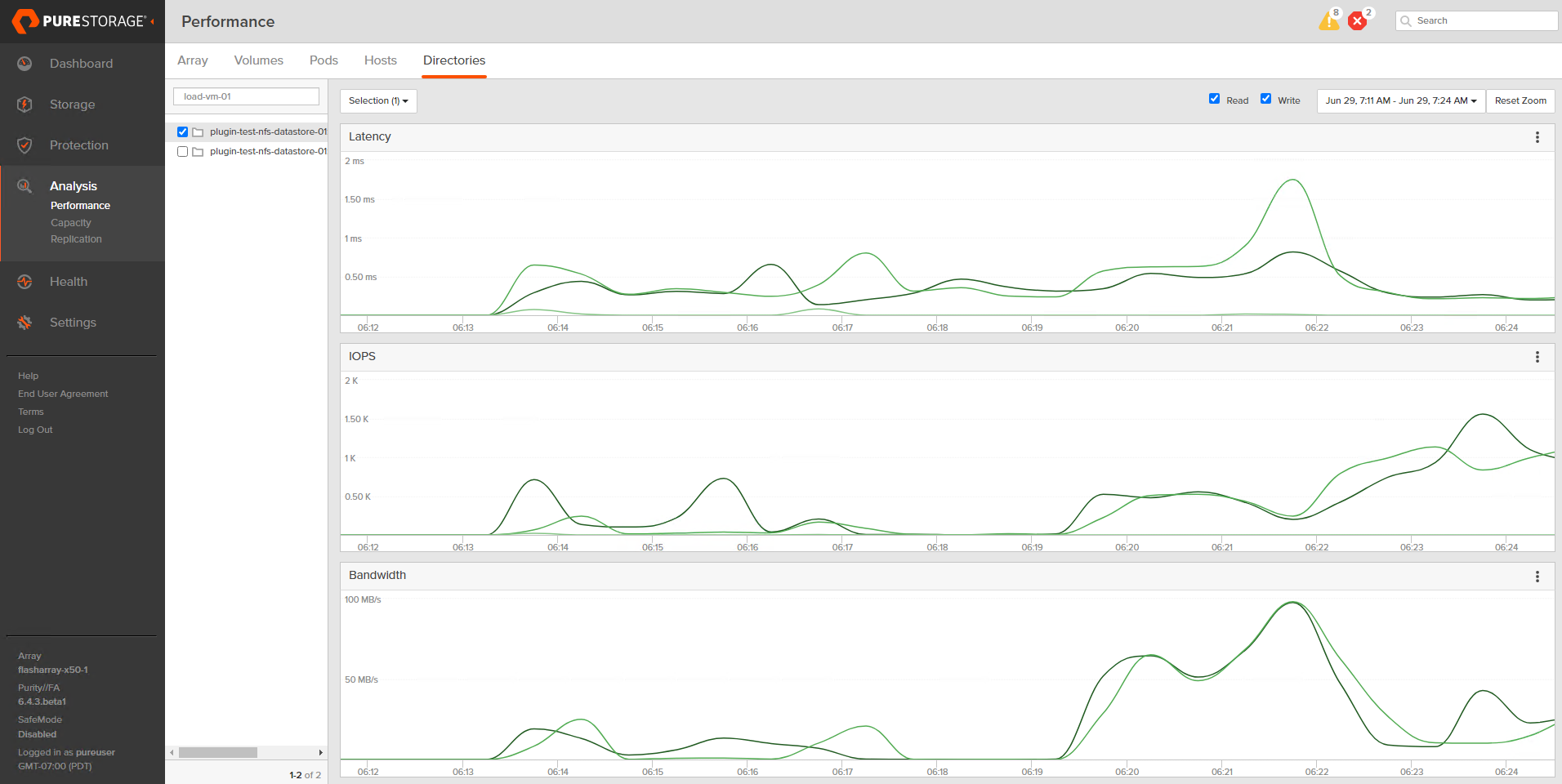
Want to see which VMs are spiking in load at inopportune times? You can use the FlashArray GUI to help figure that out. Worth mentioning this info is more easily consumed in Pure1 when using the VM analytics collector.
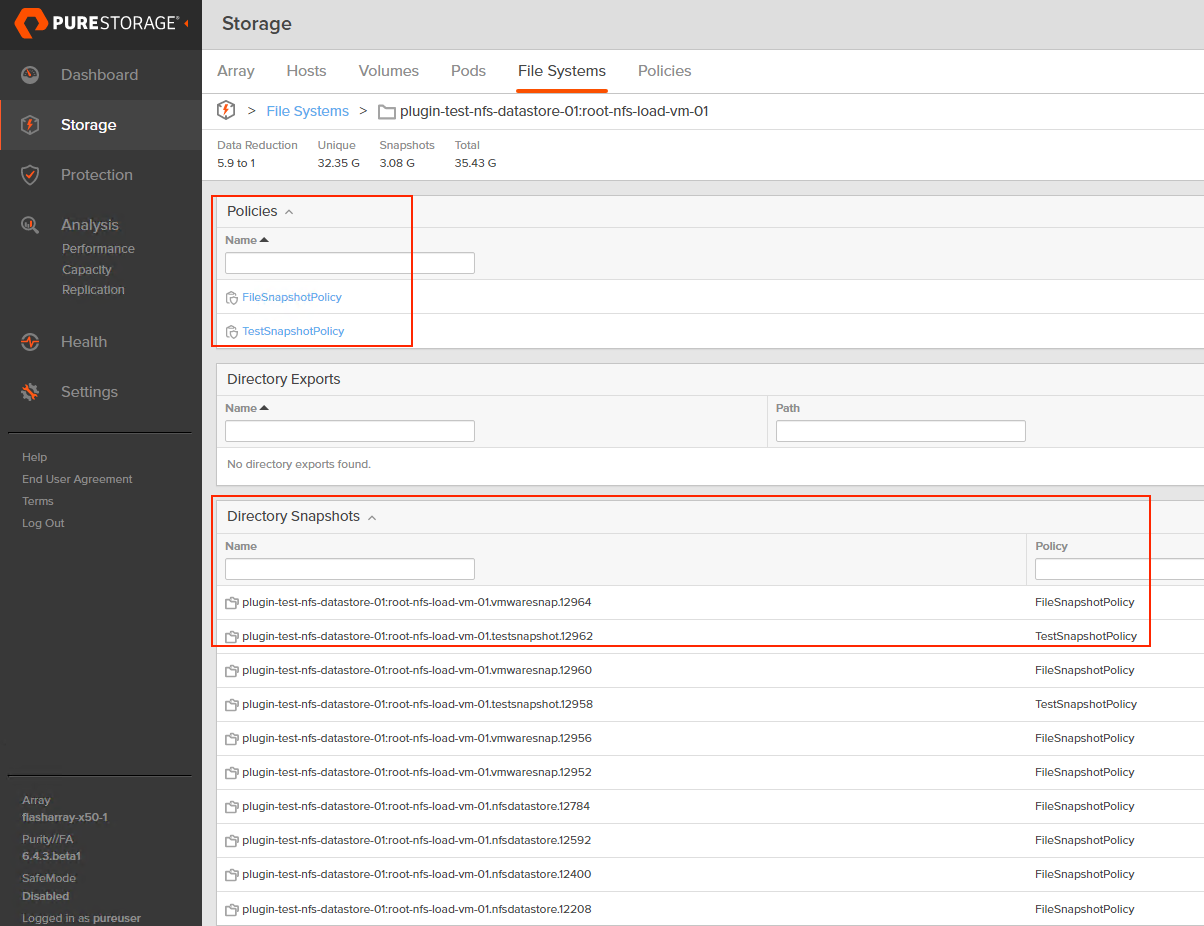
Want to have a special snapshot schedule for a certain group of VMs on a FlashArray-backed NFS datastore? With autodir, you can create snapshot policies and apply them to specific directories, allowing you to get around having to snapshot an entire NFS datastore like it’s a VMFS datastore. You can still snapshot the entire NFS file system if you want! Autodir enables you to have other options.
Your mission critical VMs likely have more complex snapshot retention and frequency requirements than your test VMs. With autodir, you can also apply multiple snapshot policies to the same directory (VM).
That’s sounds great Nelson, but surely autodir isn’t a good option for every NFS datastore on FlashArray. What are the reasons you wouldn’t want to enable autodir?
The main circumstance where autodir doesn’t make sense is if the scale limits of autodir are less than the directory count in your NFS datastore. Those can be found in this KB under “Managed Directories per array“.
If you want to see a demo of how autodir is configured on FlashArray, this video goes over it.
If you want to get detailed written instructions for how to configure autodir on FlashArray, this KB article is a good resource.
Today I want to tell to you about what I use the vSphere plugin for regularly in my lab to hopefully help you get more value out of your existing Pure array and tools. The assumption of this guide is that you already have the vSphere plugin installed (follow this guide if you don’t currently have it installed or would like to upgrade to a more feature-rich remote plugin version). Our vSphere plugin release notes KB covers the differences between versions. If you aren’t sure what version you want, use the latest version.
Why should you care about the vSphere plugin and why would I highlight these workflows for you? Pure’s vSphere plugin can save you a significant amount of time in the configuration/management of your vSphere+FlashArray environment. It can also greatly reduce the barriers to success in your projects by reducing the steps required of the administrator for successful completion of a workflow. Additionally, you might currently be using the vSphere plugin for a couple of workflows but didn’t realize all of the great work our engineers have put into making your life easier.
I am planning to write more blogs on the vSphere plugin and the next one I plan to write is on the highest value features that exist in current vSphere plugin versions.
Create and Manage FlashArray Hosts and Host Group Objects
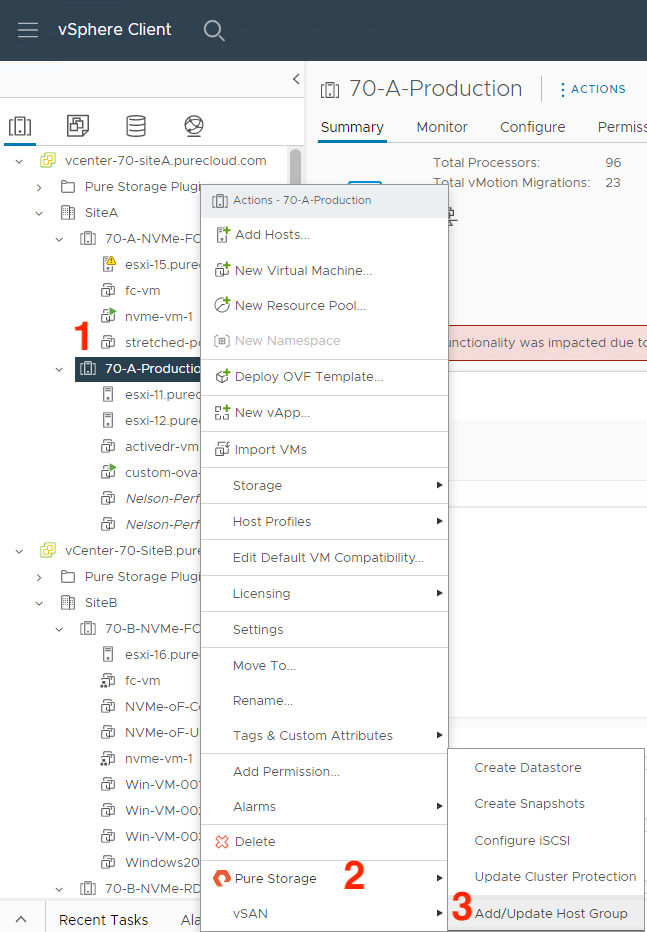
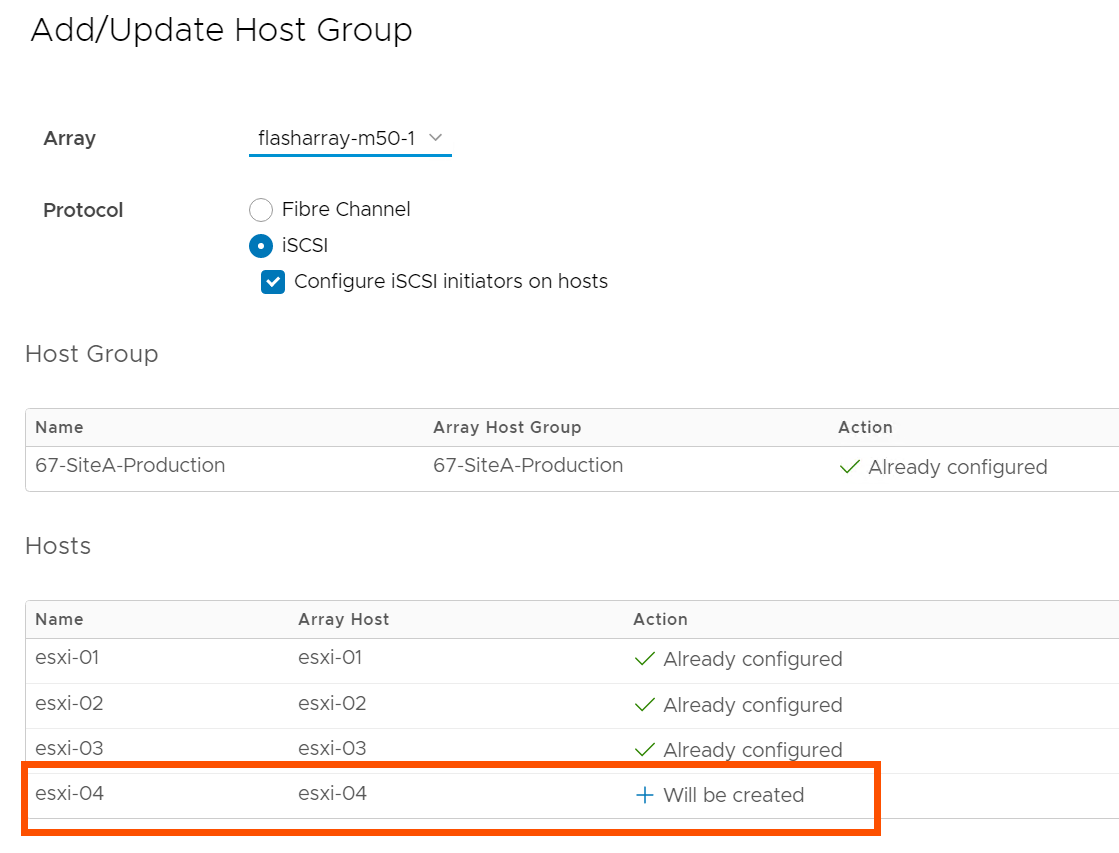
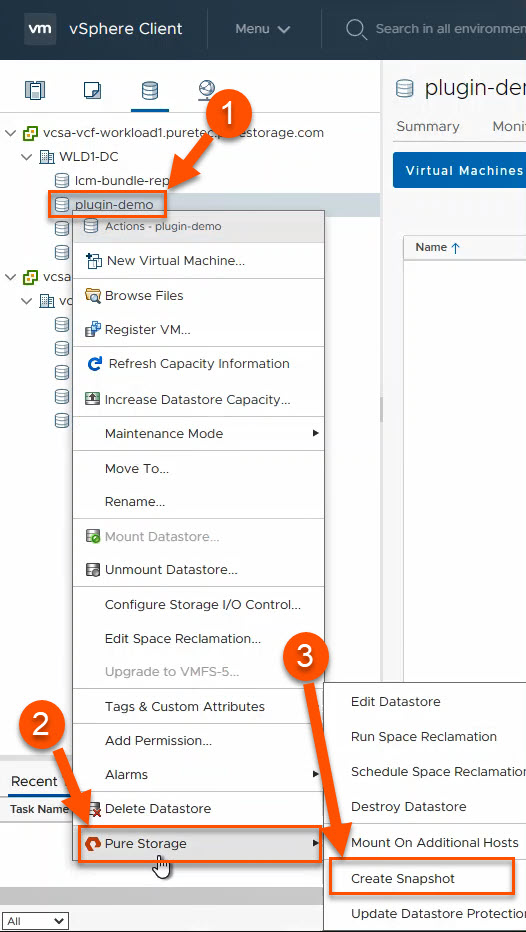
If you’re currently a Pure customer, you have likely managed your host and host group objects directly from the array. Did you know you can also do this from the vSphere plugin without having to copy over WWNs/IPs manually? (1) Right-click on the ESXi cluster you want to create/manage a host or host group object on, (2) hover over Pure Storage, then (3) left-click on Add/Update Host Group.
In this menu, there are currently Fibre Channel and iSCSI protocol configuration options. We are currently exploring options here for NVMe-oF configuration; stay tuned by following this KB. You can also check a box to configure your ESXi hosts for Pure’s best practices with iSCSI, making it so you don’t have to manually configure new iSCSI ESXi hosts.
FlashArray VMFS Datastore and Volume Management(Creation and Deletion)
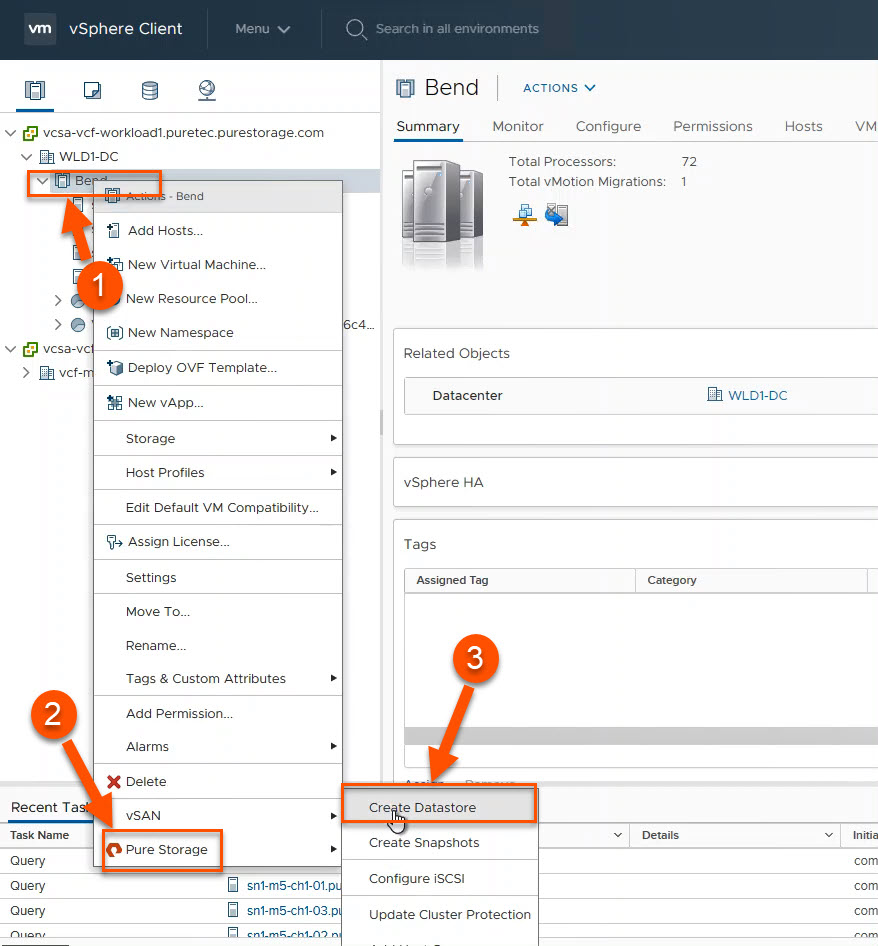
When you use the plugin for datastore creation, the plugin will create the appropriate datastore in vSphere, the volume on the FlashArray, and it will connect the volume to the appropriate host(s) and host group objects on the FlashArray. (1) Right-click on the pertinent cluster or host object in vSphere, (2) hover over Pure Storage and finally (3) left-click on Create Datastore. This will bring up a wizard with a lot of options that I won’t cover here, but the end result will be a datastore that has a FlashArray volume backing it.
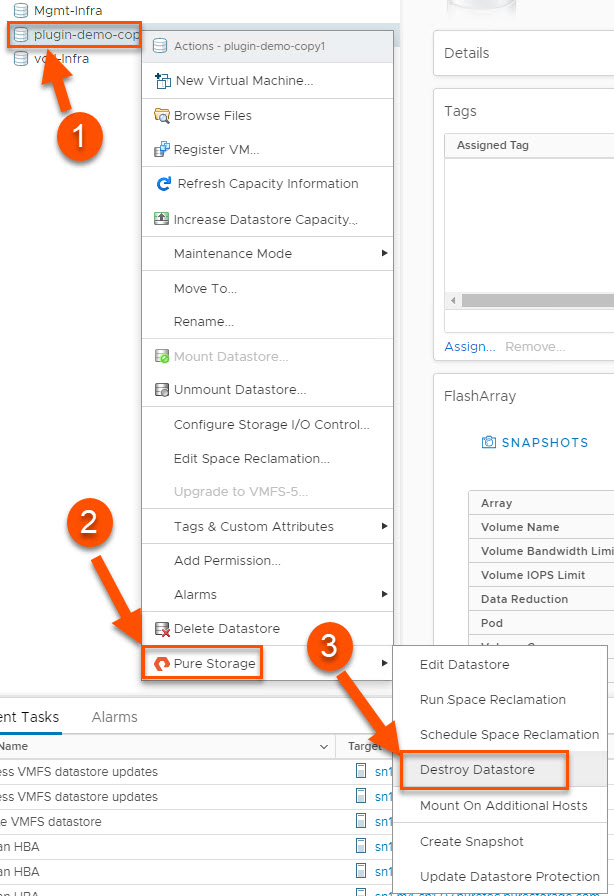
The great thing about deleting a datastore from the plugin is that there are no additional steps required on the array to clean up the objects. This is the most satisfying workflow for me personally because cleanup in a lab can feel like it’s not a good use of time until I’ve got hundreds of objects worth cleaning up. This workflow enables me to quickly clean up every time after I’ve completed testing instead of letting this work pile up.
(1) Right-click the datastore you want to delete, (2) hover over Pure Storage and (3) left-click on Destroy Datastore. After the confirmation prompt, the FlashArray volume backing that datastore will be destroyed and is pending eradication for whatever that value is configured on the FlashArray (default 24 hours, configurable up to 30 days with SafeMode). That’s it!
FlashArray Snapshot Creation
One of the benefits of FlashArray is its portable and lightweight snapshots. The good news is that you can create these directly from vSphere without having to log into the FlashArray. It’s worth mentioning that although the snapshot recovery workflows built into the vSphere plugin (vVols and VMFS) are far more powerful and useful when you really need them, I’m covering what I use regularly and I rarely have to recover from snapshots in my lab. I try to take snapshots every time I make a major change to my environment in case I need to quickly roll-back.
There are two separate workflows for snapshot creation: one for VMFS and one for vVols. The granularity advantage with vVols over VMFS is very clear here- with VMFS, you are taking snapshots of the entire VMFS datastore, no matter how many VMs or disks are attached to those VMs. With vVols, you only have to snapshot the volumes you need to, as granular as a single disk attached to a single VM.
With VMFS, (1) right click on the datastore, (2) hover over Pure Storage and (3) left click on Create Snapshot.
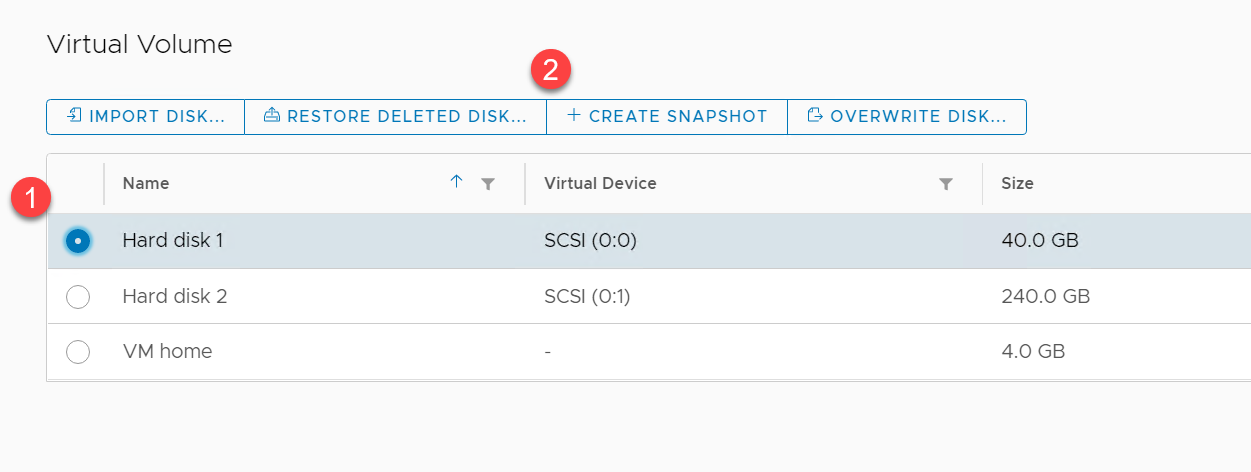
For a vVols backed disk, from the Virtual Machine Configure tab, navigate to the Pure Storage – Virtual Volumes pane, (1) select the disk you would like to snapshot and (2) click Create Snapshot.
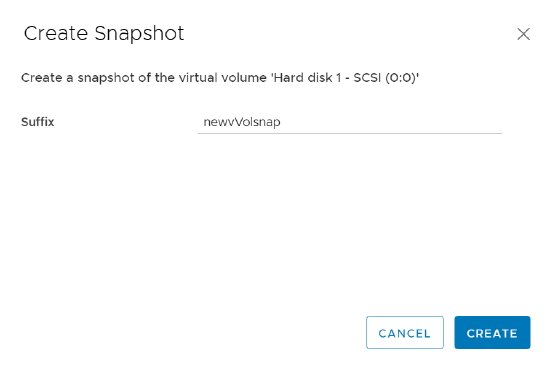
A prompt will pop up to add a suffix to the snapshot if you’d like; click on create and you’ve got your FlashArray snapshot of a vVols backed disk created!
Stay tuned for a blog on the vSphere plugin features you might not know about that, like the above, can save you a significant amount of time and effort.
This is going to be broken up into two parts- first, a live migration where no VMs get powered off during the migration; second, a migration where you temporarily power off VMs attached to the SCSI datastore.
Why would you want to do it one way or another?
Pros of live migration:
No VM downtime
Simpler configuration changes and overlap. Less to go wrong or mess up
Pros of powering off VMs:
The total migration time will be significantly less because no data will have to be moved. Currently VMware doesn’t support XCOPY (even on the same array) for NVMe-oF
We are excited to announce the launch of the latest version of Pure Storage’s remote vSphere plugin, 5.1.0. It includes a number of bug fixes PLUS a highly sought after feature: vVols VM point-in-time (PiT) recovery!
Why am I excited about this feature?
With vVol PiT VM recovery, you can now easily recover an entire VM that was accidentally deleted (and eradicated) or you can restore the state of a VM back to a point in time that you took a snapshot from vCenter directly while using Pure’s vSphere plugin.
The requirements of this are Pure’s vSphere remote plugin 5.1.0 and Purity™ 6.2.6 or higher for PiT revert and for PiT VM undelete with a vVol VM that has had its FlashArray™ volumes eradicated from the FlashArray itself. If you’re undeleting a vVol VM that has not been eradicated yet, that functionality is present for Purity versions 6.1 and lower.
For PiT VM revert, you will also need to make sure that you have snapshots of all of the volumes associated with the vVol VM except swap- at least one data volume and one configuration volume.
For VM undelete before the volumes have been eradicated, you will need a snapshot of the vVol VM’s configuration volume.
For VM undelete after the vVol-backed VM has been eradicated, you’ll need a FlashArray protection group snapshot of all the VM’s data volumes, managed snapshots and configuration volumes.
Rather than rehash what my teammate Alex Carver has put a lot of work into, I’m just going to link to the KB and videos he created:
Download the new plugin (part of Pure’s OVA), read the release notes and test out vVol PiT recovery today! Like a lot of things, it’s better to have some understanding of what’s happening and why before needing something that might be part of your recovery process. Please note that you can also upgrade in-place from 5.0.0 to 5.1.0 (and future remote plugin releases) by following this guide.
This will be a short blog, partially because my teammate Alex Carver already wrote a great blog that covers one workaround for this button not working that uses vCenter’s MOB.
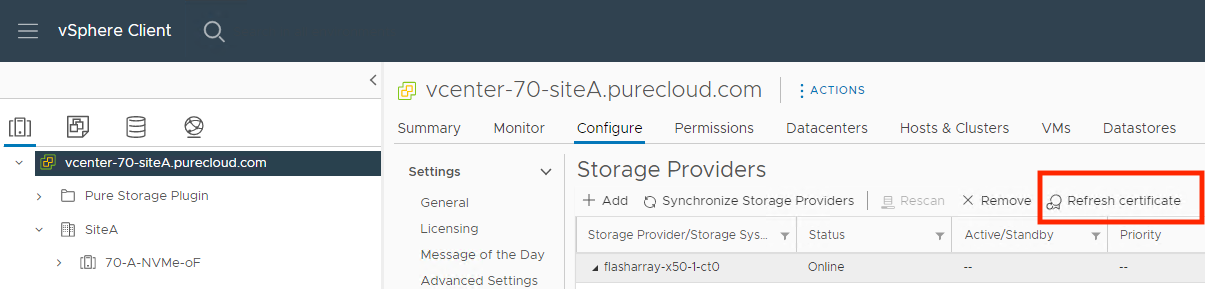
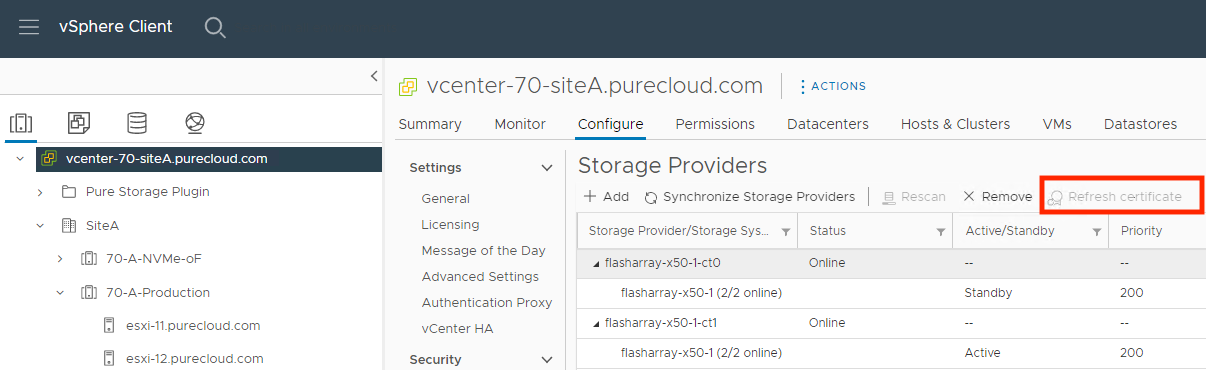
If you have been using self-signed certificates in your vVols environment since vCenter 6.7 and updated to vCenter 7.0, you might have noticed something frustrating when trying to refresh those certificates manually: the button was greyed out! If you were like me, you were probably wondering why this useful functionality was removed and thought maybe it was for security reasons; your concerns might have been validated when searching VMware’s KB system and finding this KB that read like it was functionality that was removed on purpose (recently updated to reflect the current situation better).
Turns out my guess was wrong and that KB was a little misleading. VMware has brought this button’s functionality back in vCenter 7.0U3d and higher. You might say to yourself “that’s great Nelson, but I don’t upgrade my production vCenter whenever a new vCenter version comes out”. If you want a simpler workflow than re-creating the storage providers before you upgrade to newer versions of vCenter when the certificates expire eventually, Alex Carver has the method for you which uses vCenter’s MOB to refresh the storage providers without re-creating them.
I normally do not create a blog post about updating the guide, but this one was a major overhaul and I think is worth mentioning. Furthermore, there are a few documents I have written and published that I want to mention.
This is part 1 of this 7 part series. Questions around managing VMFS snapshots have been cropping up a lot lately and I realized I didn’t have a lot of specific Pure Storage and VMware resignaturing information out there. Especially around scripting all of this and the various options to do this. So I put a long series out here about how to do all of this. Let’s start with what an unresolved VMFS is and how to mount it.
EMC offers a variety of tools to manage/enhance your virtual or physical environments–some free, some licensed. In most cases when you think of EMC tools for VMware one conjures up the free Virtual Storage Integrator which is more commonly referred to as VSI.
VSI is a great tool and continues to be improved through each version and allows you to provision storage, manage pathing, configure SRM etc. The one thing it does not have is a way to automate these tasks through an API or CLI. This is where another product comes in–one that many do not associate with VMware. The EMC Storage Integrator (ESI) is a lot of times seen as the Microsoft version of VSI–but that isn’t really true at all. While it might have started out that way and does indeed support Hyper-V and has a ton of Microsoft-specific features it is really the heterogeneous storage integrator. Importantly it has a very handy and powerful feature–PowerShell cmdlets.