
This post I will talk about using PowerCLI to run a test failover for VVol-based virtual machines. One of the many nice things about VVols is that in the VASA 3.0 API this process is largely automated for you. The SRM-like workflow of a test failover is included–so the amount of storage-related PowerShell you have to manually write is fairly minimal.
- PowerCLI and VVols Part I: Assigning a SPBM Policy
- PowerCLI and VVols Part II: Finding VVol UUIDs
- PowerCLI and VVols Part III: Getting VVol UUIDs from the FlashArray
- PowerCLI and VVols Part IV: Correlating a Windows NTFS to a VMDK
- PowerCLI and VVols Part V: Array Snapshots and VVols
- PowerCLI and VVols Part VI: Running a Test Failover
- PowerCLI and VVols Part VII: Synchronizing a Replication Group
- PowerCLI and VVols Part VIII: Running a Planned Migration
With VVols, you don’t really failover a single VM, you fail over a replication group. While it is certainly possible to just recover a single VM from that failover etc, I will, for this blog post, show failing over the entire group.
Setup
In this environment, I have the following configured:
- My source vCenter called ac-vcenter-1.purecloud.com. This has access to my source FlashArray and its VASA providers.
- My target vCenter called ac-vcenter-2.purecloud.com. This has access to my target FlashArray and its VASA providers.
My PowerCLI version is 11.1.0. Make sure you are at least running this release–there are important updates that make this process simpler. Older revisions require a few more steps.
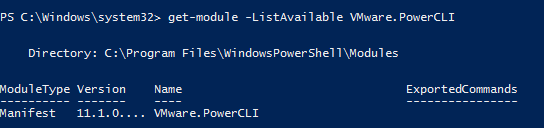
A couple things to remember about this fact:
- The “SPBM” cmdlets do not shut down VMs on the source side. Manipulation of VMs (other than making a copy accessible on the target site) is out of the scope of the VVol failover cmdlets.
- The “SPBM” cmdlets do not power-on or register the VMs on the target side. These “SPBM” cmdlets are solely about getting the VMs available on site B. Though I will give examples on doing this part.
Requirements:
A few pre-requisites here:
- Make sure the VVol datastore is mounted somewhere in the recovery site. You also of course need the source mounted somewhere too, but I figure you’ll have that done. No datastore = no VMs.
- Register VASA from both arrays in their correct locations. More on that in the next section.
- Configure one or more VMs on the source VVol datastore. Assign them a SPBM storage policy that includes FlashArray replication. If you manually assign them to replication groups on the array instead of using storage policies, this process will not work. Pro-tip: assigning features like replication via SPBM not only tells the VMware admin how they are configured, but also tells vSphere how they are configured.
Getting Started
First things first, connect to both of your vCenters.
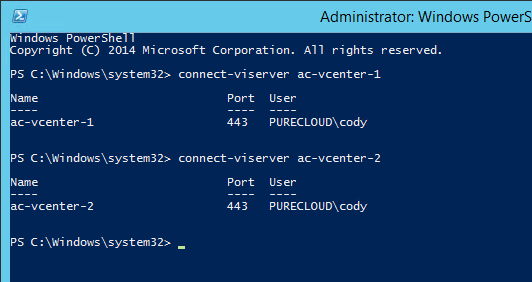
What if I am failing over my VMs inside of a single vCenter? Well that’s fine of course–just connect to just the one vCenter in that case.
The key is: make sure that your target and source VASA providers are registered to the vCenters that you need to use them with.
If you have two vCenters, make sure that your target VASA providers are registered to the target vCenter and your source VASA providers are registered to your source vCenter.
If you are using one vCenter make sure that both your target and source VASA providers are registered with that vCenter.
Get Replication Group
The next step is to identify your TARGET replication group that needs to be failed over. VVols fails VMs over in the granularity of a replication group–and this is what is passed to VASA to tell the array to bring up the appropriate storage. There are source replication groups and target replication groups.
On the FlashArray, replication groups are 1:1 mapped to what we call a protection group. A protection group is a consistency group with (either or both) a local snapshot policy and/or a replication policy. If the protection group does not have a replication policy, it will NOT have a target protection group.
You can simply list the replication groups, or you can use some kind of source object to get the relevant group (or groups).
Note–if you DO NOT see the source group you are looking for, you likely are connected to only the target vCenter and NOT the source vCenter. Make sure you are connected to the source vCenter too if you are failing VMs between vCenters.
One option is if you have a VM that is in a replication group, you could run something like this:
Get-SpbmReplicationgroup -vm <vm name>
That will return the replication group that the VM belongs to.
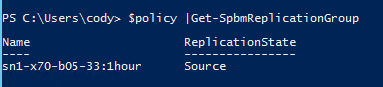
Or you can get it from a storage policy. Find your policy:

Then pass that into get-spbmreplication group:
Or you could just run get-spbmreplicationgroup without any inputs:
Get-SpbmReplicationgroup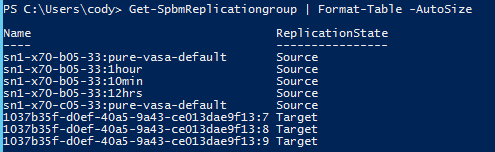
And choose your source group from those. The choice is yours–it doesn’t really matter what you choose as your journey to get the replication group, just that you identify the one you want.
Now that we have the source group…
FlashArray source replication groups are named by the array name, followed by a colon, followed by the protection group name. Target group names are named by a UUID and replication group number. To run a test failover, you need the target group, so how do we get the corresponding target group from the source group?
So let’s say (regardless to which method above I used) I have identified the group “sn1-x70-b05-33:1hour” as the source I want to run a test failover from. The simplest way to get to target group is by using the get-spbmreplication pair cmdlet. I will store my selected replication group in a new object that I will call $repGroup:
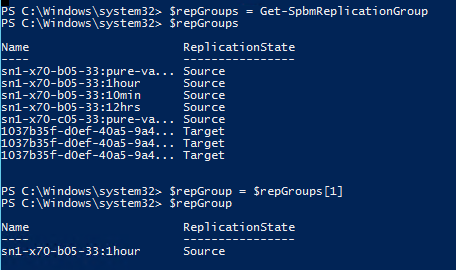
I can then pass that into get-spbmreplicationpair to get the replication group pair. Pass that $repGroup into the -source parameter.

I can now store the target replication group in a new object called $targetGroup:
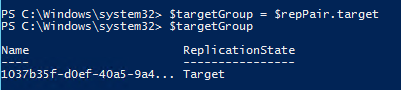
At this point I can run a test failover–nothing else is needed. But there are some option parameters. So let’s take a look.
OPTIONAL: Point-in-Time Recovery
The next step is optional. Do you want to failover to a specific point-in-time? If you do, you can query the available point-in-time’s available. Otherwise, skip this step.
$<target replication group> | Get-SpbmPointInTimeReplica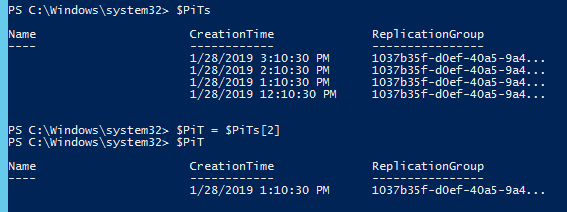
Above, I store all of my available point-in-times in $PiTs then index to the one I want and store it in $PiT. So during the test failover command, I can specify $PiT to make it failover to that point-in-time.
Run Test Failover
The next step is to run the test failover with the command start-spbmreplicationtestfailover.
If you want it to use the latest point-in-time available just run:
Start-SpbmReplicationTestFailover -ReplicationGroup $targetGroupIf you want to specify a point-in-time in the past, then do so:
Start-SpbmReplicationTestFailover -ReplicationGroup <group> -PointInTimeReplica <point in time>So go ahead and run it. I highly recommend storing the response in an object–the operation will return the VM paths to you, so you can then register and power them on.

So what actually happens in here? Well a few things:
- The target FlashArray does a “purepgroup copy” operation. This takes a certain pgroup snapshot (which is a consistent snapshot of all of the volumes in that pgroup at that time) and creates a new local pgroup with all of the new volumes created from that pgroup copy.
- The new pgroup is enabled to replicate back to the original FlashArray, this will be cleaned up during the test failover stop. This is created to allow for some advanced post-test operations.
- It then creates new volume groups, one for each VM created in the test and adds their corresponding volumes to it.
- Then associates the new VMs to the target VVol datastore.
The last step is from VMware. Updating the files in the VVol datastore. This takes the bulk of the time.

Once complete go ahead and register and power-on the VMs. To register, a simple loop like below will do it:
$registeredVms = @()
foreach ($testVm in $vms)
{
$registeredVms += New-VM -VMFilePath $testVm -ResourcePool <resource pool>
}This will register all of your VMs. You will likely want to change the “new-vm” line to register as appropriate to your environment (what cluster or host, or resource pool, or folder etc.
Now make any changes if necessary to your VMs. Change the networking etc.
Go ahead and power them on!
$registeredVms |Start-VMDone!
Clean Up
Once you are done, go ahead and power-off the VMs and unregister them. You can either just unregister them, or you can delete them from disk. It doesn’t really matter–though my recommendation is to just delete them.
The last step is then stop the test failover–this allows the array to clean itself up.
Run:
stop-SpbmReplicationTestFailover -ReplicationGroup <target group>This will clean up any remnants of the test failover (volumes, volume groups, protection groups) on the array.

Failures in Get-SpbmReplicationPair
Sometimes you will get failures when using the get-spbmreplicationpair. This usually means a few things.
First you didn’t specify the source replication group. This means it will query for everything. Basically means you ran get-spbmreplicationpair without any parameters.
Or/also, you are not connected to all of your required vCenters. PowerCLI queries all available VASA providers from all vCenters and then matches the appropriate pairs. If one half a relationship is not reported by anyone, PowerCLI will report an error for that pair. If you didnt connect to a vCenter that exclusively owns your target VASA provider, you will see some failures. Or maybe you don’t care about some of the pairs, which means those errors don’t matter. The pairs you need are returned, but it will still report errors for the others, so to keep things clean, be specific with your queries. Include the source group in the get-spbmreplicationpair cmdlet.
Get-SpbmReplicationPair : 1/28/2019 4:28:36 PM Get-SpbmReplicationPair The target replication group with id
‘e671ca7e-5a3d-3ca3-8258-cf3448c334a6/b70bff9d-ce6b-4ca3-af13-79c3f93e5ac2:1’ for source replication group id
‘e671ca7e-5a3d-3ca3-8258-cf3448c334a6/b70bff9d-ce6b-4ca3-af13-79c3f93e5ac2:1’ could not be found. Please verify that
the vSphere server for peer replication group is connected.
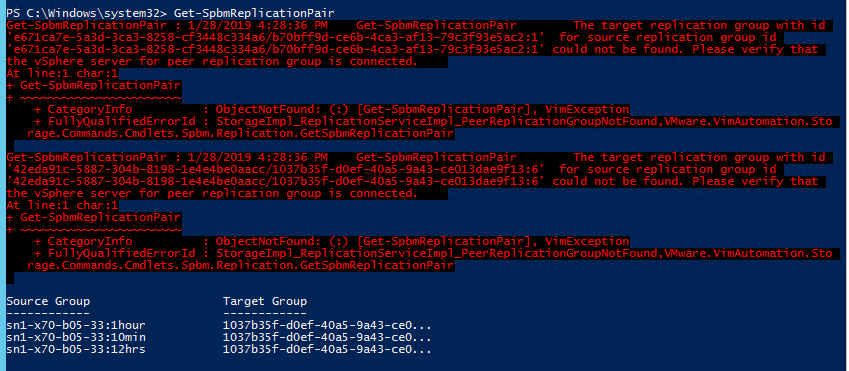
Above I did a query for all replication pairs. In my environment, I have two arrays. Both of which have a protection group that does not have replication enabled–this means there is no target group anywhere. So for those an error will always be returned in this cmdlet. This is why it is good to be specific in this particular query.
Failures in Get-SpbmReplicationGroup
A common place where get-spbmreplicationgroups can fail (or partially fail) is if the VVol datastore has not been mounted in the recovery site. Without this object, VMware has no reference on what to query for available replication groups. You will see an error like below:
Get-SpbmReplicationGroup : 1/28/2019 4:33:51 PM Get-SpbmReplicationGroup SMS runtime fault on server
‘/VIServer=purecloud\cody@ac-vcenter-2:443/’: Unknown server error. See the event log for details.
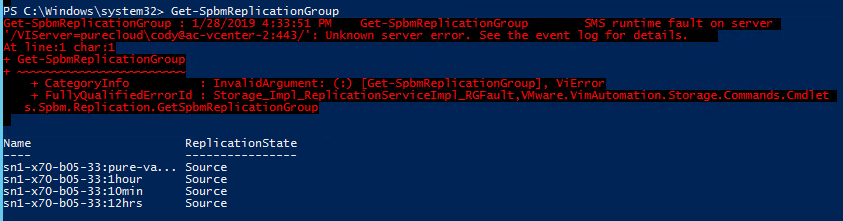
In this case, ensure the VVol datastore is properly mounted where you plan to recover.
Hey Cody,
I try to simulate a VVOL environment and follow your script. But always got some error when I use “Get-SpbmReplicationGroup”. Of course, I can’t run test failover, still can’t get $testvms.
I am not sure what I lost…..
PS C:\Users\Administrator> $SourceGroup = $VM | Get-SpbmReplicationGroup
Get-SpbmReplicationGroup : 1/17/2019 14:16:29 Get-SpbmReplicationGroup Error doing ‘FetchingReplicationGroup’ on replication group
‘2d669caf-5095-3a8c-abcc-2e445568e3c3/6729c989-befb-49aa-b0c8-b8dc11e471e9:16’. Reason:
Error 1: Replication group not found.
位於 線路:1 字元:22
+ $SourceGroup = $VM | Get-SpbmReplicationGroup
+ ~~~~~~~~~~~~~~~~~~~~~~~~
+ CategoryInfo : InvalidData: (:) [Get-SpbmReplicationGroup],VimException
+ FullyQualifiedErrorId : StorageImpl_ReplicationServiceImpl_ErrorInvokingOperationOnReplicationGroup,VMware.VimAutomation.Storage.Commands.Cmdlets.Sp
bm.Replication.GetSpbmReplicationGroup
Get-SpbmReplicationGroup : 1/17/2019 14:16:29 Get-SpbmReplicationGroup Error doing ‘FetchingReplicationGroup’ on replication group
‘f0347df4-4a65-3b06-bdf2-9b044022f633/04a5faa8-3402-43e5-83fb-d541cc6ecf7b:2’. Reason:
Error 1: Replication group not found.
位於 線路:1 字元:22
+ $SourceGroup = $VM | Get-SpbmReplicationGroup
+ ~~~~~~~~~~~~~~~~~~~~~~~~
+ CategoryInfo : InvalidData: (:) [Get-SpbmReplicationGroup],VimException
+ FullyQualifiedErrorId : StorageImpl_ReplicationServiceImpl_ErrorInvokingOperationOnReplicationGroup,VMware.VimAutomation.Storage.Commands.Cmdlets.Sp
bm.Replication.GetSpbmReplicationGroup
Get-SpbmReplicationGroup : 1/17/2019 14:16:29 Get-SpbmReplicationGroup Error doing ‘FetchingReplicationGroup’ on replication group
‘f0347df4-4a65-3b06-bdf2-9b044022f633/04a5faa8-3402-43e5-83fb-d541cc6ecf7b:3’. Reason:
Error 1: Replication group not found.
位於 線路:1 字元:22
+ $SourceGroup = $VM | Get-SpbmReplicationGroup
+ ~~~~~~~~~~~~~~~~~~~~~~~~
+ CategoryInfo : InvalidData: (:) [Get-SpbmReplicationGroup],VimException
+ FullyQualifiedErrorId : StorageImpl_ReplicationServiceImpl_ErrorInvokingOperationOnReplicationGroup,VMware.VimAutomation.Storage.Commands.Cmdlets.Sp
bm.Replication.GetSpbmReplicationGroup
PS C:\Users\Administrator> $TestVms = Start-SpbmReplicationTestFailover -ReplicationGroup $TargetGroup -SourceVvolIdMap $SourceVVolMap
警告: 參數 ‘SourceVvolIdMap’ 已過時。This parameter is no longer required and will be removed in future release.
Start-SpbmReplicationTestFailover : 1/17/2019 14:55:20 Start-SpbmReplicationTestFailover SMS runtime fault on server
‘/VIServer=vsphere.local\administrator@172.16.115.2:443/’: A replication fault was reported by the VASA provider ‘FA-405-ct0’.
位於 線路:1 字元:12
+ $TestVms = Start-SpbmReplicationTestFailover -ReplicationGroup $Targe …
+ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+ CategoryInfo : InvalidOperation: (:) [Start-SpbmReplicationTestFailover],ViError
+ FullyQualifiedErrorId : Storage_Impl_ReplicationServiceImpl_ErrorStartingTestFailover,VMware.VimAutomation.Storage.Commands.Cmdlets.Spbm.Replication
.StartSpbmReplicationTestFailover
PS C:\Users\Administrator> $TestVms
PS C:\Users\Administrator>
Open a Pure support ticket on this, I believe this is a known issue which has been fixed
Thanks, I already open a ticket [00519635] for that.
How can we we perform a “failover” in the event of a full disaster where the source datacenter is gone (including the source pure array w/ the vvols and the source vcenter appliance) using the replicated volumes on the target pure array?
I assume the Start-SpbmReplicationFailover method will not work in that case as the source vcenter is not reachable and we would have to construct volume groups and then some how add them to the target vvol ‘datastore’. Is there a sample of that in powercli somewhere or can you provide some pointers? Guessing we would have to save/cache some of the data from the original datacenter (vvol uuids + ?) and then use the APIs?
Thanks,
Ed
Good question! Nope it is actually simpler than that. The target site has all of the information you need. Im working on a post now. Will have it done this week
Do you have a link to your post about what Ed asked above?
Could you please help us with the sample commands to test the disaster recovery scenario?
Yeah I am working on a powercli update that will help with all of it. Almost done. I will be rewriting this series for it. Though the short answer is that it is basically just using the cmdlets which only talk to the target vcenter
Hello Cody,
Did you have some news about the powercli update you’ve talked, which will allow a failover (and test failover?) with cmds only send to target vcenter?
it will be a great argument for vvol transition @my company.
thanks
You can do this today, the process does not require you to send anything to the source to do a failover, but I need to write that process out. I was writing a module to help with this, but I found a PowerCLI bug in storage capabilities configuration (unrelated to replication, but enough to stop my project) that was just fixed in the latest PowerCLI release. So I am hoping to restart that work soon.
Thanks for another good VVol post Cody!
I don’t use Pure, sorry about that, but I seem to get stuck with FailedOver replication groups which don’t want to clean up.
Do you have any idea why maybe? The VM has been unregistered from vCenter.
PS C:\FailoverDB> Get-SpbmReplicationGroup | ft -AutoSize
Name ReplicationState
—- —————-
…
4036ad66-d4f5-42ce-a065-a9820a77db05 FailedOver
588c335e-5704-4626-a149-c187898f5498 FailedOver
a74090fc-68e8-458e-896f-3a09dee59b6b FailedOver
PS C:\FailoverDB> Stop-SpbmReplicationTestFailover -ReplicationGroup 4036ad66-d4f5-42ce-a065-a9820a77db05
Stop-SpbmReplicationTestFailover : 13.02.2019 15.02.39 Stop-SpbmReplicationTestFailover Error doing ‘TestFailoverReplicationGroupStop’ on replication group ‘00000001-1111-000
0-7777-000000107206/4036ad66-d4f5-42ce-a065-a9820a77db05’. Reason:
Error 1: Replication fault has occured.
At line:1 char:1
+ Stop-SpbmReplicationTestFailover -ReplicationGroup 4036ad66-d4f5-42ce …
+ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+ CategoryInfo : InvalidData: (:) [Stop-SpbmReplicationTestFailover], VimException
+ FullyQualifiedErrorId : StorageImpl_ReplicationServiceImpl_ErrorInvokingOperationOnReplicationGroup,VMware.VimAutomation.Storage.Commands.Cmdlets.Spbm.Replication.StopSpbmReplicationTestFailover
You’re welcome! Have you looked at the vmware-sps log in vCenter? That will likely give you better insight into the issue. Unfortunately there is a lot of vendor specific behavior behind some of these commands it is hard to say. The VASA provider might have delivered a better error to the vmware-sps log though. It is possible that if the VMs are still running or connected that test failover stop will fail. So might be worth checking for any lingering connections, or maybe the replication group has non-VVol storage in it. I have heard some vendors have that interop issue. But I am just guessing at this point.
Thanks Cody, turns out it was an user error by me.
I had run the normal failover, not the testfailover. I cleaned it up by reversing the replication, because as far as I can see there is no other command to delete/clean up those mistakes?
Ah okay. Easy to do–they are named so similarly 🙁 Yeah that would be the right option–will get things as they need to be and then you can manually cleanup what it created.
Hello Cody, thank you for this very helpful post !
Just for information, I got errors with PowerCli11.0.0.10380590.
It’s OK now with 11.2.0.
You’re welcome! Ah yes I should have said 11.1.0 or later is required for the above. Updated it to that. Sorry bout that!
Great Scripts – just tested them with a new vVols customer – worked flawlessly – we did bring up 50VMs in one go.
Great to hear!
Re: I was writing a module to help with this, but I found a PowerCLI bug in storage capabilities configuration (unrelated to replication, but enough to stop my project) that was just fixed in the latest PowerCLI release. So I am hoping to restart that work soon.
Whatever became of this?