
In the previous post in this series I explored how to run a VVol-based test failover of a virtual machine. Now I will walk through running an actual failover.
- PowerCLI and VVols Part I: Assigning a SPBM Policy
- PowerCLI and VVols Part II: Finding VVol UUIDs
- PowerCLI and VVols Part III: Getting VVol UUIDs from the FlashArray
- PowerCLI and VVols Part IV: Correlating a Windows NTFS to a VMDK
- PowerCLI and VVols Part V: Array Snapshots and VVols
- PowerCLI and VVols Part VI: Running a Test Failover
- PowerCLI and VVols Part VII: Synchronizing a Replication Group
- PowerCLI and VVols Part VIII: Running a Planned Migration
There are two types of failovers; a planned migration (everything is up an running) and a disaster recovery failover (part or all of the original site is down).
For this post, I will start with running a planned migration.
Setup
In this environment, I have the following configured:
- My source vCenter called ac-vcenter-1.purecloud.com. This has access to my source FlashArray and its VASA providers.
- My target vCenter called ac-vcenter-2.purecloud.com. This has access to my target FlashArray and its VASA providers.
My PowerCLI version is 11. Make sure you are at least running this release–there are important updates that make this process simpler. Older revisions require a few more steps.
A couple things to remember about this fact:
- The “SPBM” cmdlets do not shut down VMs on the source side. Manipulation of VMs (other than making a copy accessible on the target site) is out of the scope of the VVol failover cmdlets.
- The “SPBM” cmdlets do not power-on or register the VMs on the target side. These “SPBM” cmdlets are solely about getting the VMs available on site B. Though I will give examples on doing this part.
Requirements:
A few pre-requisites here:
- Make sure the VVol datastore is mounted somewhere in the recovery site. You also of course need the source mounted somewhere too, but I figure you’ll have that done. No datastore = no VMs.
- Register VASA from both arrays in at least their respective vCenters.
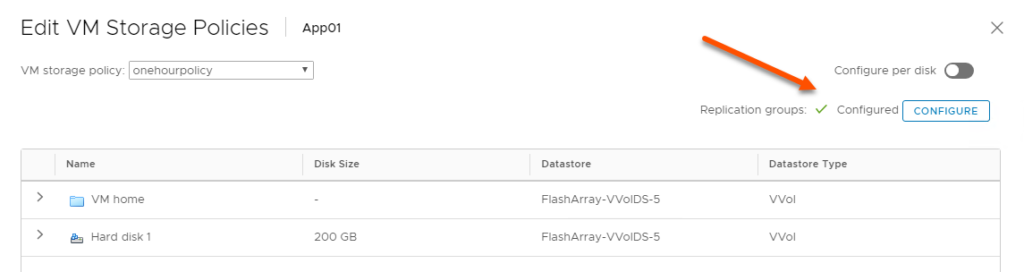
- Configure one or more VMs on the source VVol datastore. Assign them a SPBM storage policy that includes FlashArray replication. If you manually assign them to replication groups on the array instead of using storage policies, this process will not work. Pro-tip: assigning features like replication via SPBM not only tells the VMware admin how they are configured, but also tells vSphere how they are configured.
Getting Started
First things first, connect to both of your vCenters.
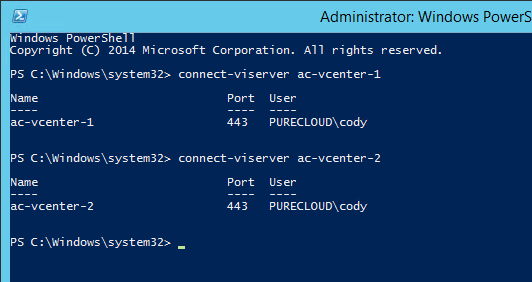
What if I am failing over my VMs inside of a single vCenter? Well that’s fine of course–just connect to just the one vCenter in that case.
The key is: make sure that your target and source VASA providers are registered to the vCenters that you need to use them with.
If you have two vCenters, make sure that your target VASA providers are registered to the target vCenter and your source VASA providers are registered to your source vCenter.
If you are using one vCenter make sure that both your target and source VASA providers are registered with that vCenter.
Get Replication Group
The next step is to identify your TARGET replication group that needs to be failed over. VVols fails VMs over in the granularity of a replication group–and this is what is passed to VASA to tell the array to bring up the appropriate storage. There are source replication groups and target replication groups.
On the FlashArray, replication groups are 1:1 mapped to what we call a protection group. A protection group is a consistency group with (either or both) a local snapshot policy and/or a replication policy. If the protection group does not have a replication policy, it will NOT have a target protection group.
You can simply list the replication groups, or you can use some kind of source object to get the relevant group (or groups).
Note–if you DO NOT see the source group you are looking for, you likely are connected to only the target vCenter and NOT the source vCenter. Make sure you are connected to the source vCenter too if you are failing VMs between vCenters.
One option is if you have a VM that is part of that replication group, you could run something like this:
Get-SpbmReplicationgroup -vm <vm name>
That will return the replication group that the VM belongs to.
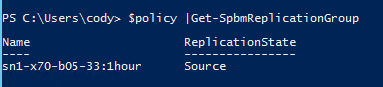
Or you can get it from a storage policy. Find your policy:

Then pass that into get-spbmreplication group:
Or you could just run get-spbmreplicationgroup without any inputs:
Get-SpbmReplicationgroup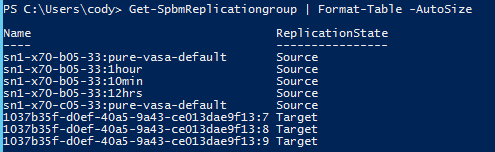
And choose your source group from those. The choice is yours–it doesn’t really matter what you choose as your journey to get the replication group, just that you identify the one you want.
Now that we have the source group…
FlashArray source replication groups are named by the array name, followed by a colon, followed by the protection group name. Target group names are named by a UUID and replication group number. To run a test failover, you need the target group, so how do we get the corresponding target group from the source group?
So let’s say (regardless to which method above I used) I have identified the group “sn1-x70-b05-33:1hour” as the source I want to run a test failover from. The simplest way to get to target group is by using the get-spbmreplication pair cmdlet. I will store my selected replication group in a new object that I will call $repGroup:
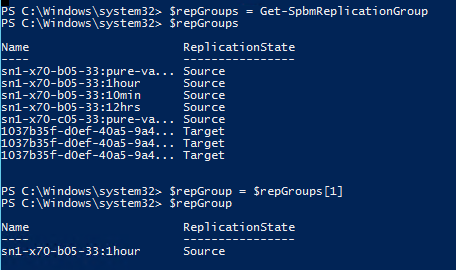
I can then pass that into get-spbmreplicationpair to get the replication group pair. Pass that $repGroup into the -source parameter.

I can now store the target replication group in a new object called $targetGroup:
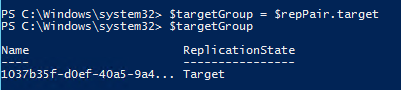
At this point I can run a test failover–nothing else is needed. But there are some option parameters. So let’s take a look.
OPTIONAL: Point-in-Time Recovery
The next step is optional. Do you want to failover to a specific point-in-time? If you do, you can query the available point-in-time’s available. Otherwise, skip this step.
$<target replication group> | Get-SpbmPointInTimeReplica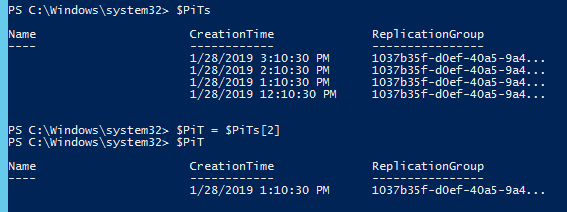
Above, I store all of my available point-in-times in $PiTs then index to the one I want and store it in $PiT. So during the test failover command, I can specify $PiT to make it failover to that point-in-time.
Before you Failover
The next step is to shut your VMs down. Some Q&As here:
Q: Do I have to shut my source VMs down?
A: Well, no, but I presume you would want to. IP conflict, application conflicts, etc. I highly highly recommend shutting them down first. If you aren’t shutting them down, this isn’t really a failover. Smells like a test failover and in that case you should be following that process.
Q: Do I have to unregister my source VMs?
A: No. Though having them registered but powered-off runs the risk that someone might turn them back on. But unregistering them is not the option I would go with, instead I recommend just deleting them. Why? Well if you just unregister them, it is possible you could forget them there and there would be some stranded VMs on the FlashArray that take up space and volume count.
Q: Do I have to delete my source VMs?
A: Also, no. But I do recommend it. Even when you delete them, you can restore them for up to 24 hours. And since you are failing over, they will be brought up on the other side anyways. One option though is the shut them down, do the failover, then once successful, then delete them from the source side.
Q: Should I, and if so–how do I, synchronize my VMs before failover?
A: Well however you want, via our GUI, wait for a replication interval to happen naturally, or use tools like PowerCLI. See more information about that here: https://www.codyhosterman.com/2019/02/powercli-and-vvols-part-vii-synchronizing-a-replication-group/. In the end, make sure that things are synchronized before a failover. This will make sure things are recovered just as they were then shut down.
Running the Failover
The last step is to run the failover. Nothing too exciting here. Our friend start-spbmreplicationgroupfailover.
$vms = start-spbmreplicationfailover -replicationgroup <target group>
Not much is required here. You can pass in your point-in-time if you want, otherwise it will just use the last full point-in-time available on the array. You need to either add confirm, or manually confirm during the operation. You can also run it asynchronously if you want with the -runasync tag.
The bulk of the failover time will be VMware updating the VVol datastore pointer files in the various config VVols.

When the operation completes it will then return you the VMX path files which you can register.
$registeredVms = @()
foreach ($testVm in $vms)
{
$registeredVms += New-VM -VMFilePath $testVm -ResourcePool <resource pool name>
}
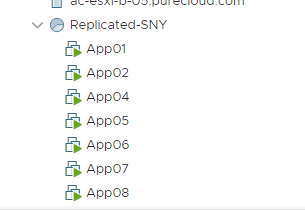
I stored my vmx file paths in the object $vms so the above few lines will register them to a resource pool called Replicated-SNY (in my case). Though if you want to add them a certain folder or pool adjust as necessary. This will also be the time to change VM networks etc as required in your environment.
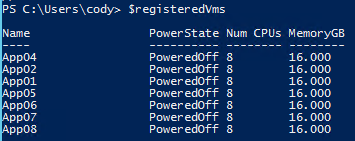
Then power them on. I stored the resulting VMs in my registration process in a variable called $registeredVms. You might need to answer boot up questions (was this copied/moved) which you can answer with the get-vmquestion cmdlet.
foreach ($registeredVm in $registeredVms)
{
$registeredVm | Get-VMQuestion |Set-VMQuestion –DefaultOption -Confirm:$false
}
Reverse Replication
So now that we are failed over, you probably want to re-protect your VMs back to the original site. You can of course protect them to any where you want, but here I will walk through what I believe to be the most common option, which is replicating them back to site A, the site you failed over from.
So, what happens during a failover? Well we actually automatically reprotect during the failover. When you run the failover operation, we create a new protection group with the same replication configuration but replicating back to original array. So on the target side, you will see all of your VVol volumes in that protection group:
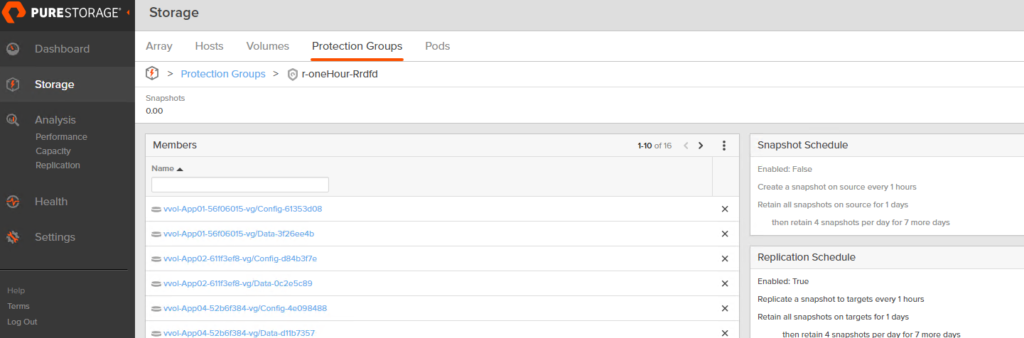
The state of the target group is also “failedOver”
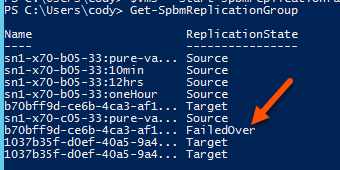
So what does Start-SpbmReplicationReverse actually do? Really just one two things in our (Pure) case. First off, when reverse is run we change the state of that target group back to target.
Start-SpbmReplicationReverse -ReplicationGroup <target group>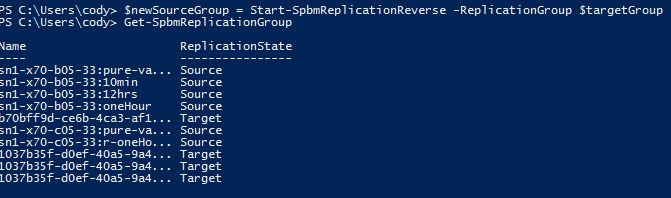
We then return the protection group that we created during the failover as the new source group
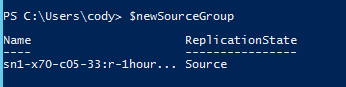
Reprotect
So the replication is reversed and the VMs are protected back, but VMware is not “aware” of it. You need to assign a storage policy.
On my recovery vCenter I have a policy called 1hour that requires the VMs in it be replicated back to my site A array every hour (amongst some other requirements).
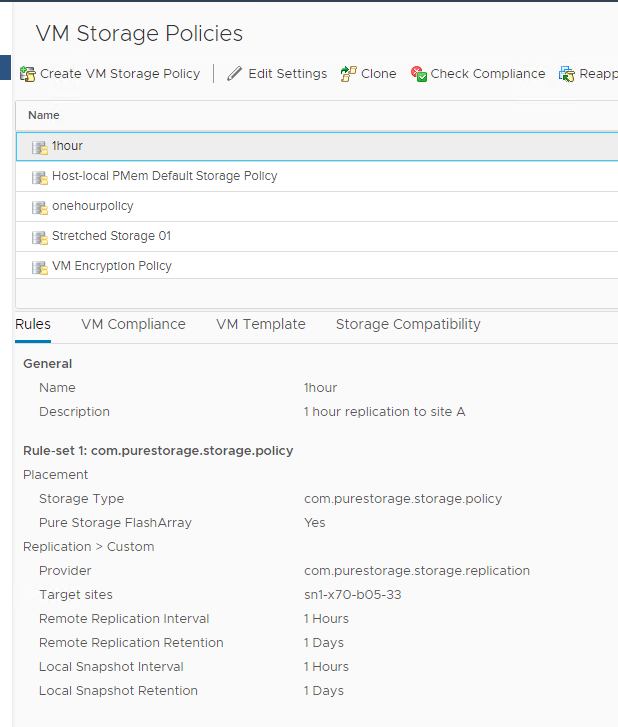
So let’s assign that. I will get that policy via PowerCLI.

I can then use the cmdlet set-spbmentityconfiguration to assign the policy.
<your VMs> |Set-SpbmEntityConfiguration -StoragePolicy <target policy> -ReplicationGroup <replication group> 
We can see the policy is now set and the VM is compliant! Since the VMs are already in the protection group, VASA doesn’t actually have to do anything to the VMs, but now VMware *knows* that they are protected. And can now fail them back etc.
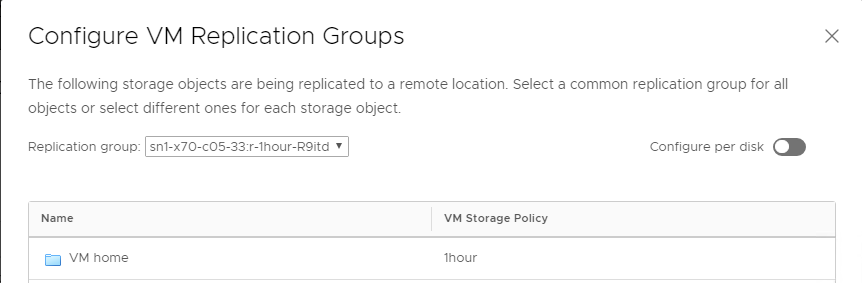
Putting it all together
So my full script is below. I plan on making this much more reuseable and adding it to my PowerShell module. Which will streamline this a bit more.
$sourcePolicyName = "<source policy name>"
$targetPolicyName = "<target policy name>"
$resourcePoolName = "<resource pool name>"
$sourcevCenter= "<source vCenter FQDN/IP>"
$targetvCenter = "<target vCenter FQDN/IP>"
$folderName = "<folder name>"
connect-viserver -Server $sourcevCenter
connect-viserver -Server $targetvCenter
$policy = Get-SpbmStoragePolicy -Name $sourcePolicyName -server $sourcevCenter
$sourceGroup = $policy |Get-SpbmReplicationGroup
$repPairs = Get-SpbmReplicationPair -Source $sourceGroup
$targetGroup = $repPairs.Target
start-spbmreplicationpreparefailover -ReplicationGroup $sourceGroup
$vms = start-spbmreplicationfailover -replicationgroup $targetGroup -Confirm:$false
$registeredVms = @()
foreach ($testVm in $vms)
{
$registeredVms += New-VM -VMFilePath $testVm -ResourcePool $resourcePoolName -Location $folderName
}
foreach ($registeredVm in $registeredVms)
{
try
{
$registeredVm |Start-VM -ErrorAction Stop
}
catch [VMware.VimAutomation.ViCore.Types.V1.ErrorHandling.VMBlockedByQuestionException]
{
$registeredVm | Get-VMQuestion |Set-VMQuestion –DefaultOption -Confirm:$false
}
}
$targetPolicy = Get-SpbmStoragePolicy -Name $targetPolicyName -Server $targetvCenter
$newSourceGroup = Start-SpbmReplicationReverse -ReplicationGroup $targetGroup
$registeredVms | Set-SpbmEntityConfiguration -StoragePolicy $targetPolicy -ReplicationGroup $newSourceGroup
Hello Cody,
Thanks for all this procedure.
What is the plan in case of real disaster recovery failover ?
Thank you !
Nicolas
You’re welcome! Pretty similar just skips the source side stuff. I’ll work on a post on this. Hopefully can get it written soon
After spending a lot of time to resolve various issues, I have completed the replication testing successfully. Below is what, I have noticed during the testing.
After failing over the VM to the target site, the volumes group name of the VM shows up as “Config” under the new production group.
Example:
vvol-Config-f6d7e7fa-aec6f522-vg/Config-f6d7e7fa
vvol-Config-f6d7e7fa-aec6f522-vg/Data-921f6142
vvol-Config-f6d7e7fa-aec6f522-vg/Data-c5a264ab
I was expecting the VM name in the place of the “Config” string. Is it working as expected?
Purity 5.3.4
vSphere 6.7 U3
Also, i have noticed that the snapshot schedule is enabled on the newly created production group on the target array after the failover.
Source Array: array1
pg-vvol-rep – Snapshot schedule is Off and Replication schedule is On
Target Array: array2
array1:pg-vvol-rep – Snapshot schedule is Off and Replication schedule is On
Target Array: array2
r-pg-vvol-rep-R16w8 – The new production group is getting created at that time of the failover process and this group is enabled with both snapshot and replication schedule. Also, this group is getting replicated automatically to source array for reverse replication.
We have done a tremendous amount of rework in our replication handling in the upcoming release. How this all was handled has been changed/improved too. In preparation for SRM support we basically spent the past 8 months digging into every piece of this. With the exceptions to syncReplicationGroup and prepareFailover there weren’t architectural changes though
That’s awesome ! Thanks.
As you have explained the replication behavior in Part VII, I am planning to use below flow to synchronize the production group using both VMware and Pure method. Preparefailover might not suit for our requirement because the VM’s will be online. So i presume the below flow works for Unplanned failover , Test failover and Planned failover (VM’s online).
# VMware way of sync’ing the PG
Sync-SpbmReplicationGroup -ReplicationGroup $targetGroup -PointInTimeRelicaName “Current” -RunAsync
# Pure way of sync’ing the PG
$flasharray = New-PfaArray -EndPoint $sourceArray -Credentials (get-credential) -IgnoreCertificateError
$sourceGroup = (Get-SpbmReplicationPair -Target $targetGroup).source
$pGroup = ($sourceGroup.name.split(“:”)[1])
New-PfaProtectionGroupSnapshot -Protectiongroupname $pGroup -Array $flasharray -Suffix vVolSync -ReplicateNow -ApplyRetention
Please advise.
This is a bug we fixed it in our upcoming VASA release which will likely be 5.3.6
Thanks Cody ! Good to know.
I have tested all three failover scenarios (planned, unplanned and test) successfully. Please share your insight details to run the unplanned failover. As we don’t have many details out there to test the unplanned failover, looking for your help to ensure I am using the right set of commands.
Also, as we deploy the VM only in the primary site, what is the best way to reserve the resources in the secondary site which is not dedicated only for DR purpose.
hi Cody, i have a sample scripts for planned failover, however i couldn’t find any document scripts to do failback. Would you able to assist please? Thank you.
FYI system is running vvols. Storage is 3par/primera.
ahpek, so doing a fail back would essentially be the exact same way but starting from the reverse order. I did a vVol replication deep dive a while ago and outlined the PowerCLI workflows to do the failover and reverse: https://support.purestorage.com/Solutions/VMware_Platform_Guide/User_Guides_for_VMware_Solutions/Virtual_Volumes_User_Guide/vVols_Deep_Dive%3A_Array_Based_Replication_with_vVols#vVols_Replication_PowerCLI_Commands
The key part is getting that reverse storage policy and replication group assigned. So now if you start back at the beginning, you do the same workflow but finding the VMs on the other vCenter.
You’ll probably want to have already removed or deleted the original source VMs from the original source vCenter. That way you don’t run into any issues with duplicate VM names or anything.